

开源自主 AI 代理项目 Au
从涌现和扩展律到指令微调和 RLHF,OpenAI 科学家带你进入 LLM 的世界。

图片来源:由无界 AI生成
近日,OpenAI 研究科学家 Hyung Won Chung 在首尔国立大学做了题为「Large Language Models (in 2023)」的演讲。他在自己的 YouTube 频道上写到:「这是一次雄心勃勃的尝试,旨在总结我们这个爆炸性的领域。」
视频地址:https://www.youtube.com/watch?v=dbo3kNKPaUA
在这次演讲中,他谈到了大型语言模型的涌现现象以及大模型的训练和学习过程,其中包括预训练和后训练阶段,最后他还展望了一下未来,认为下一次范式转变是实现可学习的损失函数。
在深入这次演讲的具体内容之前,我们先简单认识一下这位演讲者。

Hyung Won Chung 是一位专攻大型语言模型的研究者,博士毕业于麻省理工学院,之后曾在谷歌大脑工作过三年多时间,于今年二月份加入 OpenAI。
他曾参与过一些重要项目的研究工作,比如 5400 亿参数的大型语言模型 PaLM 和 1760 亿参数的开放式多语言语言模型 BLOOM(arXiv:2211.05100)。机器之心也曾介绍过他为一作的论文《Scaling Instruction-Finetuned Language Models》。
下面进入演讲内容。
演讲开篇,Chung 便指出,现在所谓的大型语言模型(LLM)在几年后就会被认为是小模型。随着人们对模型规模(scale)的认知的变化,目前有关 LLM 的许多见解、观察和结论都会变得过时甚至可能被证明是错误的。
但他也指出,幸运的是,那些基于第一性原理(First Principle)的见解却会有相对更长的生命力,因为它们比那些看似绚丽多彩的先进思想更为基础。
Chung 的这次演讲聚焦的正是这些更为基础的思想,他希望这些内容在未来几年内依然具有参考价值。
大模型的涌现现象
大型语言模型有一个有趣的现象:只有当模型达到一定规模时,某些能力才会显现。
如下图所示,很多模型在规模达到一定程度时,在准确度等某些性能指标上会出现急剧的变化,甚至模型会突然有能力解决在规模较小时完全无法解决的问题。这种现象被称为涌现(emergence)。
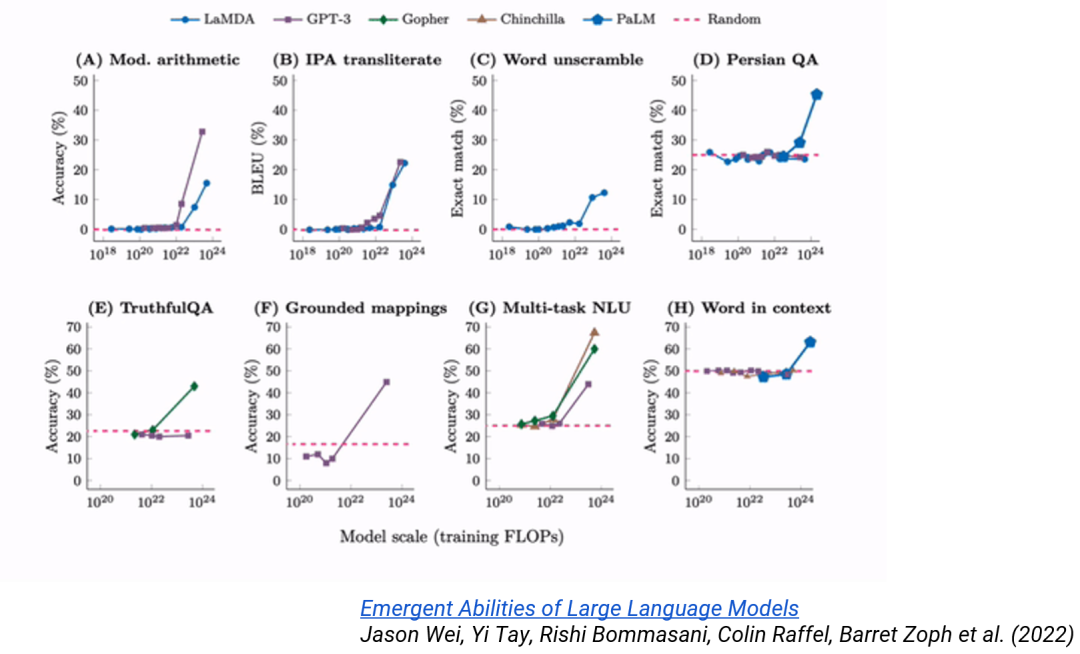
这个有趣现象给 AI 研究带来了很多重要的新视角。
Chung 首先提到的视角是「yet」,也就是说就算某个想法或能力目前无法实现,但随着规模扩展,也许后面会突然能够实现。

这一视角转变可能看似简单,却涉及到我们对语言模型的根本看法。一项对当前模型无用的技术也许三五年后就能变得有用,因此我们不应对当前的各种事物抱有永恒不变的观念。
他指出,「yet」视角之所以并不是显而易见的,是因为我们习惯了在一个基础公理不变的环境中工作。就像在进行自然科学实验时,如果你已经通过实验发现某个科学思想不对,那么你必定相信如果三年后再实验一次,这个思想还是不可能变正确;而且就算再过三十年,结果依然如此。

那么语言模型领域是否也存在类似于这类公理的概念呢?
Chung 认为可以把一定时段内最强大的模型视为这种「公理」,因为在这段时间里,很多研究实验都是基于该模型进行的。但有趣的地方在于:最强大的模型会变化。
举个例子,在 GPT-4 诞生时,它是最强大的,研究者基于其进行了大量实验,得到了许多研究成果和见解。但当新的更强大模型出现时,之前发现的一些见解和想法就过时了,甚至出现了许多新旧实验结果相矛盾的情况。
这就需要我们持续刷新已知的知识和观念,Chung 使用了「unlearn」一词,也就是说要刻意地去忘记已经不可行的思路。

Chung 表示目前还很少有人这样实践。而在竞争激烈的 AI 领域,很多只有一两年经验的新人却能提出有重大意义的思想,Chung 认为其中一部分原因就是这些新人会去尝试之前有经验的人尝试过的无效想法 —— 但这些想法却能有效地用于当前的模型。
因此,Chung 呼吁研究者要走在规模扩展曲线之前。

免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

