

巴比特 | 元宇宙每日必读
来源:《科创板日报》
记者 张洋洋

图片来源:由无界 AI工具生成
“根据现在的反馈,任务性能测试上,包括ChatGPT在内,没有一个大模型能够全部达标。”这基本上是业内对雨后春笋般不断涌现的人工智能大模型的共识。
ChatGPT推出后,基于大语言模型技术的同类型产品还在加快涌现。进入4月以来,从互联网大厂,到A股上市公司,以及一众创业公司,再加上高校科研院校,都先后发布各自的大模型,总数已经超过30家。
短短数月,多个模型竞相涌现,各家模型实力究竟如何?国内大模型是否过剩了?行业终局,究竟是百花齐放,还是赢家通吃?在这场技术变革的讨论声中,大模型带来的新能力里,哪些是最为关键的,最有可能带来长期影响的?
AI大模型如雨后春笋 任务性能测试还未有“满分答卷”
据民生证券的统计,国内已有超30个大模型亮相,行业俨然一副“百模大战”的场景。
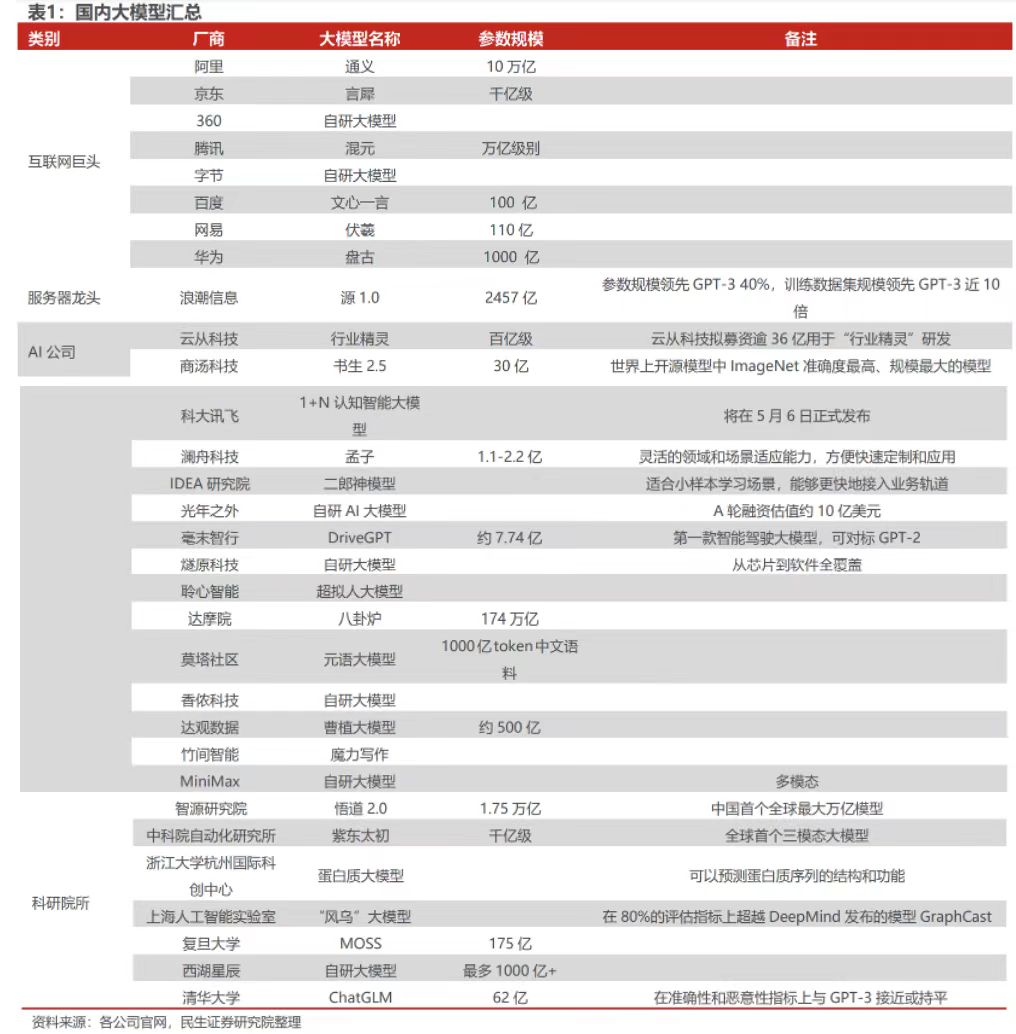
根据《科创板日报》记者约访的人工智能行业人士反馈来看,业内目前还没有就具体模型给出直接的评判定论,但他们提供了一些维度,供外界做参考。
思必驰联合创始人兼首席科学家、上海交通大学教授俞凯在接受《科创板日报》记者采访时表示,一个必须要承认的事实是,现在的大模型,只有ChatGPT通过了通用性测试(用户破亿),国内大模型与之对比,均还存在差距。
俞凯告诉记者,衡量一个大模型实力,第一是可以基于任务的性能测试,即通过定义任务集的方式,去比较所有大模型在每个任务上面的完成度。这种性能测试与人类能力对齐,包括理解能力、推理能力、判断能力等。根据现在的反馈,任务性能测试上,包括ChatGPT在内,没有一个大模型能够全部达标。
第二,从安全性角度去判断,这一点更多的体现为大模型与人类价值观的耦合程度。
第三,是模型运行角度,从工程特性去判断。“这是一个特别重要的能力。”俞凯强调,如该大模型能够接收多大的文本、回答反应的速度、运行的性能等。
俞凯所言,侧重于技术指标。当然,也有从资源禀赋层面作出判断的。
大模型领域资深行业人士王钧(化名)则告诉记者,做大模型对团队要求非常高,资金、技术、工程、产品、商业化等多个方面都不能有短板,最终考验的是:核心成员对大方向、大节奏有没有真正想清楚,能不能获取足够多的资源和支持,能否吸引各方面的关键人才加盟,吸引了一群不同背景的牛人之后,能不能磨合好。
“其中最稀缺的是核心算法研究和平台工程的技术人才,这方面整个华人圈子人数都不多。”王钧强调。
人才之争,这在大模型市场的起势阶段已有十分鲜明的写照。
“先发制人”的百度,派出的掌舵者是CTO王海峰,创业者团队中,澜舟科技的周明,衔远科技的周伯文等,他们在人工智能行业的影响力已经无需多言。此前,高调官宣人工智能创业的王慧文,入局的第一步就是在其个人社交媒体平台发英雄帖,重金(新公司75%的股份)招聘顶级研发人才。
“判断做得好不好的标准,不能看各公司自己的宣传,一些业界公认的评测基准当然也可以作为参考,但最重要的还是用户的认可,用户尤其是高频或者付费用户最多的才是最好的。”王钧称。
逼近了AGI核心 产业应用“泛化性”才是关键
囿于各种商业原因,对于各公司大模型实际的数据、测试反馈指标、投入的资源情况,乃至用户数据等,外界很难全然知晓,那么对其实力情况,也很难去做全然科学的判断。
但记者注意到,受访者们均提到了一个显性的评测角度,那就是“用户反馈”,如回答的反应速度、准确性、可用性、上下文连贯逻辑等。这也是为何,每逢一个大模型新品推出,用户第一时间会去关注回答是否会“翻车”。
就国内当下几个代表性大模型,《科创板日报》记者此前均有过实际体验,结合多位用户的使用反馈,目前大模型整体呈现如下特征:
ChatGPT-4是一个多模态大型语言模型,支持图像和文本输入,以文本形式输出,在“模拟人类”的文本输出方面,以及用户规模上,综合实力领先。
相比之下,国内大模型种类多样,能力各有千秋,目前更注重探索产业应用,用于解决产业技术壁垒问题。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

