

CG艺术大佬向AI下“战书”
撰文:Minqi Jiang,FAIR 及 Meta AI 研究员
来源:The Gradient

图片来源:由无界 AI工具生成
我们正处于从“从数据中学习”过渡到“从什么数据中学习”作为人工智能研究中心的边缘。最先进的深度学习模型,如 GPT-[X] 和 Stable Diffusion,被描述为数据海绵 [1] 能够对大量的数据[2,3]进行建模。这些大型生成模型,许多是基于变换器架构的,可以对大量的数据集进行建模,学习生成图像、视频、音频、代码和许多其他领域的数据,其质量开始与人类专家撰写的样本相媲美。越来越多的证据表明,这种大模型的通用性受到训练数据质量的极大限制。尽管训练数据对模型的性能有很大的影响,但主流的训练方法在本质上并不是寻求数据。相反,它们忽略了训练数据中的信息质量,而倾向于最大化数据数量。这种差异暗示着研究趋势可能会转向更加关注数据的收集和生成,以此作为提高模型性能的主要手段。
从本质上讲,为模型收集信息数据的问题是探索——学习的一个普遍方面。在像现实世界这样的开放式领域中,感兴趣的可能任务集实际上是无限的,探索对于收集最适合学习新任务和提高已经学习的性能的额外数据至关重要。这种开放式学习可能是机器学习(ML)系统最重要的问题设置,因为部署它们的现实世界正是这样一个开放式领域。在正确的时间主动获取正确的训练数据是智能的一个关键方面,它可以让学习更有效地进步——换句话说,它可以“先学走,再学跑”。那么,为什么在最近关于训练更通用模型的讨论中,探索的概念在很大程度上被忽略了呢?
造成这种疏忽的一个原因可能是,在强化学习(RL)和监督学习(SL)中通常研究的探索 -- 作为主动学习的某种变体出现 -- 主要是以静态的、预定义的数据集或模拟器来设计的。正如 SL 的研究主要集中在优化像 ImageNet 这样的静态基准上的性能,RL 主要集中在任务的静态模拟器的设置上。这种对静态基准的关注使得现有的探索概念不适合在像现实世界这样的开放式领域中学习,在那里,相关的任务集是无限的,不能被建模为一个静态的、预定义的数据发生器。
在最近的一份立论中,我和我的合著者 Tim Rocktäschel 和 Edward Grefenstette 讨论了广义探索的想法。广义探索不是把探索限制在可以从预定的模拟器或静态数据集中取样的数据上,而是寻求在所有可能的训练数据空间中探索那些对提高学习代理的能力最有用的样本。例如,在 RL 的情况下,这需要搜索可能的训练环境空间,而在 SL 的情况下,需要搜索数据空间的表达式参数化,例如数据空间的生成模型的潜在空间。这种关于探索的更普遍的观点连接了 SL 和 RL 之间的探索概念。重要的是,它还描述了如何将探索应用于完全开放的领域,其中探索作为关键的数据收集过程,用于对越来越广泛的能力的开放式学习。
这种开放式的探索过程有望成为推动更通用的智能模型进展的一个关键组成部分。随着大规模的模型训练继续利用越来越大的数据集的好处,研究人员预测,最快到 2025 年,训练数据集的增长速度可能很快超过网络上高质量数据的有机增长速度。此外,更大的数据集需要更昂贵的计算来进行训练。最近的研究表明,只对最高质量的数据进行集中训练可以使学习效率大幅提高,从而以极低的计算成本获得更准确的模型。这样的工业数据动态表明,开放式的探索过程,使学习系统能够自主地收集或生成新的训练数据,有望在 ML 研究中发挥重要作用。在接下来的几年里,大量的研究投资可能会从模型设计和优化转移到探索目标和数据生成过程的设计上。本文中讨论的许多最近的研究计划清楚地表明,这种转变已在进行中。
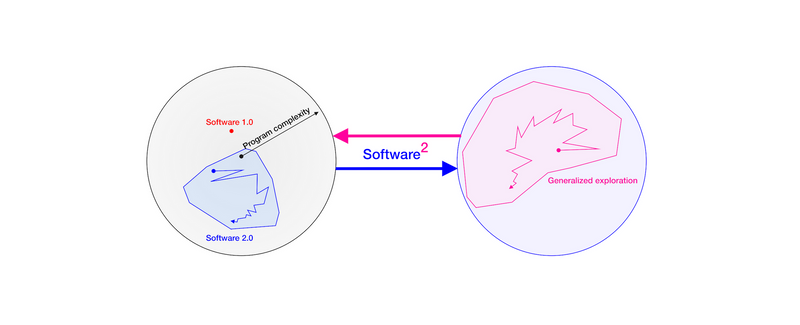
ML 系统生成自己的训练任务(以及由此产生的数据)的高级概念并不新鲜。这个概念在不同程度上被 Schmidhuber 描述为“人工好奇心”,被 Clune 描述为“生成 AI 的 AI”。在这里,我们试图激励这样一个观点:现在是这些概念在实际的、真实世界的 ML 系统中获得牵引力的关键时刻。
如果深度学习可以被描述为“Software 2.0”-- 根据输入/输出对的例子进行自我编程的软件 -- 那么这种有望以数据为中心的范式,即软件通过搜索自己的训练数据有效地改进自己,可以被描述为一种“Software²”。这种范式继承了 Software 2.0 的优点,同时改进了其核心的、受数据约束的弱点:深度学习(Software 2.0)要求程序员为每个新任务手动提供训练数据,而 Software² 则将数据重塑为软件,对世界进行搜索和建模,以产生其自己的、可能是无限的训练任务和数据。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

