

苹果公司投入 10 亿美元开
原文来源:新智元

图片来源:由无界AI生成
到底什么才是LLM长上下文模型的终极解决方案?
最近由普林斯顿大学和Meta AI的研究者提出了一种解决方案,将LLM视为一个交互式智能体,让它决定如何通过迭代提示来读取文本。

论文地址:https://arxiv.org/abs/2310.05029
他们设计了一种名为MemWalker的系统,可以将长上下文处理成一个摘要节点树。
收到查询时,模型可以检索这个节点树来寻找相关信息,并在收集到足够信息后做出回应。在长文本问答任务中,这个方法明显优于使用长上下文窗口、递归和检索的基线方法。
LeCun也在推上转发对他们的研究表示了支持。

MemWalker主要由两个部分构成:
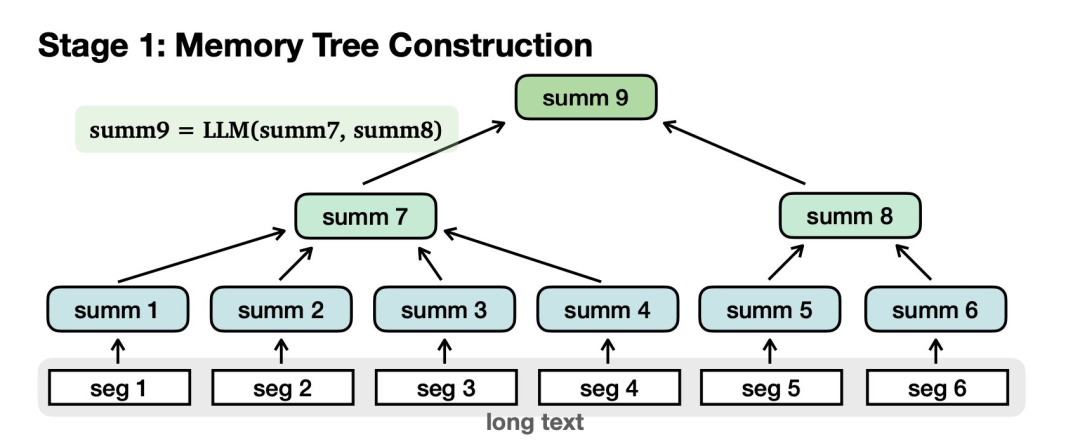
首先需要构建记忆树:
对长文本进行切分,归纳为摘要节点。汇总节点进一步汇总为更高级别的节点,最后到达根。
第二部分是导航(Navigation):
在接受查询后,LLM会在树中导航以查找相关信息并进行适当的响应。LLM通过推理来完成这一过程——可能会致力于找到某个答案,选择沿着一条路走得更远,或者发现自己误入歧途,就原路撤回。
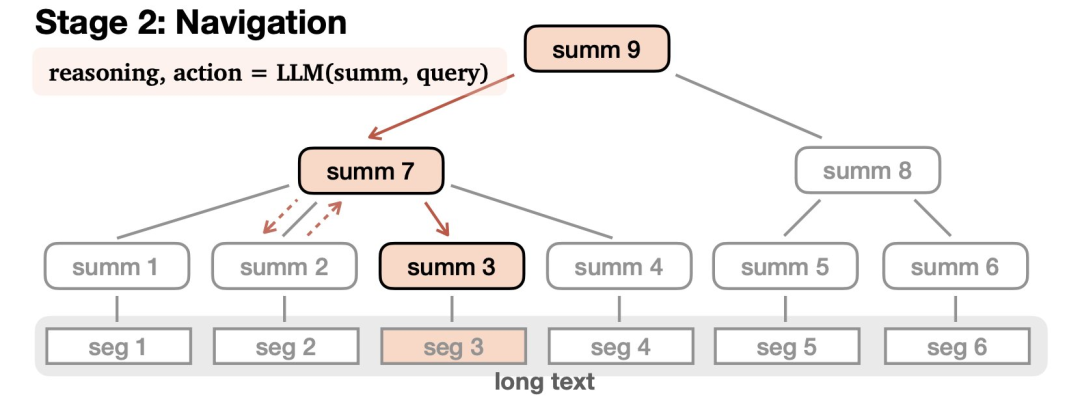
这个导航过程可以通过零样本提示来实现,并且很容易适用于指定的的任何一个大语言模型。

研究团队表明,通过对这个模型构建的记忆树的交互式读取,MemWalker 优于其他长上下文基线以及检索和循环变体,特别对于更长的例子,效果更好。
MemWalker的有效性取决于两个关键部分:
1) 工作内存大小 ——当允许 LLM 沿着其检索的路径能够获取跟多信息时,LLM 拥有更好的全局上下文能力。
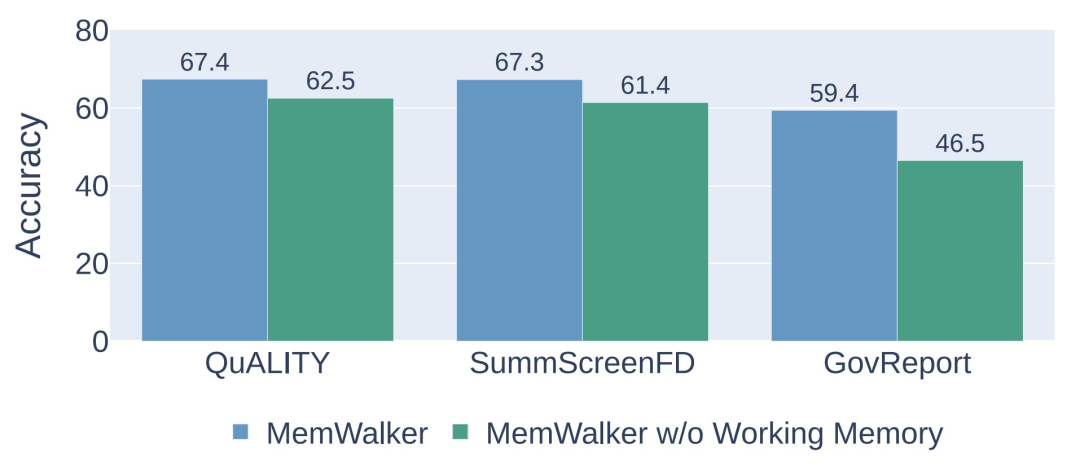
2)LLM的推理能力高低——当LLM达到推理阈值时,MemWalker是有效的。当推理能力低于阈值时,导航过程中错误率就会很高。
MEMWALKER: 一个可互动读取器
研究团队研究与长上下文问答相关的任务——给定长文本x和查询q,模型的目标是生成响应r。
MEMWALKER遵循两个步骤:
1) 内存树构建,其中长上下文被拆分成树形数据结构。这种构建不依赖于查询,因此如果事先有序列数据,可以提前计算。
2) 导航,模型在接收到查询时导航此结构,收集信息以制定合适的响应。
MEMWALKER假定可以访问基础LLM,并且通过迭代LLM提示实现构建和导航。
导航
在接收到查询q后,语言模型从根节点
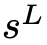
开始导航树以生成响应r。
在LLM遍历的节点
处,它观察到下一级节点
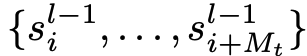
的摘要。
LLM决定在
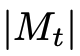
+ 1个动作中选择一个 - 选择一个子节点以进一步检查,或者返回到父节点。
在叶节点
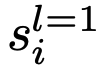
处,LLM可以决定两个动作中的一个:提交叶节点并响应查询,或者如果叶节点中的信息
(即
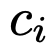
)不足,则返回到父节点
。
为了做出导航决定,研究团队也可以通过提示要求LLM首先以自然语言生成一个理由来证明动作,然后是动作选择本身。
具体地说,在每个节点,模型生成响应r ∼ LLM(r | s, q),其中响应是两个元组中的一个:1) 当LLM位于叶节点时,r = (reasoning, action, answer) 或 2) 当LLM位于非叶节点时,r = (reasoning, action)。
导航提示设计
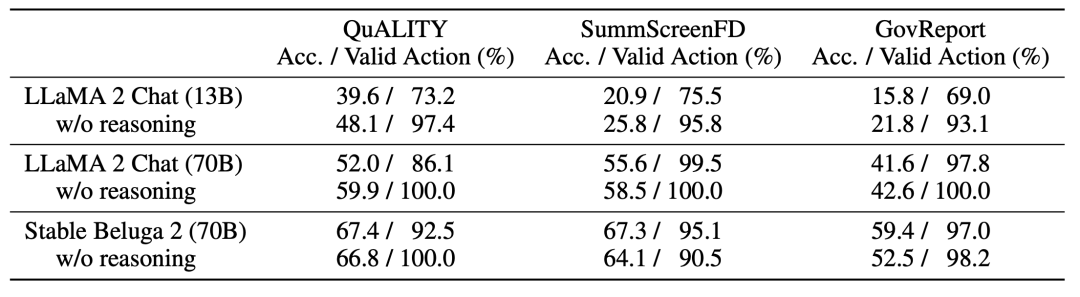
研究团队通过零样本提示启用LLM导航。具体需要两种类型的提示:
1) 分诊提示和2) 叶提示(在下表中高亮显示)。

分诊提示包含查询、子节点的摘要和LLM应遵循的指令。分诊提示用于非叶节点。
叶提示包含段落内容、查询(和选项)以及要求LLM生成答案或返回到父节点的指令。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

