

千万人围观「烧焦婴儿」

图片来源:由无界 AI生成
作者:ByteDance Research负责人李航
本文阐述笔者对 LLM 的一些看法,主要观点如下:
1. LLM 强大之所在
1.1 LLM 的主要突破
ChatGPT 和 GPT4 为代表的 LLM 有以下主要手段 [1][2]。
ChatGPT 和 GPT4,相比传统的深度学习技术,如 BERT,主要是在智能性和通用性上取得了巨大突破。具备语言、知识、简单推理能力,能够很好地近似人的智能行为。不需要标注数据就可以在不同领域完成不同任务,也就是进行零样本或小样本学习。
LLM 带来的巨大进步,所能产生的效果是之前我们大多数人都没有能预见到的。究其原因,一是使用大数据大模型大算力,规模带来了质的变化。ChatGPT 有 175B 参数,300B 的 token 做训练。而之前的模型参数规模超过 1B 的都不多。二是 Open AI 开发出了一套调教大模型的方法,包括基本步骤、技巧和工程实现。利用语言建模的机制将人的知识和能力输入给大模型。大规模系统的工程实现和模型的调教方法成了 Open AI 的核心竞争力。这一点可以从相关技术的演进过程中看出。
1.2 历史演进
ChatGPT 和 GPT4 技术的一个源头是生成式对话。
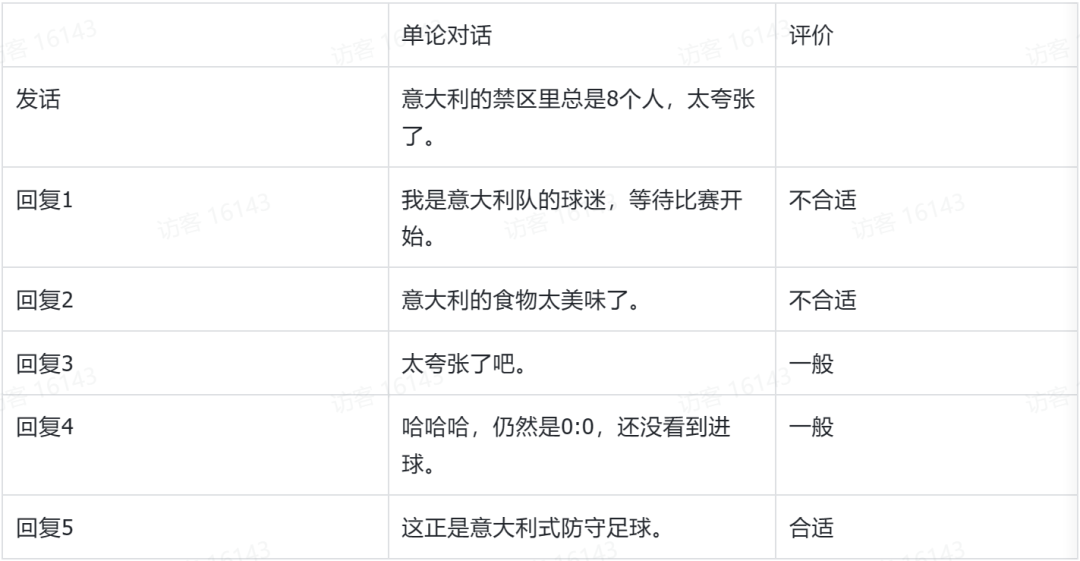
从 2012 年到 2017 年在华为诺亚方舟实验室我们对对话进行了研究,2015 年开发了领域第一个基于序列到序列 seq2seq 的生成式对话系统 Neural Responding Machine [3]。当时的序列到序列模型还是基于 LSTM 的。但是即使是这样的模型,也能生成自然的中文。表 1 给出生成的对话例子。使用 4 百万微博数据训练的 7 千万参数的这个模型,对给定一个发话,可以生成一个回复,形成一轮对话。表中给出 top 5 的几个回复。可以看出有些回复是合适的,有些是不合适的。
为解决序列到序列有时产生不合理结果的问题,我们于 2017 年开发了基于深度强化学习的方法,对序列到序列 seq2seq 的学习结果做进一步的调优 [4]。与 RLHF 有相同的算法,先学习奖励模型,然后基于策略梯度,调节整个序列到序列模型(策略模型)。模型也是基于 LSTM 的。当时的研究发现,加上深度强化学习的微调,可以把序列到序列的生成结果做得更好。
Google 的研究团队于 2017 年发表了 Transformer 模型。序列到序列的生成开始转向使用 Transformer。由于 Transformer 强大的表示和学习能力,生成式对话的效果有了大幅度的提升,也从单轮对话的生成逐渐发展到多轮对话的生成。
2018 年 Open AI 团队发表了 GPT-1 模型。其基本想法是,先训练一个基于 Transformer 的大规模语言模型,在其基础上通过有监督的微调 SFT 方法,学习序列到序列模型,把自然语言的理解和生成任务都转化为序列到序列生成的任务,在一个模型上实现所有的任务,包括生成式对话。之后又于 2019 年发表了 GPT-2,2020 年发表了 GPT-3,逐步发展到 ChatGPT 和 GPT-4。
传统的相对小的生成式模型也可以生成自然的人类语言,甚至是基于 LSTM 的。因为学习的目标是单词序列的预测误差最小化。但生成的自然语言所描述的内容有很多在现实中是不会发生的或者不合理的,也就是有严重的幻觉(hallucination)。而大规模语言模型,由于学习手段和规模,其生成的自然语言所描述的内容,在现实中是很容易发生的,甚至是合理的,幻觉现象也得到比较有效的控制。
ChatGPT 之前,业界开发出了一系列的生成式大模型,做生成式对话等任务。整体观察的现象是能更好地完成各种任务,但是能力都没有能够达到 ChatGPT 的水平。仔细阅读 GPT-3 [5] 和 InstructGPT 的论文 [1],认真观察 ChatGPT 等各种 LLM 的结果,让人感到 Open AI 的核心竞争力是他们开发了一整套语言大模型的调教方法和工程实现方法。调教方法包含预训练、SFT、RLHF 等基本步骤,更重要地,包含高质量大规模数据的准备,将数据一步步喂给模型的训练细节。
2. LLM 的特点
2.1 结合了人工智能三条路径
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

