
金花235(金花235能吃什么

原文来源:CSDN

图片来源:由无界 AI生成
今年早些时候,Matt Welsh 宣布编程正在步入终结。他在 ACM Communications 中写道:
我相信 “编写程序” 的传统想法正在走向消亡,事实上,对于除非常专业的应用程序之外的所有应用程序,正如我们所知,大多数软件编程都将被经过训练的人工智能系统所取代。在一些只需要 “简单” 程序的情况下(毕竟,并不是所有东西都需要在 GPU 集群上运行的数千亿个参数的模型),这些程序本身将直接由人工智能生成,而不是手工编码 。
几周后,在一次演讲中,威尔士扩大了他的死亡观察范围。走向坟墓的不仅仅是编程艺术,还有整个计算机科学。所有计算机科学都 “注定要失败” 。(下图是演讲的屏幕截图。)
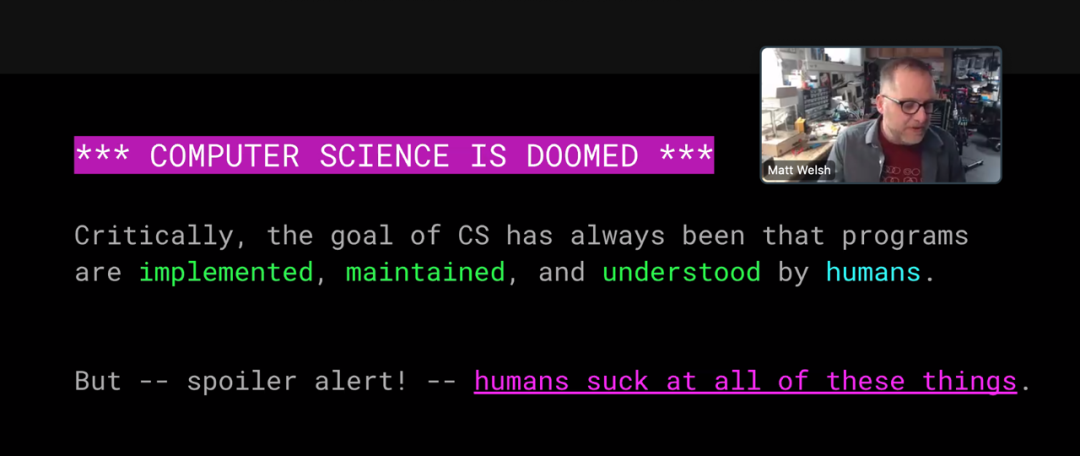
这些悲伤消息的传递者似乎并没有悲痛欲绝。尽管 Welsh 已经成为一名计算机科学教师和实践者(在哈佛、谷歌、苹果和其他地方),但他似乎渴望继续下一步。“无论如何,写代码很糟糕!” 他宣称。
我自己对后编程未来的前景并不那么乐观。首先,我持怀疑态度。我认为我们还没有跨过机器学会自己解决有趣的计算问题的门槛。我认为我们还没有接近这一点,或者正朝着正确的方向前进。此外,如果事实证明我的观点是错误的,我的冲动不是默许而是抵制。一方面,我不欢迎我们的新人工智能霸主。即使他们被证明是比我更好的程序员,我仍然会继续使用我的代码编辑器和编译器,谢谢。“编程很糟糕?” 对我来说,它长期以来一直是我快乐和启迪的源泉。我发现它也是理解世界的一个有价值的工具。在我能够将一个想法简化为代码之前,我永远不确定我是否理解了它。为了从这种学习经验中受益,我必须实际编写程序,而不仅仅是说一些魔法词并从阿拉丁的人工智能灯中召唤一个精灵。

大型语言模型
可编程机器可以编写自己的程序的想法深深植根于计算历史。Charles Babbage 早在 1836 年讨论他的分析机计划时就暗示了这种可能性。当 Fortran 于 1957 年推出时,它的正式名称是“FORTRAN 自动编码系统”。它的既定目标是让计算机“为自己编码问题并生成与人类编码员一样好的程序(但没有错误)”。
Fortran 并没有消除编程技巧(或错误),但它使过程变得不那么乏味。后来的语言和其他工具带来了进一步的改进。而全自动编程的梦想从未破灭。机器似乎比大多数人更适合编程。计算机有条不紊、受规则约束、挑剔且注重字面意思——所有这些特征(无论正确与否)都与高手程序员联系在一起。
但讽刺的是,现在准备承担编程任务的人工智能系统却奇怪地不像计算机。他们的性格更像Deanna Troi,而不是 Commander Data。逻辑一致性、因果推理和对细节的仔细关注并不是他们的强项。当他们似乎在思考深刻的想法时,他们有不可思议的辉煌时刻,但他们也有可能遭遇惊人的失败——公然、厚颜无耻的理性失误。他们让我想起一句古老的俏皮话:人都会犯错,而真正把事情搞砸则需要计算机。
最新的人工智能系统被称为大语言模型(LLM)。与大多数其他近期人工智能发明一样,它们建立在人工神经网络之上,这是一种受大脑结构启发的多层结构。网络的节点类似于生物神经元,节点之间的连接起着突触的作用,突触是信号从一个神经元传递到另一个神经元的连接点。训练网络可以调整连接的强度或权重。在语言模型中,训练是通过向网络强制输入大量文本来完成的。该过程完成后,连接权重会对训练文本的语言特征的详细统计数据进行编码。在最大的模型中,权重数量为 1000 亿个或更多。
在这种情况下,模型一词可能会产生误导。这个词并不是指比例模型或微型模型,如模型飞机。相反,它指的是预测模型,就像科学中常见的数学模型一样。正如大气模型预测明天的天气一样,语言模型预测句子中的下一个单词。
最著名的大型语言模型是 ChatGPT,它于去年秋天向公众发布,引起了极大的关注。缩写 GPT Gee Pee Tee:我的舌头不断地被这三个押韵的音节绊倒。其他 AI 产品的名字很可爱,比如Bart、Claude、Llama;我希望我能以同样的精神重命名 GPT。我会把它称为 Geppetto,它与辅音的模式相呼应。GPT 代表 Generative Pre-Trained Transformer (生成式预训练变压器);系统的聊天版本配备了对话式人机界面。ChatGPT 由 OpenAI 开发,该公司成立于 2015 年,旨在将人工智能从少数富有的科技公司的控制中解放出来。OpenAI 成功地完成了这一使命,以至于它已经成为一家富有的科技公司。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

