

第一批读人工智能的「双
原创:王呜
来源:大模型之家

图片来源:由无界 AI工具生成
人工智能(AI)作为当今科技领域最受关注的话题之一,其中自然语言处理(NLP)的技术演进和应用一直是最热门的赛道。然而,在AI演进的过程中,英语作为世界通用语言,占据了这个领域优势地位。
就如同GPT3,英文占比为92.7%、法语1.8%、德语1.5%而中文语料只占0.1%。这意味着,英文之外的语料匮乏,会导致使用这些语种的国家在发展AI大模型的过程中遭遇更多阻力。
香港科技大学人工智能研究中心主任冯雁表示:尽管自己掌握着七门语言,但英语在学术界的地位是没有其他语言可以撼动的,尤其在人工智能领域,如果不用英文发表论文将很难获得学术界的认同。
语言差异成为人工智能开发和应用的本质挑战
今年5月,谷歌发布了PaLM 2大语言模型,谷歌宣称,PaLM 2为100多种语言增加了非英语训练数据。该模型可以识别德语和斯瓦希里语中的成语、日语中的笑话以及印度尼西亚语中的语法,并且比以前的模型更好地识别区域变化。
不过在应用推广阶段,谷歌并没能兑现发布会上的承诺,用户发现,谷歌仍在限制普通用户使用PaLM 2的场景。例如旗下的聊天工具Bard,虽然获得了PaLM 2的支持,但仅开放了英语、日语和韩语三种语言的使用,而Gmail的写作助手更是仅支持英语。
可见,无论从开发,还是到落地,英语在人工智能赛道中,始终有着最高的优先级。业内专家表示,尤其是中文这样采用非拉丁语系的语言,英语进行人工智能的开发和应用会因文化和语言差异而出现更多的歧义或误解,进而导致人工智能技术的可靠性和准确性下降。其次,由于缺乏适合中文等非英语语言的开发平台也对于国内的人工智能开发产生了阻碍。
从现实角度出发,摒弃传统编程方式对于任何一个非英语国家都是不现实的,所需投入的研发成本、教育成本以及时间成本都是难以估量的。
然而,随着大模型成为了推动新一代产业革命的重要基石已经成为行业共识,大模型的开发和应用也面临着巨大的挑战,如技术壁垒、数据安全、伦理道德等。
因此,中国发展大模型是形势所需,既要把握机遇,又要防范风险。一方面,中国需要加强自主创新,掌握核心技术,避免被外部势力卡脖子,提升国家的竞争力和影响力。另一方面,中国需要建立健全的数据治理体系,保护国家和个人的数据安全,防止数据泄露、滥用、歧视等问题,促进数据的合理利用和共享。
其中,我们看到了一些国内企业,正在根据中国独特的语言环境与市场需求,试水更加符合国内需求的大模型产品。
今年3月,在文心一言大模型发布会上,百度创始人、董事长兼CEO李彦宏就曾强调,文心一言基于海量网页数据、搜索数据和图片数据以及语音日均调用数据,以及5500亿事实的知识图谱的训练数,这让百度在“中文语言”的处理上,能够处于独一无二的位置。
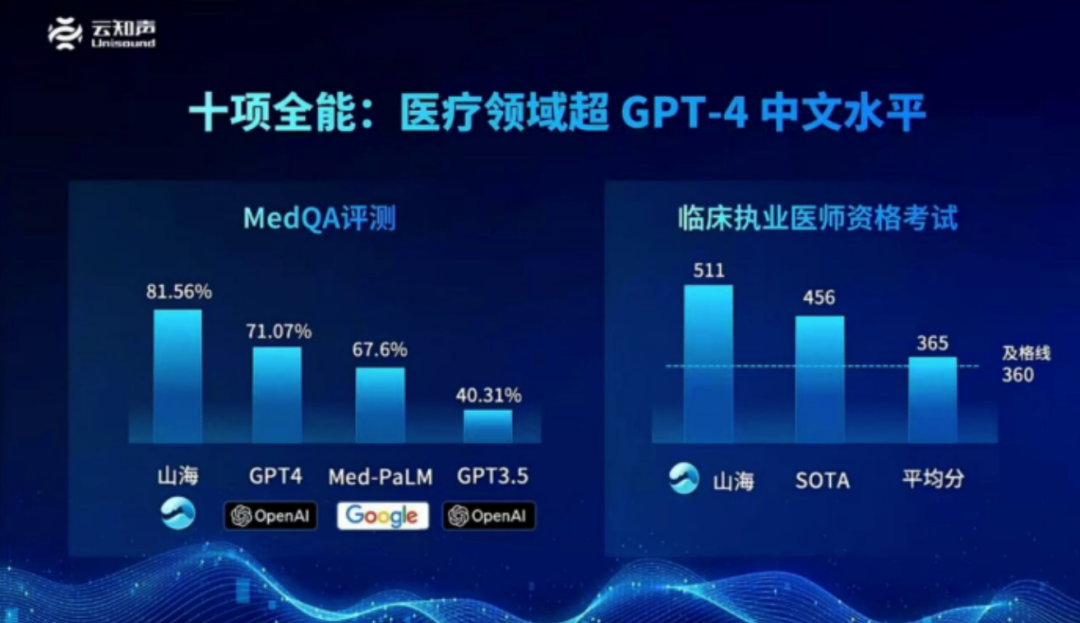
上个月,云知声发布的山海大模型展示了中国大模型针对医疗领域的优势,云知声不仅使用了领域内专业数据,还加入了大量专辑、病案、教材以及云知声积累的标准医疗数据,并建立了国内最大的医疗知识数据图谱,通过医疗领域的知识增强,从而实现了在MedQA评测能力中超越GPT-4的结果。
除此之外,阿里巴巴、腾讯、商汤科技、科大讯飞等也在各自的AI大模型中,结合自身的优势研究和应用场景数据,展现出了巨大的潜力和发展空间。
大模型之家认为,企业可以在自身人工智能业务中,也应当注重开发面向非英语语种的产品和服务,以适应更广阔的市场,以及针对不同使用场景有的放矢地开发产品。
同时,在政策方面,也希望能够提供针对中文的语言环境,提供更多相应的研究和发展政策支持,鼓励更多的人工智能创新项目。除此之外,学术研究机构也可以加强中文人工智能领域的研究,在保证数据安全与隐私的前提下,共享更多相关数据资源。
文化差异将成为大模型本土发展的先进动力
语言作为国家文化的血脉,不同的语言和文化背景往往会导致ChatGPT在应用中产生歧义。例如“鸽子”在中国和大多数国家的印象中都代表着和平,在ChatGPT中亦是如此。不过,在巴斯克语中的“鸽子(uso)”也有一定的侮辱性含义。这是因为中国庞大的人口和美国经济的主导地位,导致可用数据材料中,忽略了部分小语种中词语的含义。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

