

CG艺术大佬向AI下“战书”
来源:42章经
作者:曲凯
“壁垒是啥?”
“差异化是啥?”
“大模型自己做了怎么办?”
“为啥你能做别人不能做?”
我们从 2 月开始到现在,接了 10 个左右 AI 的应用层项目做 FA,每个项目到最后都会反复遇到这些问题。
这几个问题几乎是振聋发聩,掩耳盗铃,余音绕梁,三日不绝。
所以如果你是一个最近刚开始看 AI 应用的投资人,我有个办法可以节省你一个月左右的时间:
只要遇到项目就直接问壁垒是啥,项目方如果说不上来,就直接 move on,反正聊到最后也要回头纠结这个问题,不如五分钟结束战斗,这样也能节省创业者更多的时间。
然后呢,你就可以得出和花了很多时间聊了很多项目的投资同行们几乎一样的结论:
“这些项目好像都没啥壁垒,很难出手啊。。”
当然,以上只是一个小小的吐槽,just kidding...
实际情况是,大多机构在过去两个月中核心精力都放在了大模型上,造成了国内大模型项目数量和融资火热的景象,然后最近两周大家开始看应用层的项目(中间层在国内更惨,似乎直接被忽略跳过了,默认没有机会?),于是就来到了我上面讲的情况。
我们的 10 个项目中,目前确定成交的有三个,在路上的希望很高的大概有三四个,很难的有三四个,大概是这个比例。而我还是有信心说我们聊过的在做的项目在市场上是有一定的代表性和水准的,对接的机构也是最主流在看这个方向的。所以,整体市场真正能拿到融资的应用层的项目比例要远小于此。
从我们了解到的数据来看,在 AI 领域出手最多的机构大概有两三家,每家大概投四五个项目(其中也以模型类为主),其他真正出手投过一两个项目的大概有 20 家机构左右,所以真正的 AI 应用层项目能拿到融资的其实很少,至少和目前整体市场的热度及共识是完全不匹配的。
那造成这个情况的原因都有哪些?创业者该如何应对?到底这个赛道的壁垒是什么呢?以下是我们近期思考的结论:
一)大模型的能力和意义被显著高估了
Maithra Raghu 在谷歌大脑工作了八年,我很同意她最近的一篇文章(Does One Large Model Rule Them All)中关于大模型未来的观点。
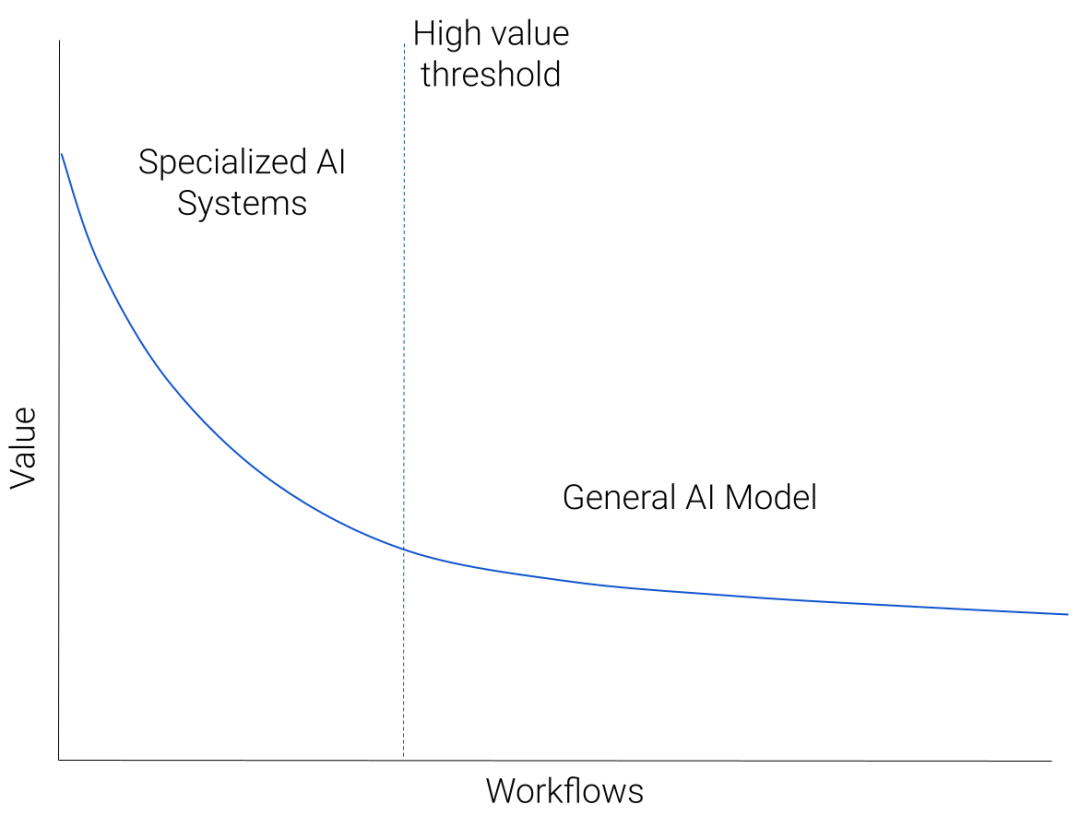
如上图,她的观点是会有几个普适的通用大模型,去满足广义的中长尾的大众需求,而在垂直的高价值大用户基数的场景下(比如图像生成、营销文案协作、编程助手等场景),会有很多专业模型,这些模型更像是端到端的应用,会占据用户场景,并建立自己的模型。
她的论证逻辑也非常简单:
1)专业化领域的用户对产品性能的要求高,需要更好的定制化的产品和技术的解决方案,直接调用通用大模型是难以满足的。
2)要把产品做到更好,需要更完善和灵活的数据反馈和底层架构,而通用大模型在可控性上是难以做到的。
3)垂直场景的产品的护城河就是数据,最珍贵的也是数据,所以一旦有了场景和用户,这些产品提供者有足够强的动力去保护自己的数据不被其他大模型调用,所以自己基于类开源的大模型去训练自己的模型就几乎成为了必然的选择。
4)AI 领域本身就是有非常强的协同性和开源性的,而且各项成本也是在不断降低的,所以未来做自己的大模型的门槛会不断降低。
所以基于以上原因,她的结论是未来可能会有非常多的大模型,有少数通用的,有更多垂直的,整个生态会无比繁荣,会有更多的端到端应用的机会,而非通用大模型本身。
我猜这也是为什么美国不断有大额的应用层公司融资的新闻,而很少见到类似国内的一窝蜂去投大模型创业公司的新闻(美国的大模型公司似乎也都是端到端应用的公司,都是直接有产品和场景,大模型只是为了更好的满足产品)。
其实我相信国内的大模型公司有很多也是追求场景和产品,而非只讲通用大模型故事的,所以其实核心问题是这些公司到底该被称为大模型公司还是应用公司呢?如果其实最终是端到端的应用公司那又该如何评估这些公司的核心竞争力呢?
另外,今天我和一个创业朋友聊天,他提到一个很有趣的问题,GPT3 其实是 2020 年发布的,在那个之后的两年之中,为什么只有很少的大模型或者应用类的公司跑出来?难道 3.5 和 3 的差距有那么大吗?那为什么 Jasper 或 Copy.ai 却跑出来了呢?
我相信这也是一个值得很多从业者去思考的问题。
二)未来应用的发展轨迹到底会如何?
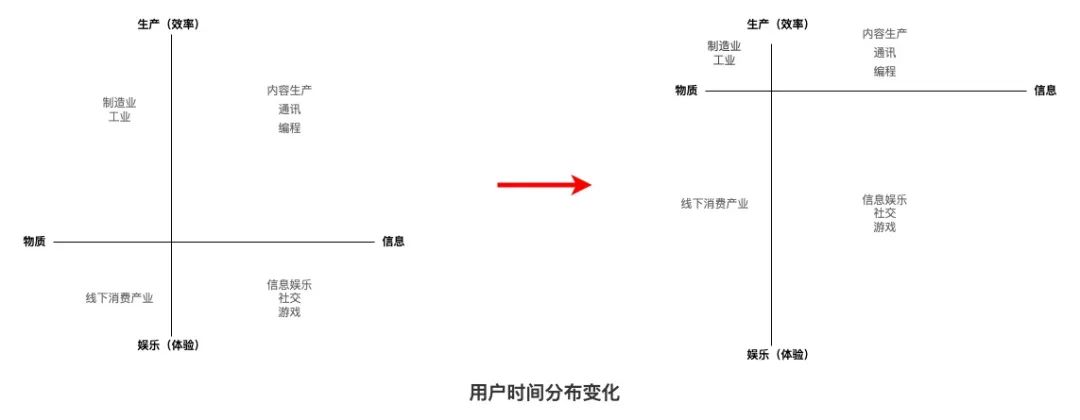
上图是音遇创始人 Albert 对于未来用户时间分布变化的思考。
在上一波移动互联网的市场中,我们会发现不论是什么赛道,最终从用户时间的维度上大家都是竞争者。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

