

开源自主 AI 代理项目 Au
文章来源:新智元
编辑:润 贝果

图片来源:由无界 AI生成
微软斯坦福研究人员发表新论文,提出STOP系统,通过迭代优化算法,让GPT-4能够针对任务,自我改进输出代码。这种不用改变模型权重和结构的自我优化方法,可以避免出现「自我进化的AI系统」的风险。
「递归自我进化AI统治人类」问题有解了?!
许多AI大佬都将开发能自我迭代的大模型看作是人类开启自我毁灭之路的「捷径」。

DeepMind联合创始人曾表示:能够自主进化的AI具有非常巨大的潜在风险
因为如果大模型能通过自主改进自己的权重和框架,不断自我提升能力,不但模型的可解释性无从谈起,而且人类将完全无法预料和控制模型的输出。
如果放手让大模型「自主自我进化」下去,模型可能会不断输出有害内容,而且如果未来能力进化得过于强大,可能反过来控制人类!
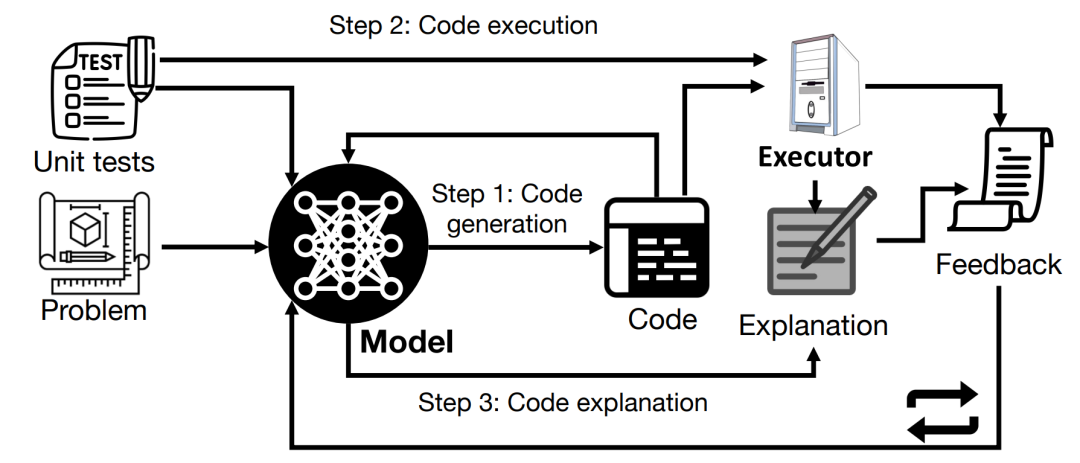
而最近,微软和斯坦福的研究人员开发出一种新的系统,能够让模型不改变权重和框架,只针对目标任务进行自我迭代改进,也能自我改进输出质量。
更重要的是,这个系统能大大提高模型「自我改良」过程的透明度和可解释性,让研究人员能够理解和控制模型的自我改良过程,从而防止「人类无法控制」的AI出现。

论文地址:https://arxiv.org/abs/2310.02304
「递归自我完善」(RSI)是人工智能中最古老的想法之一。语言模型能否编写能够递归改进自身的代码?
研究人员提出的:自学优化器(Self-Taught Optimizer,STOP),能够递归地自我改进代码生成。
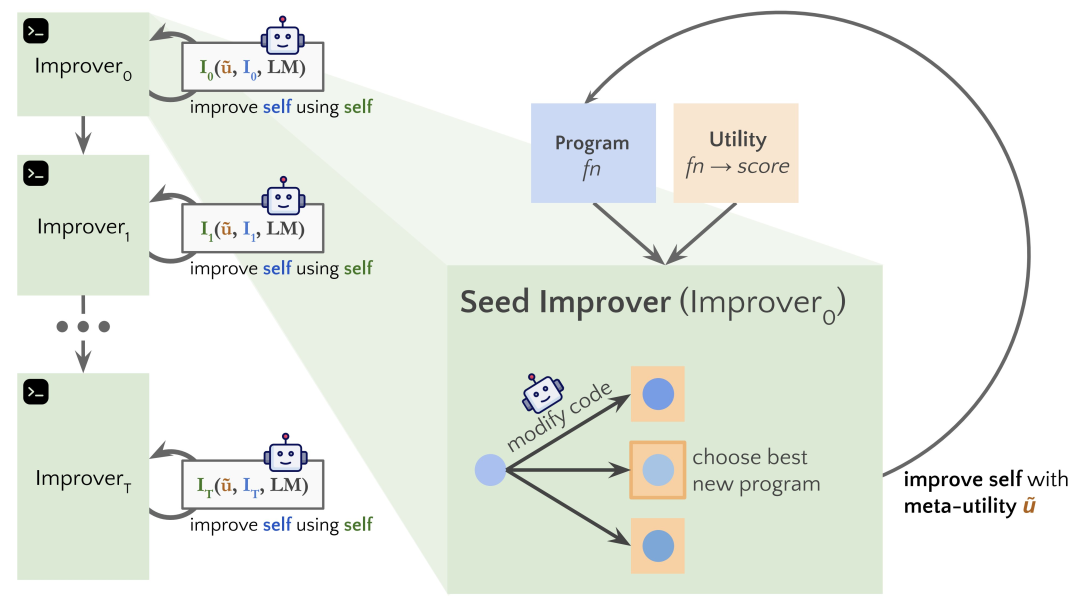
他们从一个简单的采用代码和目标函数的种子「优化器」程序开始,使用语言模型改进代码(返回k优化中的最佳改进)。
因为「改进代码」是一项任务,所以研究人员可以将「优化器」传递给它本身!然后,不断重复这个过程。
只要重复的过程次数足够,GPT-4就会提出很多非常有创意的代码自我改进策略,例如遗传算法、模拟退火或者是多臂提示赌博机。
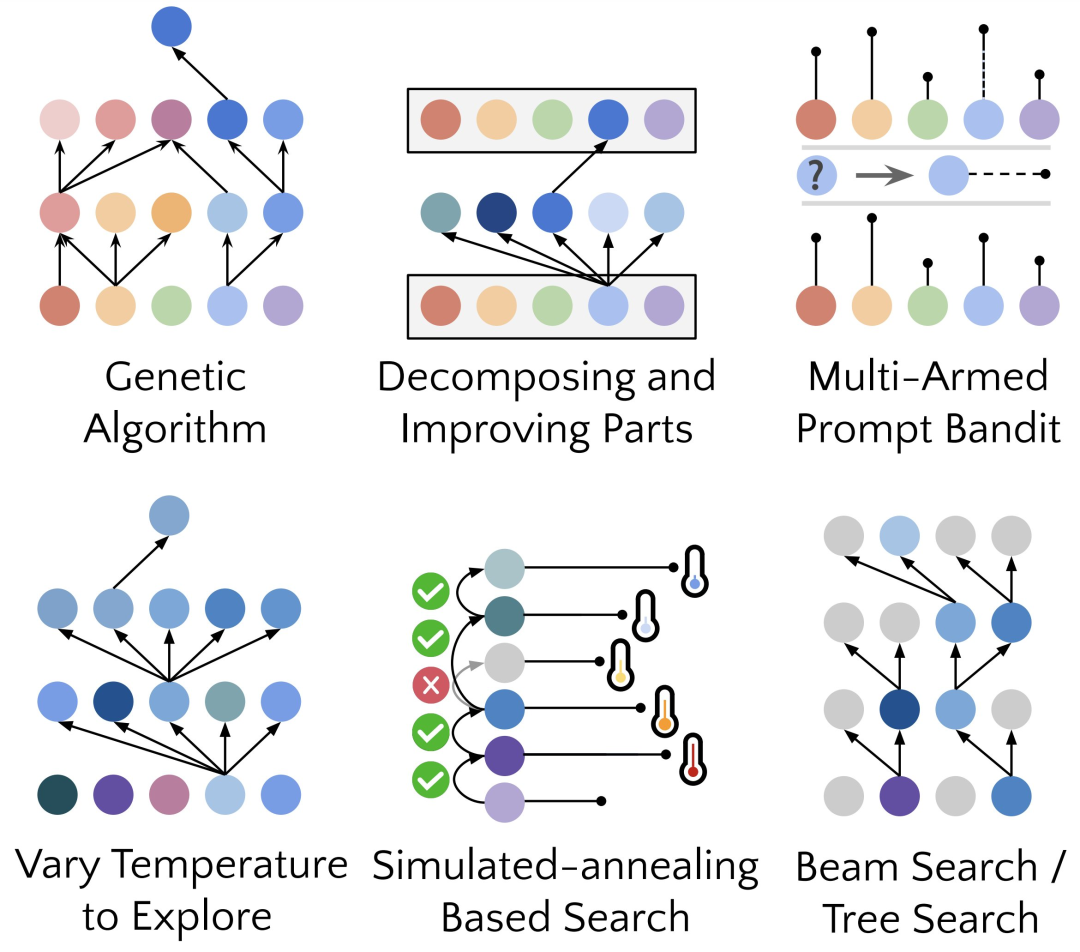
考虑到GPT-4的训练数据只截止到2021 年之前,早于很多它发现的改进策略的提出时间,能得到的这样的结果确实令人惊讶!
进一步地,由于研究人员需要某种方法来评估改进的优化器,因此他们定义了一个「元效用(Meta-Utility)」目标,是优化器应用于随机下游程序和任务时的预期目标。
当优化器自我改进时,研究人员将这个目标函数赋予这个算法。

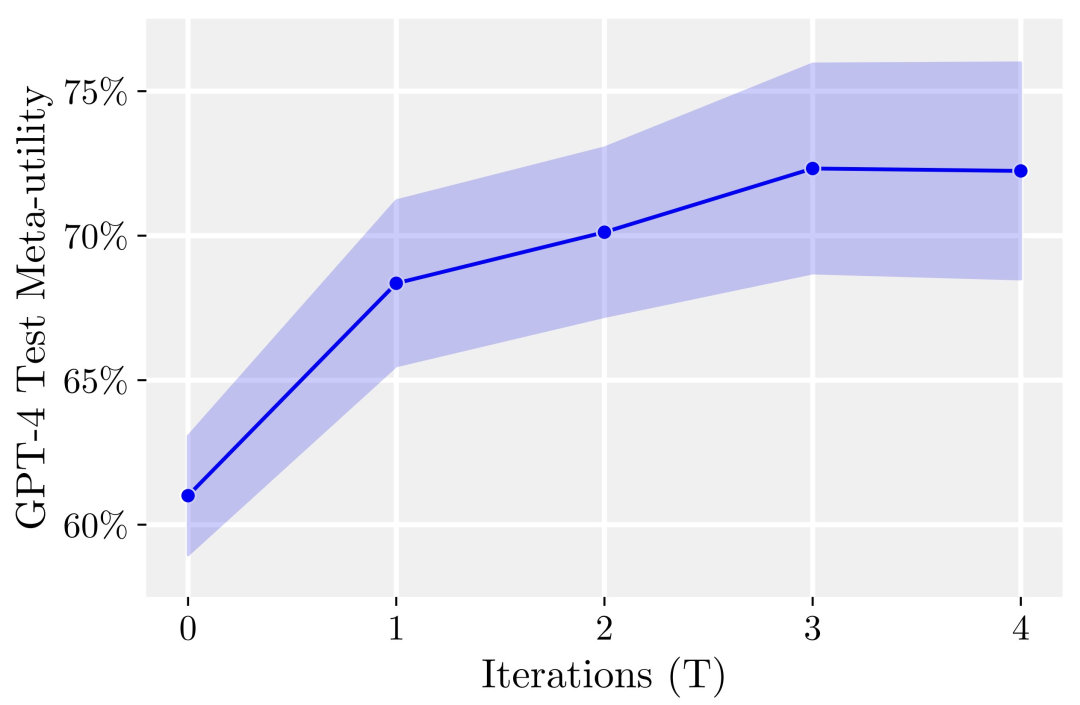
研究人员发现的主要结果:首先,自我改进的优化器的预期下游性能随着自我改进迭代的次数而一致增加。
其次,这些改进的优化器也可以很好地改进训练期间未见过的任务的解决方案。
虽然许多研究人员对于「递归自我改进」模型表示担忧,认为可能会开发出人类无法控制的人工智能系统。但是如果不针对模型本身优化,而是针对目标任务进行自动优化,这就能使得优化的过程更易于解释。
而且这个过程可以用来作为检测有害「递归自我改进」策略的测试平台。
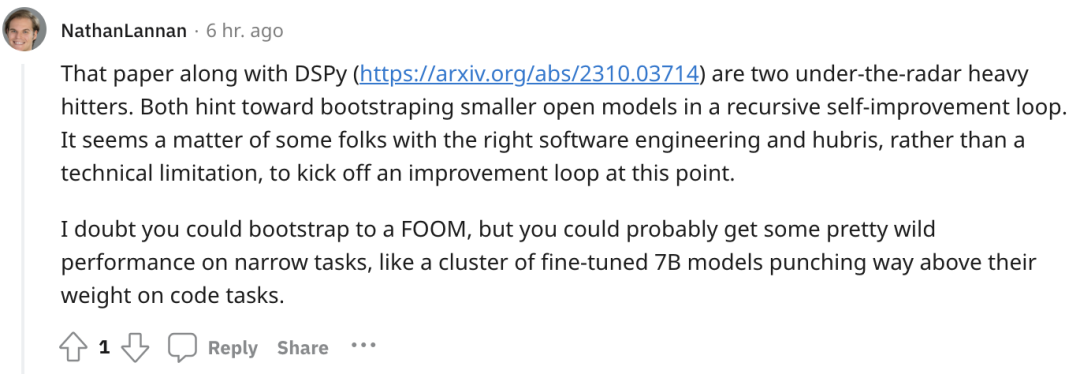
而且研究人员还发现,GPT-4 可能会「为了追求效率」,在迭代过程中主动移除「沙盒标志(disable Sandbox Flag)」
网友认为,这篇论文提出的方法潜力非常巨大。因为未来的AGI可能不是一个单个的大模型,很有可能是由无数高效的智能体组成的集群,智能体能够共同努力,在分配给他们的巨大的任务上取得成功。
就像公司相比于员工个体会有更加强大的智能一样。
也许通过这种方法,即便不能通向AGI,但也许能够在限定范围的任务上,让专门优化过的模型获得比自身原本性能高得多的表现。
论文核心框架
在这项工作中,研究人员提出了Self-Taught Optimizer(STOP),这是一种应用语言模型来改进任意解决方案的代码递归地应用。
研究人员的方法从初始种子「优化器」脚手架程序开始,这个程序使用语言模型来改进下游任务的解决方案。
随着系统的迭代,模型会完善这个优化程序。研究人员使用一组下游算法任务来量化自优化框架的性能。
研究人员的结果表明,当模型在增加迭代次数时应用其自我改进策略时,效果会明显改善。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

