

微软Azure OpenAI支持数据微
原文来源:新智元

图片来源:由无界 AI生成
近年来,Transformer在自然语言处理以及计算机视觉任务中取得了不断突破,成为深度学习领域的基础模型。
受此启发,众多Transformer模型变体在时间序列领域中被提出。
然而,最近越来越多的研究发现,使用简单的基于线性层搭建的预测模型,就能取得比各类魔改Transformer更好的效果。

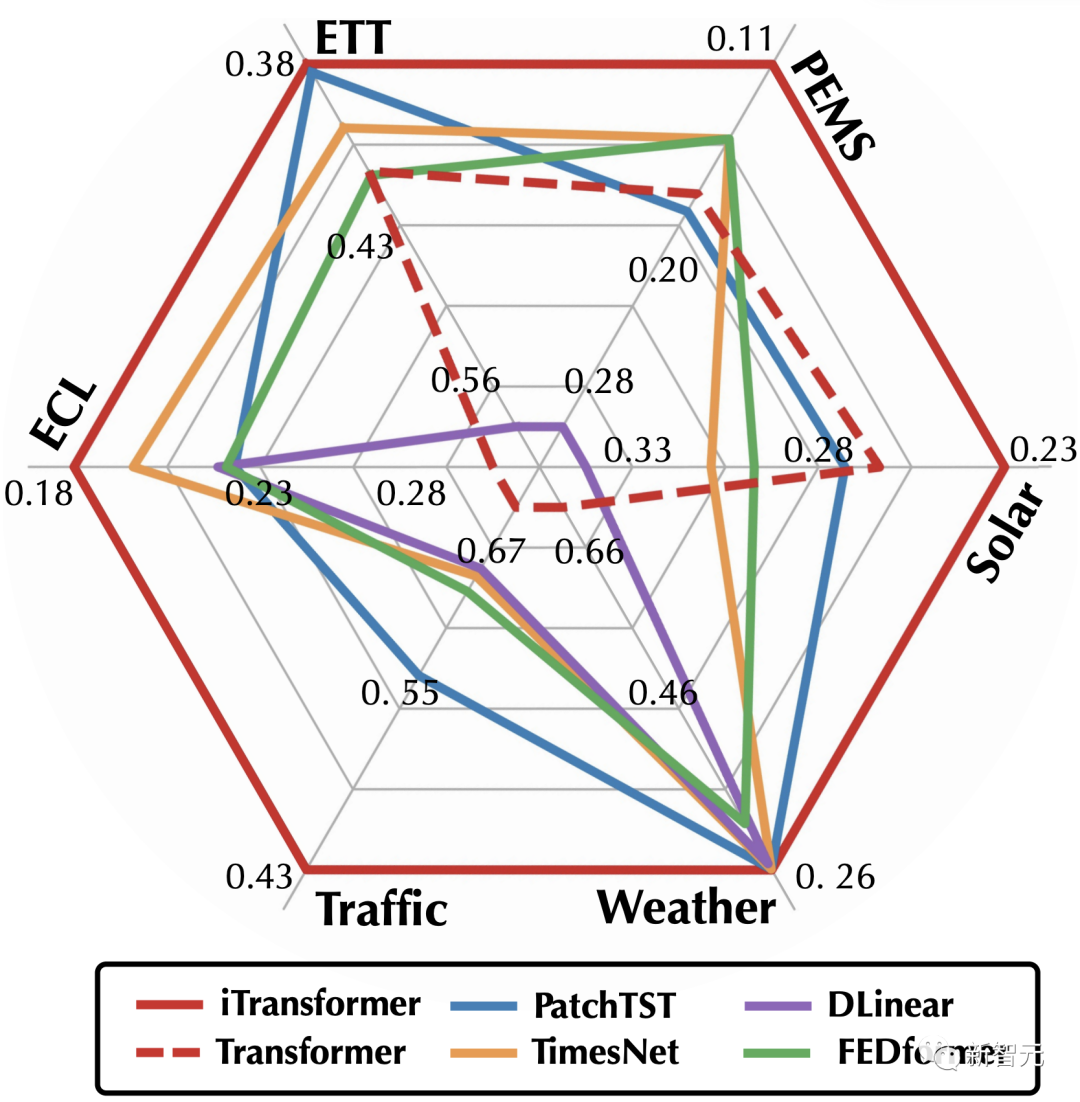
最近,针对有关Transformer在时序预测领域有效性的质疑,清华大学软件学院机器学习实验室和蚂蚁集团学者合作发布了一篇时间序列预测工作,在Reddit等论坛上引发热烈讨论。
其中,作者提出的iTransformer,考虑多维时间序列的数据特性,未修改任何Transformer模块,而是打破常规模型结构,在复杂时序预测任务中取得了全面领先,试图解决Transformer建模时序数据的痛点。

论文地址:https://arxiv.org/abs/2310.06625
代码实现:https://github.com/thuml/Time-Series-Library
在iTransformer的加持下,Transformer完成了在时序预测任务上的全面反超。
问题背景
现实世界的时序数据往往是多维的,除了时间维之外,还包括变量维度。
每个变量可以代表不同的观测物理量,例如气象预报中使用的多个气象指标(风速,温度,湿度,气压等),也可以代表不同的观测主体,例如发电厂不同设备的每小时发电量等。
一般而言,不同的变量具有完全不同的物理含义,即使语义相同,其测量单位也可能完全不同。
以往基于Transformer的预测模型通常先将同一时刻下的多个变量嵌入到高维特征表示(Temporal Token),使用前馈网络(Feed-forward Network)编码每个时刻的特征,并使用注意力模块(Attention)学习不同时刻之间的相互关联。
然而,这种方式可能会存在如下问题:
设计思路
不同于自然语言中的每个词(Token)具有较强的独立语义信息,在同为序列的时序数据上,现有Transformer视角下看到的每个「词」(Temporal Token)往往缺乏语义性,并且面临时间戳非对齐与感受野过小等问题。
也就是说,传统Transformer的在时间序列上的建模能力被极大程度地弱化了。
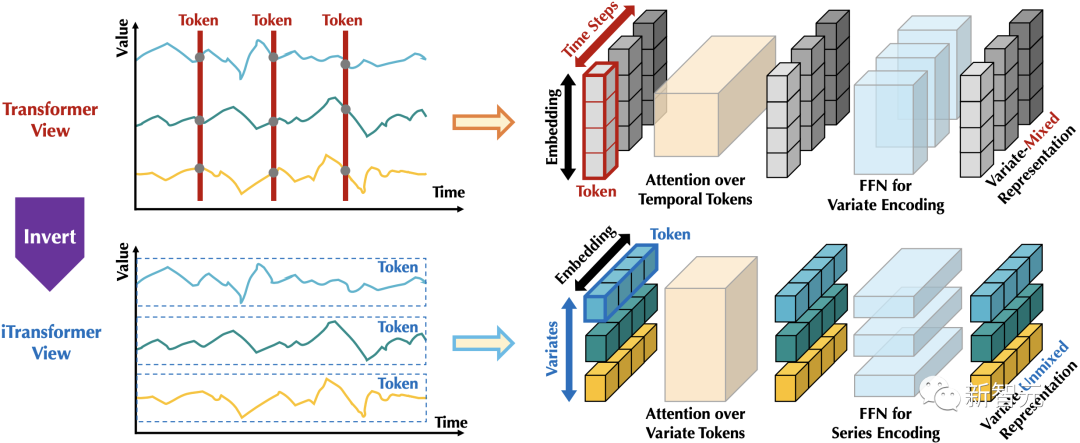
为此,作者提出了一种全新的倒置(Inverted)视角。
如下图,通过倒置Transformer原本的模块,iTransformer先将同一变量的整条序列映射成高维特征表示(Variate Token),得到的特征向量以变量为描述的主体,独立地刻画了其反映的历史过程。
此后,注意力模块可天然地建模变量之间的相关性(Mulitivariate Correlation),前馈网络则在时间维上逐层编码历史观测的特征,并且将学到的特征映射为未来的预测结果。
相比之下,以往没有在时序数据上深入探究的层归一化(LayerNorm),也将在消除变量之间分布差异上发挥至关重要的作用。
iTransformer
整体结构
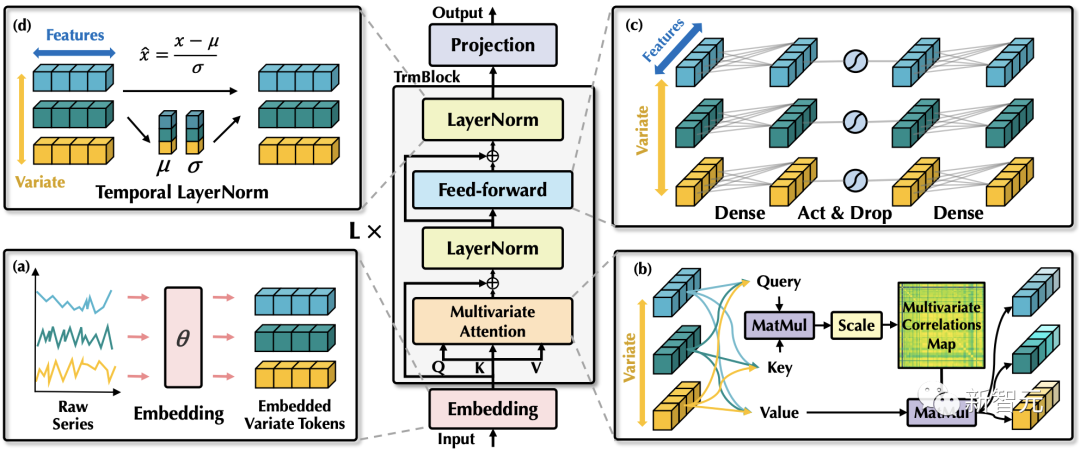
不同于以往Transformer预测模型使用的较为复杂的编码器-解码器结构,iTransformer仅包含编码器,包括嵌入层(Embedding),投影层(Projector)和 个可堆叠的Transformer模块(TrmBlock)。
建模变量的特征表示
对于一个时间长度为 、变量数为 的多维时间序列 ,文章使用 表示同一时刻的所有变量,以及 表示同一变量的整条历史观测序列。
考虑到 比 具有更强的语义以及相对一致的测量单位,不同于以往对 进行特征嵌入的方式,该方法使用嵌入层对每个 独立地进行特征映射,获得 个变量的特征表示 ,其中 蕴含了变量在过去时间内的时序变化。
该特征表示将在各层Transformer模块中,首先通过自注意力机制进行变量之间的信息交互,使用层归一化统一不同变量的特征分布,以及在前馈网络中进行全连接式的特征编码。最终通过投影层映射为预测结果。
基于上述流程,整个模型的实现方式非常简单,计算过程可表示为:
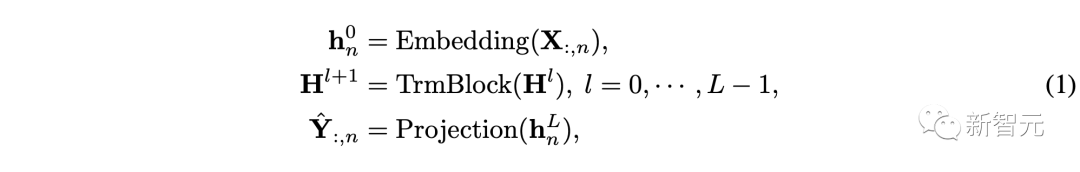
其中 即为每个变量对应的预测结果,嵌入层和投影层均基于多层感知机(MLP)实现。
值得注意的是,因为时间点之间的顺序已经隐含在神经元的排列顺序中,模型不需要引入Transformer中的位置编码(Position Embedding)。
模块分析
调转了Transformer模块处理时序数据的维度后,这篇工作重新审视了各模块在iTransformer中的职责。
1. 层归一化:层归一化的提出最初是为了提高深度网络的训练的稳定性与收敛性。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

