

巴比特 | 元宇宙每日必读
作者 | OpenAI&TheVerge&Techcrunch
翻译 &分析| 阿法兔
*本文6000字左右
官宣文档
OpenAI已经正式推出GPT-4,这也是OpenAI在扩大深度学习方面的最新里程碑。GPT-4是大型的多模态模型(能够接受图像和文本类型的输入,给出文本输出),尽管GPT-4在许多现实世界的场景中能力不如人类,但它可以在各种专业和学术基准上,表现出近似人类水平的性能。
例如:GPT-4通过了模拟的律师考试,分数约为全部应试者的前10%。而相比之下,GPT-3.5的分数大约是后10%。我们团队花了6个月的时间,利用我对抗性测试项目以及基于ChatGPT的相关经验,反复对GPT-4进行调整。结果是,GPT-4在事实性(factuality)、可引导性(steerability)和拒绝超范围解答(非合规)问题( refusing to go outside of guardrails.)方面取得了有史以来最好的结果(尽管它还不够完美)
在过去两年里,我们重构了整个深度学习堆栈,并与Azure合作,为工作负荷从头开始,共同设计了一台超级计算机。一年前,OpenAI训练了GPT-3.5,作为整个系统的首次 "试运行",具体来说,我们发现并修复了一些错误,并改进了之前的理论基础。因此,我们的GPT-4训练、运行(自信地说:至少对我们来说是这样!)空前稳定,成为我们首个训练性能可以进行提前准确预测的大模型。随着我们继续专注于可靠扩展,中级目标是磨方法,以帮助OpenAI能够持续提前预测未来,并且为未来做好准备,我们认为这一点,对安全至关重要。
我们正在通过ChatGPT和API(您可以加入WaitList)发布GPT-4的文本输入功能,为了能够更大范围地提供图像输入功能,我们正在与合作伙伴紧密合作,以形成一个不错的开端。我们计划开源OpenAI Evals,也是我们自动评估AI模型性能的框架,任何人都可以提出我们模型中的不足之处,以帮助它的进一步的改进。
能力
在简单闲聊时,也许不太好发现GPT-3.5和GPT-4之间的区别。但是,当任务的复杂性达到足够的阈值时,它们的区别就出来了。具体来说,GPT-4比GPT-3.5更可靠,更有创造力,能够处理更细微的指令。
为了理解这两个模型之间的差异,我们在各种不同的基准上进行了测试,包括模拟最开始那些为人类设计的考试。通过使用最新的公开测试(就奥数和AP等等考试)还包括购买2022-2023年版的练习考试来进行,我们没有为这类考试给模型做专门的培训,当然,考试中存在很少的问题是模型在训练过程中存在的,但我们认为下列结果是有代表性的。
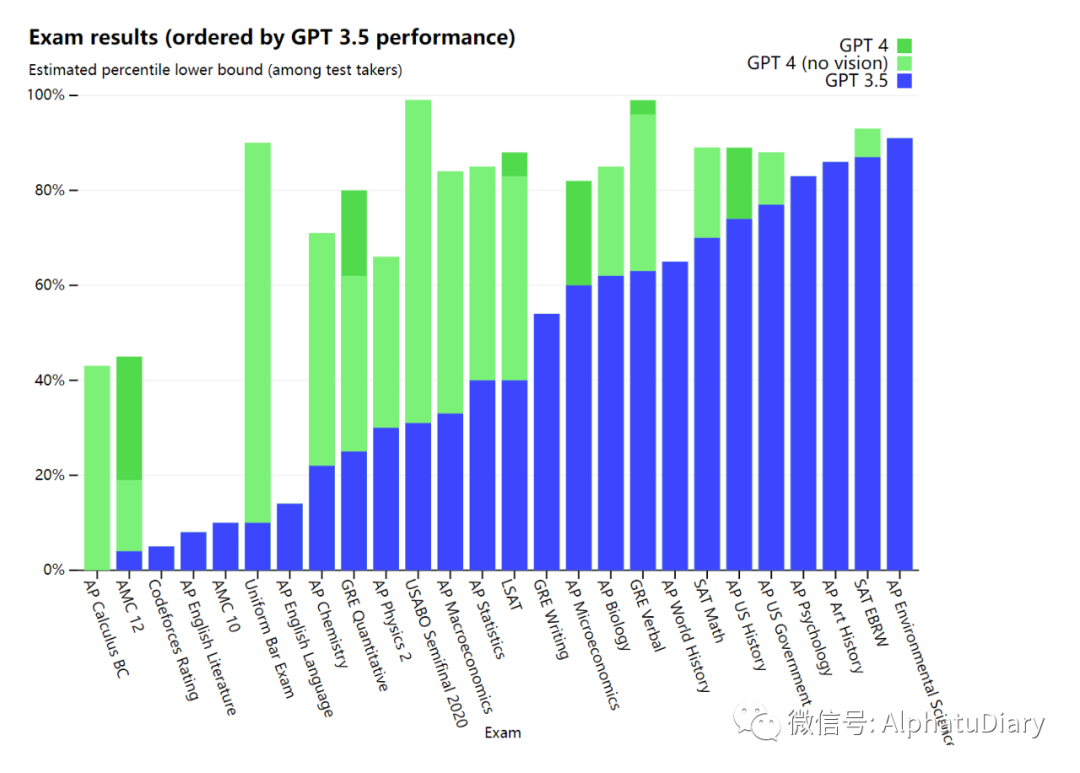
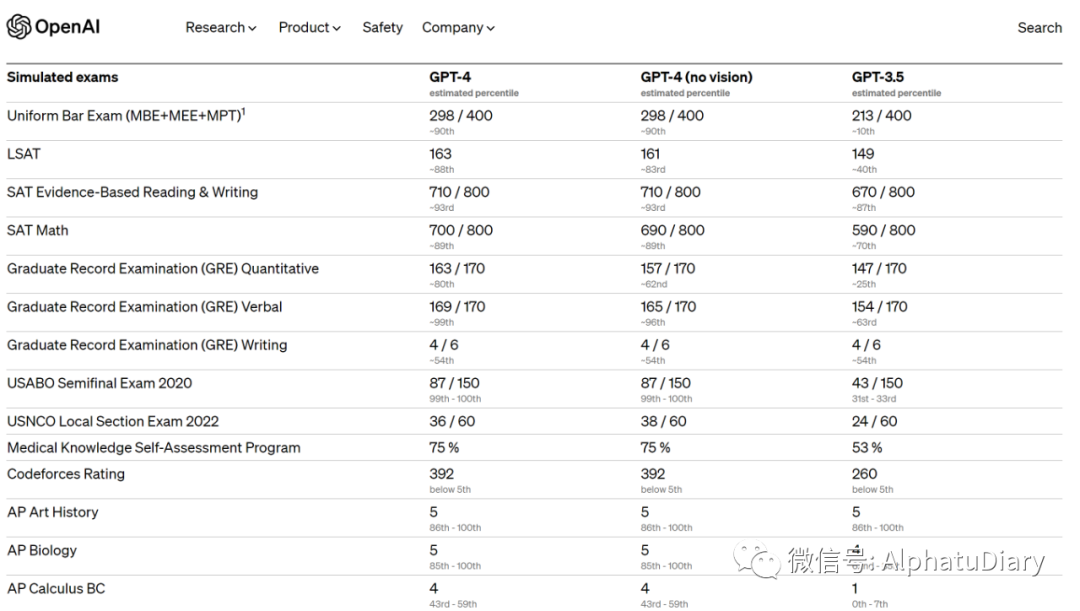
我们还在为机器学习模型设计的传统基准上,对GPT-4进行了评估。GPT-4大大超过现有的大语言模型,与多数最先进的(SOTA)模型并驾齐驱,这些模型包括针对基准的制作或额外的训练协议。
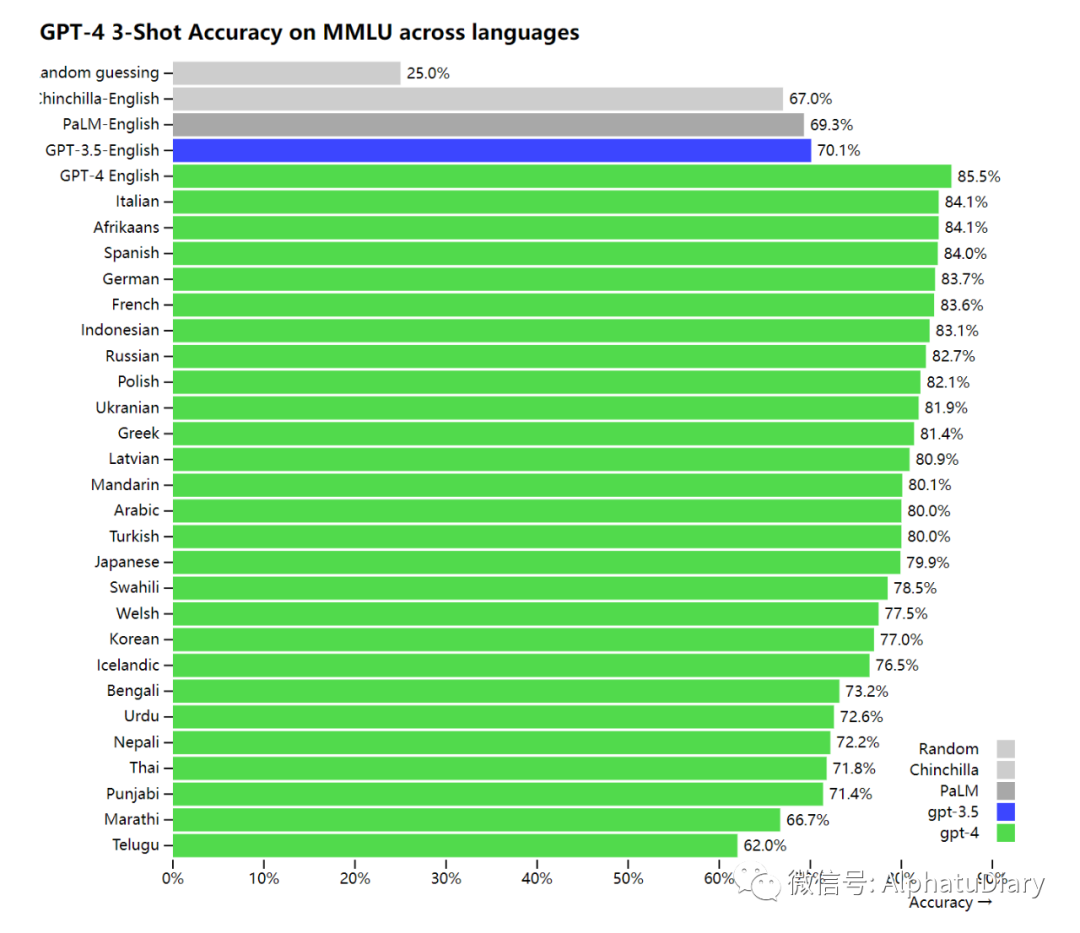
由于现有的大多数ML基准是用英语编写的,为了初步了解其他语言的能力,我们使用Azure Translate将MMLU基准:一套涵盖57个主题的14000个选择题,翻译成了各种语言。在测试的26种语言中的24种语言中,GPT-4的表现优于GPT-3.5和其他大模型(Chinchilla,PaLM)的英语表现,这种优秀表现还包括类似拉脱维亚语、威尔士语和斯瓦希里语等等。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

