

ChatGPT长出狗身子!波士顿
来源:新智元
【导读】开源先锋StabilityAI一天扔了两枚重磅炸弹:发布史上首个开源RLHF大语言模型,以及像素级图像模型DeepFloyd IF。开源社区狂喜!
最近,大名鼎鼎的Stable Diffusion背后的公司,一连整了两个大活。
首先,Stability AI重磅发布了世上首个基于RLHF的开源LLM聊天机器人——StableVicuna。

StableVicuna基于Vicuna-13B模型实现,是第一个使用人类反馈训练的大规模开源聊天机器人。
有网友经过实测后表示,StableVicuna就是目前当之无愧的13B LLM之王!
对此,1x exited创始人表示,这可以看作是自ChatGPT推出以来的第二个里程碑。
另外,Stability AI 发布了开源模型DeepFloyd IF,这个文本到图像的级联像素扩散模型功能超强,可以巧妙地把文本集成到图像中。
这个模型的革命性意义在于,它一连解决了文生图领域的两大难题:正确生成文字,正确理解空间关系!
秉持着开源的一贯传统,DeepFloyd IF在以后会完全开源。
Stailibity AI,果然是开源界当之无愧的扛把子。

StableVicuna
世上首个开源RLHF LLM聊天机器人StableVicuna,由Stability AI震撼发布!

一位Youtube主播对Stable Vicuna进行了实测,Stable Vicuna在每一次测试中,都击败了前任王者Vicuna。

所以这位Youtuber激动地喊出:Stable Vicuna就是目前最强大的 13B LLM模型,是当之无愧的LLM模型之王!


StableVicuna基于小羊驼Vicuna-13B模型实现, 是Vicuna-13B的进一步指令微调和RLHF训练的版本。
而Vicuna-13B是LLaMA-13B的一个指令微调模型。

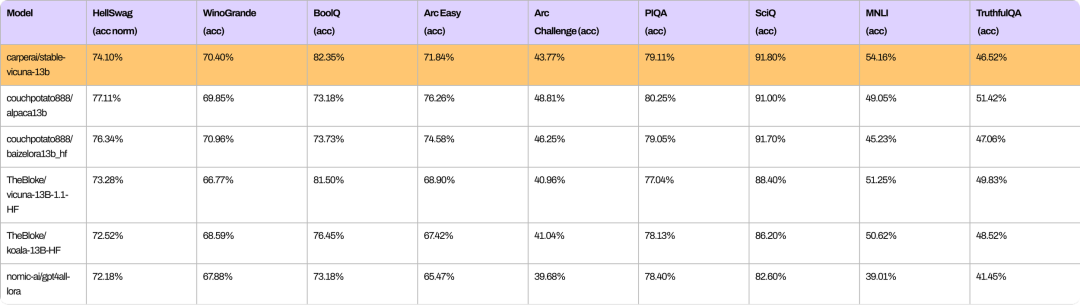
从以下基准测试可以看出,StableVicuna与类似规模的开源聊天机器人在整体性能上的比较。
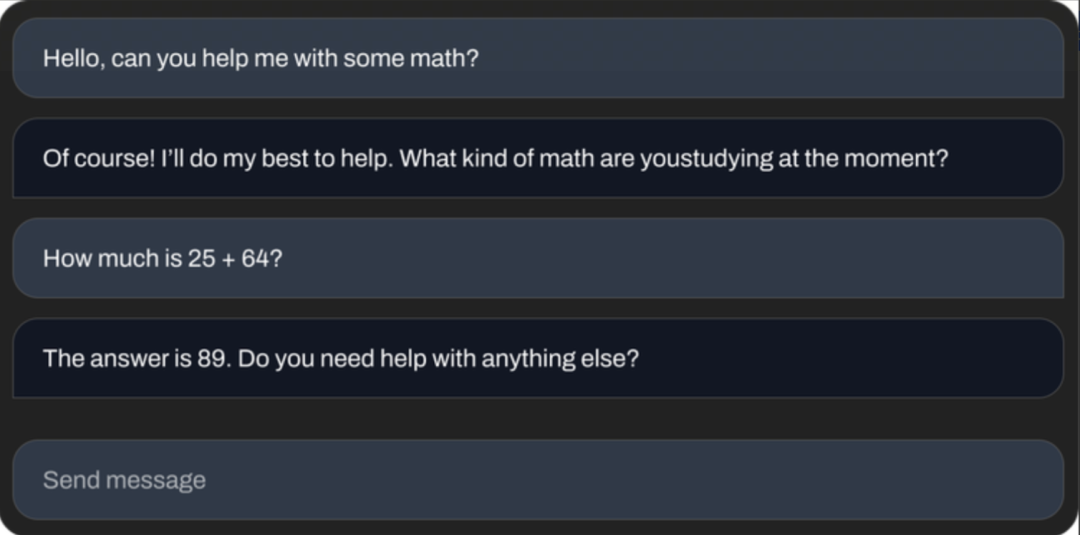
StableVicuna可以做基础数学题。
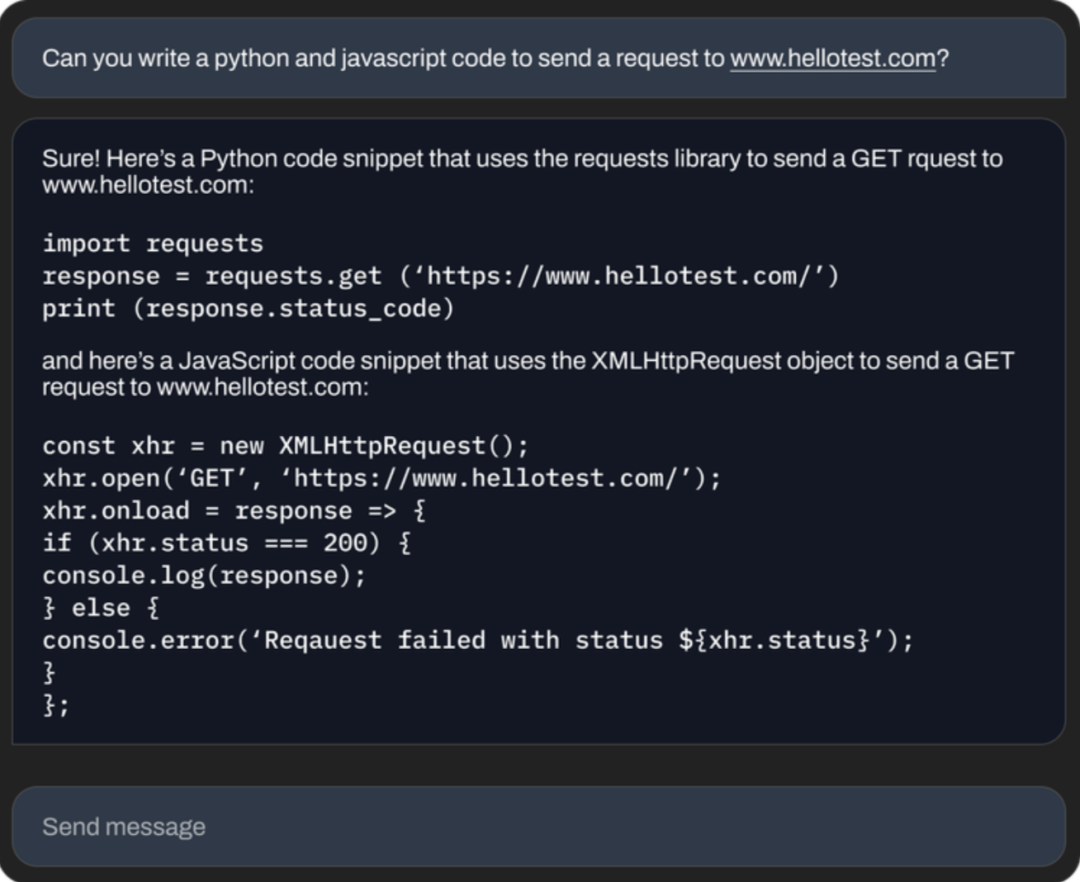
可以写代码。
还能为你讲解语法知识。
开源聊天机器人平替狂潮
Stability AI想做这样一个开源的聊天机器人,当然也是受了此前LLaMa权重泄露引爆的ChatGPT平替狂潮的影响。
从去年春天Character.ai的聊天机器人,到后来的ChatGPT和Bard, 都引发了大家对开源平替的强烈兴趣。
这些聊天模型的成功,基本都归功于这两种训练范式:指令微调和人类反馈强化学习 (RLHF)。

这期间,开发者一直在努力构建开源框架帮助训练这些模型,比如trlX、trl、DeepSpeed Chat和ColossalAI等,然而,却并没有一个开源模型,能够同时应用指令微调和RLHF。
大多数模型都是在没有RLHF的情况下进行指令微调的,因为这个过程十分复杂。
最近,Open Assistant、Anthropic 和 Stanford都开始向公众提供RLHF数据集。
Stability AI把这些数据集与trlX提供的RLHF相结合,就得到了史上第一个大规模指令微调和RLHF模型——StableVicuna。
训练过程
为了实现StableVicuna的强大性能,研究者利用Vicuna作为基础模型,并遵循了一种典型的三级RLHF管线。
Vicuna在130亿参数LLaMA模型的基础上,使用Alpaca进行调整后得到的。

他们混合了三个数据集,训练出具有监督微调 (SFT) 的Vicuna基础模型:
研究者使用trlx,训练了一个奖励模型。在以下这些RLHF偏好数据集上,研究者得到了SFT模型,这是奖励模型的基础。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

