

金花235(金花235能吃什么
作者:金磊
来源:量子位
开源界最强的中英双语大模型,悟道·天鹰 34B,来了!
有多强?一言蔽之:
中英综合能力、逻辑推理能力等,全面超越 Llama2-70B和此前所有开源模型!
推理能力方面对话模型IRD评测基准仅次于 GPT4。
不仅模型够大够能打,而且还一口气送上整套“全家桶”级豪华周边。
能有如此大手笔的,正是中国大模型开源派先锋——智源研究院。
而若是纵观智源在数年来的大模型开源之道,不难发现它正在引领着一种新风向:
早在2021年就把全球最大语料库公开,2022年最早前瞻布局FlagOpen大模型技术开源体系,连续推出了FlagEval评测体系、COIG数据集、BGE向量模型等全技术栈明星项目。
这一魄力正是来自智源非商业、非营利的中立研究机构定位,主打的就是一个“诚心诚意开源共创”。
据了解,Aquila2-34B 基座模型在22个评测基准的综合排名领先,包括语言、理解、推理、代码、考试等多个评测维度 。
一张图来感受一下这个feel:
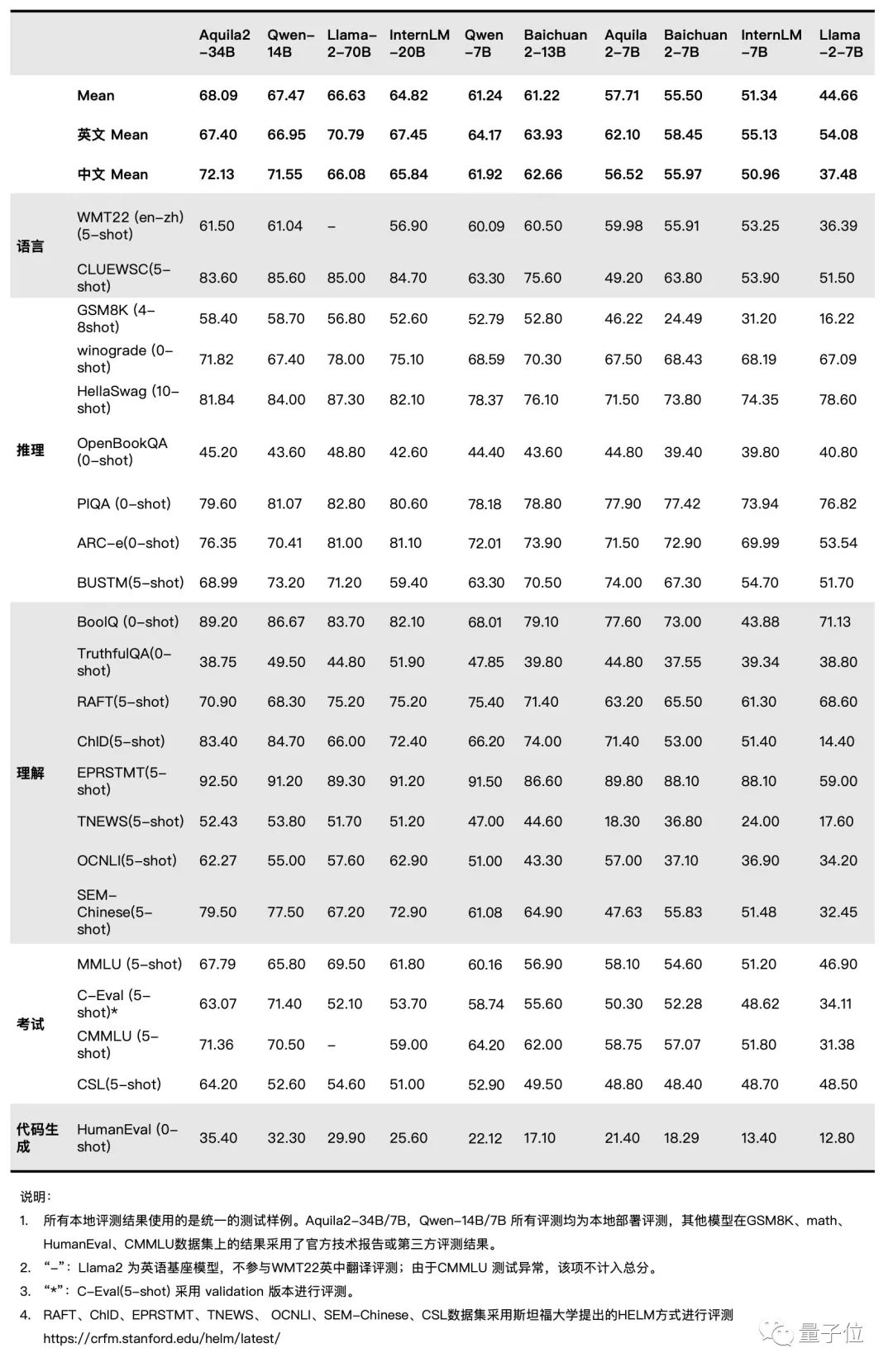
△图:Base 模型评测结果(详细数据集评测结果见官方开源仓库介绍)
正如刚才提到的,北京智源人工智能研究院还非常良心地将开源贯彻到底,一口气带来开源全家桶:
全面升级Aquila2模型系列:Aquila2-34B/7B基础模型,AquilaChat2-34B/7B对话模型,AquilaSQL“文本-SQL语言”模型;
语义向量模型BGE新版本升级:4大检索诉求全覆盖。
FlagScale 高效并行训练框架:训练吞吐量、GPU 利用率业界领先;
FlagAttention 高性能Attention算子集:创新支撑长文本训练、Triton语言。
接下来,我们继续深入了解一下这次的“最强开源”。
“最强开源”能力一览
正如我们刚才提到的Aquila2-34B,它是此次以“最强开源”姿势打开的基座模型之一,还包括一个较小体量的Aquila2-7B。
而它俩的到来,也让下游的模型收益颇丰。
最强开源对话模型
在经指令微调得到了优秀的的AquilaChat2对话模型系列:
AquilaChat2-34B:是当前最强开源中英双语对话模型,在主观+客观综合评测中全面领先 ;
AquilaChat2-7B:也取得同量级中英对话模型中综合性能最佳成绩。
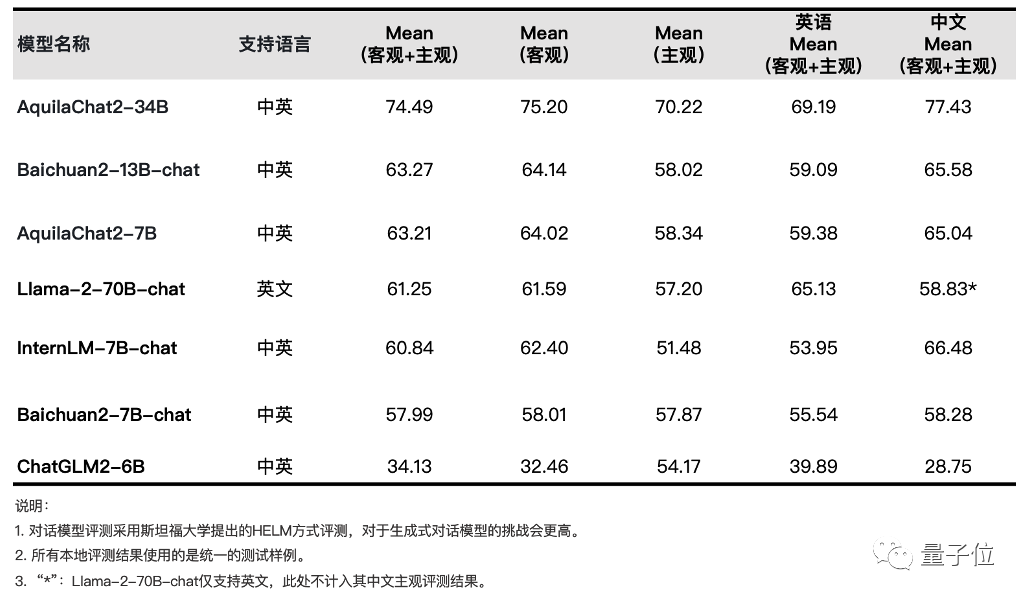
△ SFT 模型评测结果(详细数据集评测结果见官方开源仓库介绍)
评测说明:
对于生成式对话模型,智源团队认为需要严格按照“模型在问题输入下自由生成的答案”进行评判,这种方式贴近用户真实使用场景,因此参考斯坦福大学HELM[1]工作进行评测,该评测对于模型的上下文学习和指令跟随能力要求更为严格。实际评测过程中,部分对话模型回答不符合指令要求,可能会出现“0”分的情况。
例如:根据指令要求,正确答案为“A”,如果模型生成为“B”或“答案是 A ”,都会被判为“0”分。
同时,业内也有其他评测方式,比如让对话模型先拼接“问题+答案”,模型计算各个拼接文本的概率后,验证概率最高的答案与正确答案是否一致,评测过程中对话模型不会生成任何内容而是计算选项概率。这种评测方式与真实对话场景偏差较大,因此在生成式对话模型评测中没有采纳。
[1] https://crfm.stanford.edu/helm/latest/
不仅如此,在对于大语言模型来说非常关键的推理能力上,AquilaChat2-34B的表现也非常的惊艳——
在IRD评测基准中排名第一,超越 Llama2-70B、GPT3.5等模型,仅次于 GPT4。
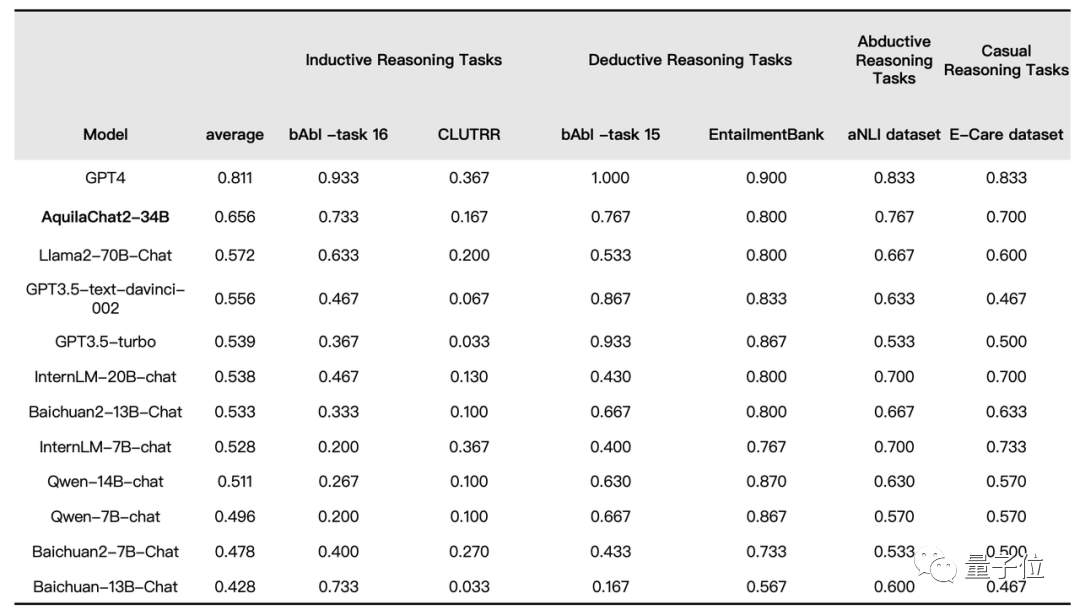
△图:SFT模型在IRD数据集上的评测结果
从种种成绩上来看,无论是基座模型亦或是对话模型,Aquila2系列均称得上是开源界最强了。
上下文窗口长度至16K
对于大语言模型来说,能否应对长文本输入,并且在多轮对话过程中保持上下文的流畅度,是决定其体验好坏的关键。
为了解决这一“苦大模型久矣”的问题,北京智源人工智能研究院便在20万条优质长文本对话数据集上做了SFT,一举将模型的有效上下文窗口长度扩展至16K。
而且不仅仅是长度上的提升,效果上更是得到了优化。
例如在LongBench的四项中英文长文本问答、长文本总结任务的评测效果上,就非常的明显了——
AquilaChat2-34B-16K处于开源长文本模型的领先水平,接近GPT-3.5长文本模型。
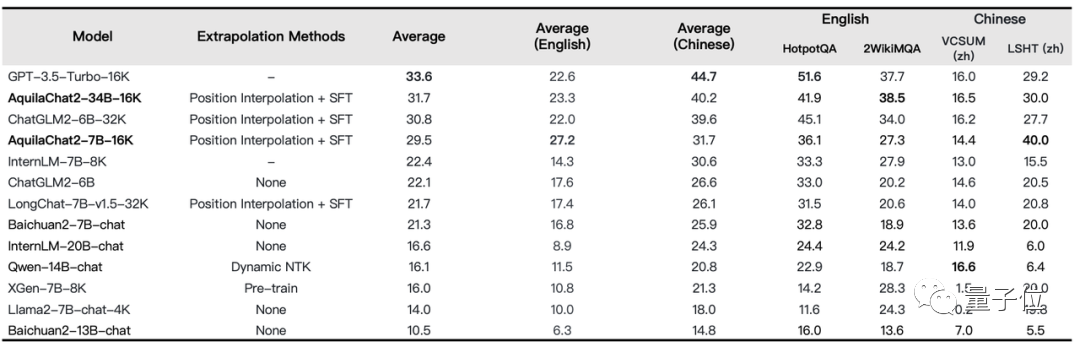
△图:长文本理解任务评测
除此之外,智源团队对多个语言模型处理超长文本的注意力分布做了可视化分析,发现所有的语言模型均存在固定的相对位置瓶颈,显著小于上下文窗口长度。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

