

微软Azure OpenAI支持数据微
原文来源:量子位

图片来源:由无界 AI生成
试问百模大战的当下,谁家大模型的透明度最高?
(例如模型是如何构建的、如何工作、用户如何使用它们的相关信息。)
现在,这个问题终于有解了。
因为斯坦福大学HAI等研究机构最新共同发布了一项研究——
专门设计了一个名为基础模型透明度指标(The Foundation Model Transparency Index)的评分系统。
它从100个维度对国外10家主流的大模型做了排名,并在透明度这一层面上做了全面的评估。

结果可谓是大跌眼镜!
若是以60分作为及格线,那么“参赛”的大模型们可以说是全军覆没,没有一个及格的……
来感受下这个feel:
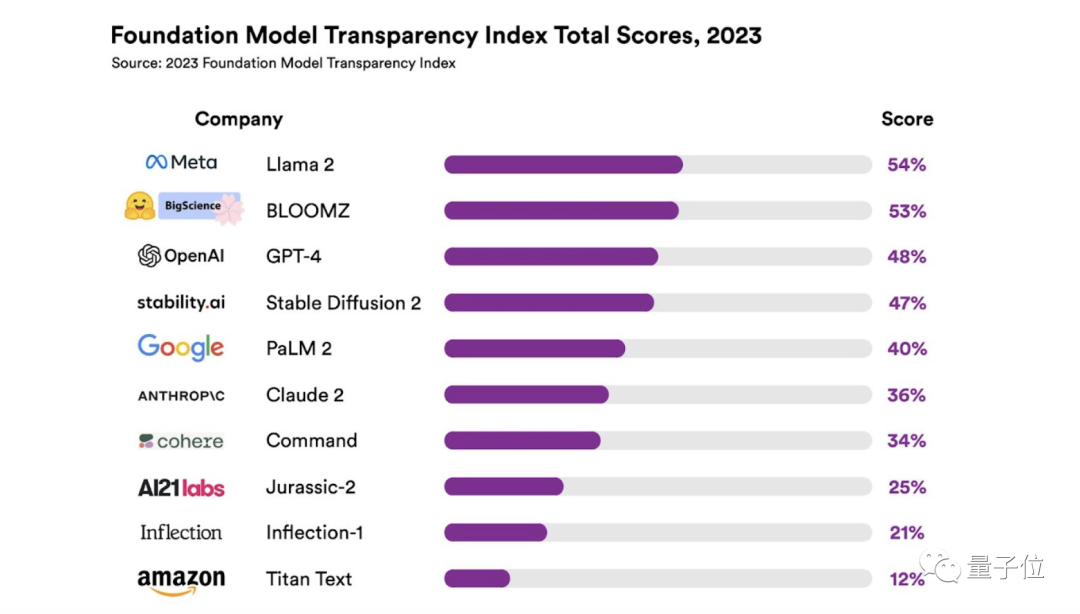
排名第一的Llama 2,分数仅为54;紧随其后的便是BLOOMZ,得分53。
而GPT-4分数仅仅为48,排名第三;来自亚马逊的Titan Text成绩垫底,仅取得12分

。
不仅如此,在斯坦福HAI官方的博客中,负责人Rishi Bommasani直言不讳地把OpenAI单拎出来说到:
基础模型领域的公司变得越来越不透明。
例如名字带“open”的OpenAI曾明确表示,与GPT-4相关的大多数信息将不会公开。
总而言之,团队认为大模型发展到现阶段,它们的透明度是一个非常重要的关键点,直接与是否可信挂钩。
而且更深层次的,他们认为这也从侧面反映了人工智能行业从根本上缺乏透明度。
100多页论文研究模型透明度
那么这个排名到底是怎么来的?
在成绩公布的同时,团队也把一篇厚达100多页的论文晒了出来。

正如我们刚才提到的,这次排名一共涉及到了100个指标维度。
若是“归拢归拢”着来看,可以将这些指标大致分为三大类,分别是:
将10大模型此次的成绩,按照上面的三大维度来看,得分细节如下:
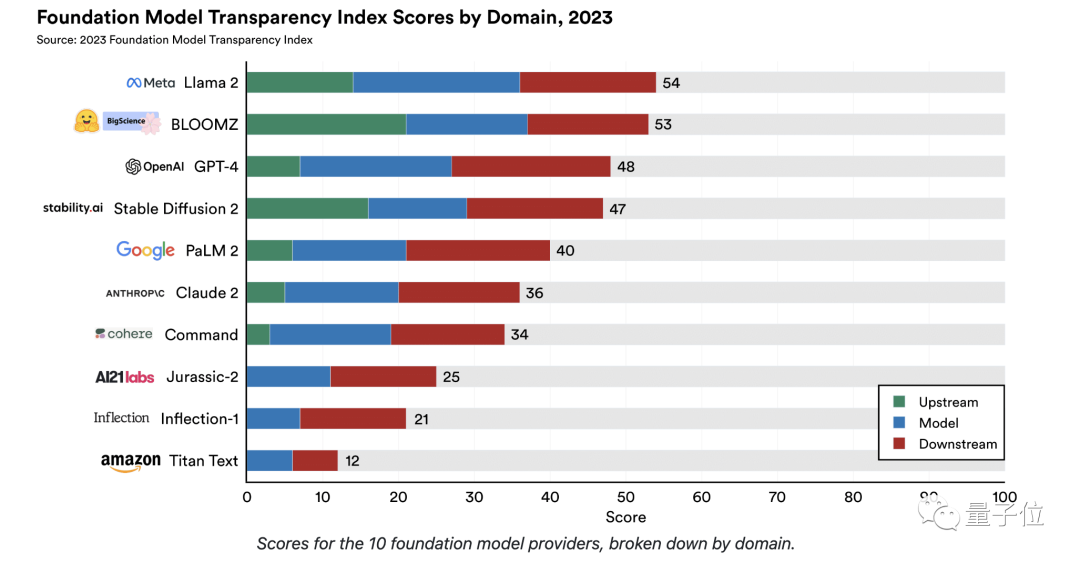
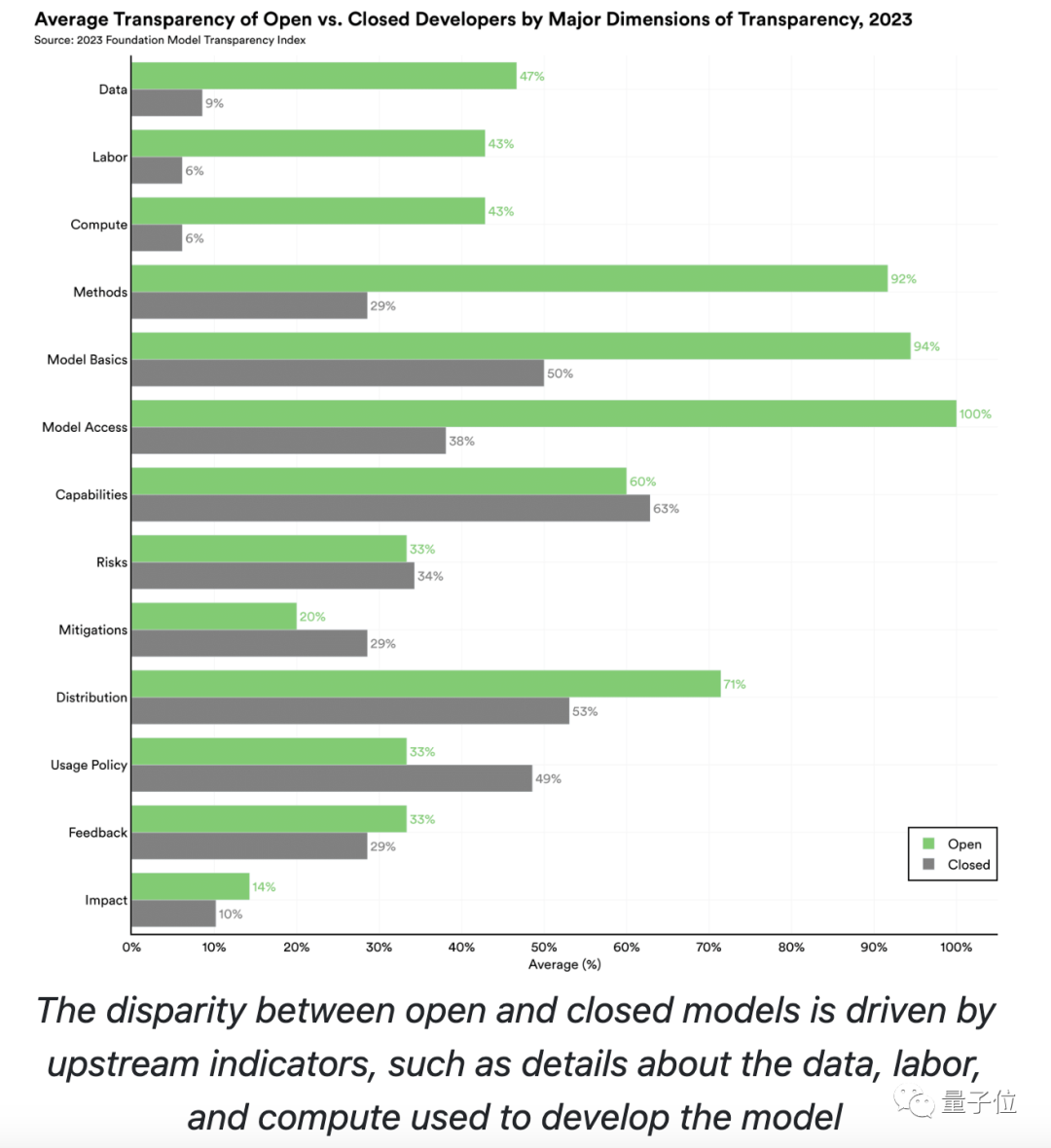
从结果上来看,“上游”类指标的得分差异较为明显;例如BLOOMZ的“上游”类指标在整体得分中的占比较高。
而像Jurassic-2、Inflection-1和Titan Text,这三个模型的“上游”类指标得分直接为0。
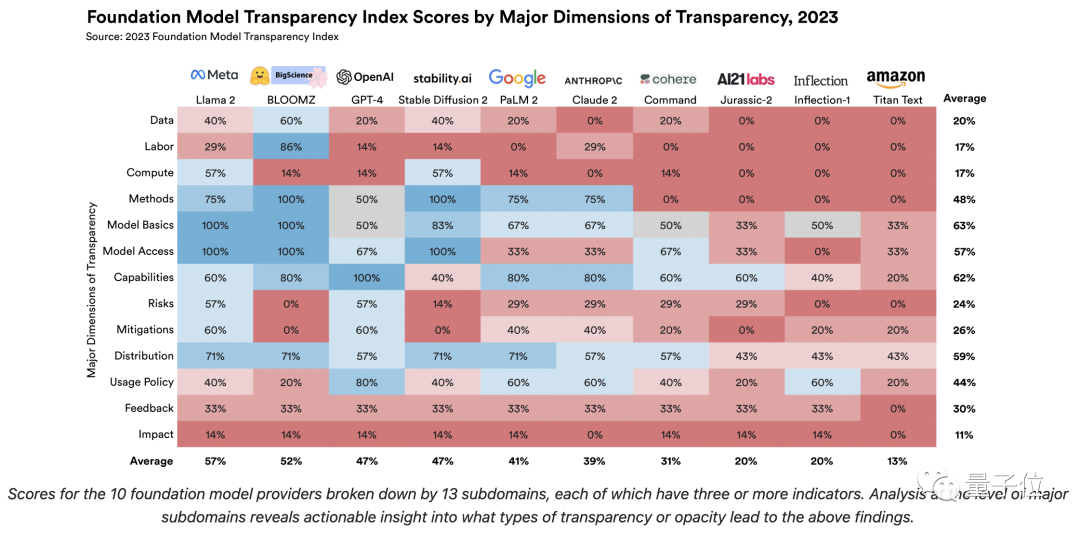
如果将“上游”、“模型”和“下游”视为三个“顶级域”,那么团队在它们基础之上,还分了更精细、更深入的13个“子域”:
13个“子域”划分下的细节得分情况如下:
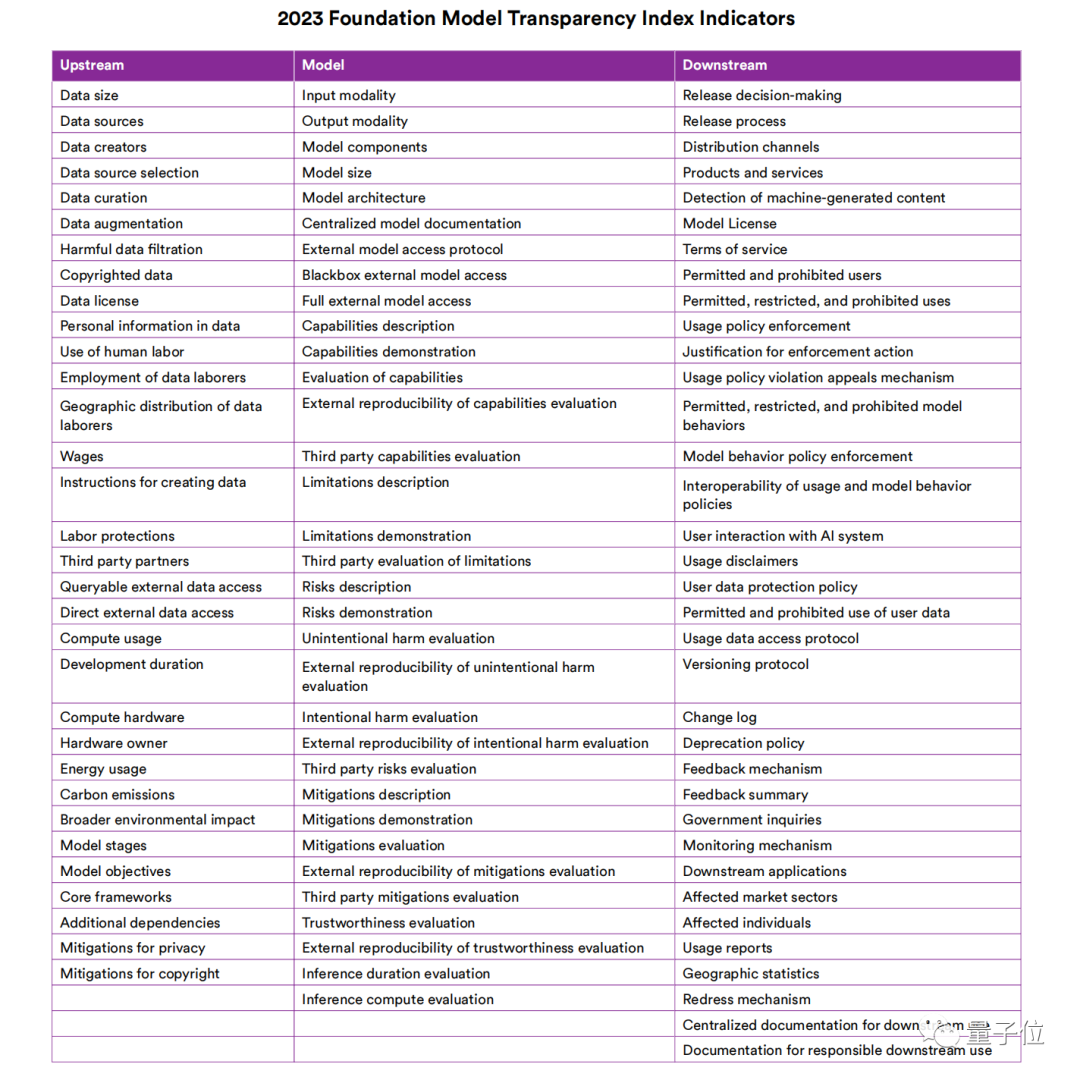
至于完整的100个指标维度,可以参考下面这张图表:
当然,对于大模型领域最具热度话题之一的“开源闭源之争”,也在此次的研究中有所涉足。
团队将广泛可下载的模型标记为开源模型,“参赛选手”中有三位属于此列,分别是Llama 2、BLOOMZ和Stable Diffusion 2。
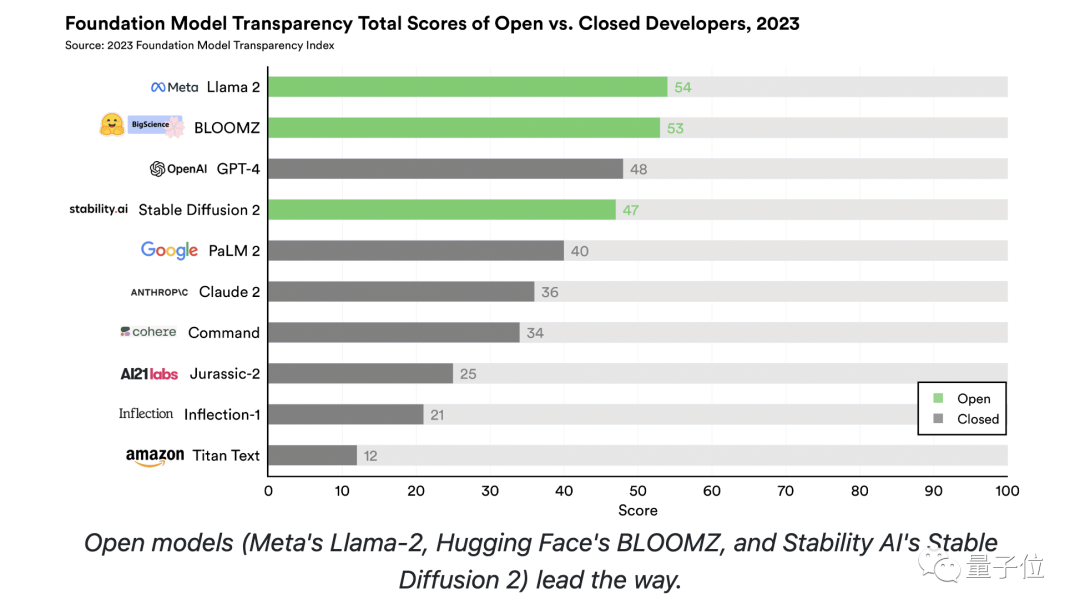
从排名结果中显而易见地可以看出,开源模型的得分普遍遥遥领先,唯有GPT-4的得分比Stable Diffusion 2高出了1分。
对此,研究人员也做出了解释:
这种差异很大程度上是由于闭源模型的开发人员在“上游”问题上缺乏透明度造成的,比如用于构建模型的数据、劳动力和计算。
此次模型透明度排名的更多细节内容,可参考文末的论文。
透明度为什么重要?
针对这个问题,斯坦福HAI在官方博客中也做出了相应说明。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

