

英伟达:帝国裂缝一条条
原文来源:远川科技评论
作者:叶子凌/何律衡

图片来源:由无界AI生成
今年夏天,英伟达创始人黄仁勋专门腾出时间,拜访了一家名叫战略与国际研究中心(CSIS)的智库。在美国,智库的意见能在很大程度上左右华盛顿的政策走向,深处科技战前线的黄仁勋自然深知这一点。
黄仁勋上来就是一顿彩虹屁,并明确表达了捐赠的意向。随后他话锋一转,表示有一位小同志严重拖累了智库队伍的整体水平,建议清除出去。
这位小同志不是别人,正是CSIS高级研究中心主任Gregory C. Allen,也是美国芯片出口管制政策的坚定鼓吹者。
面对美国的打压,英伟达似乎比中国公司还着急。过去数月,黄仁勋一直在竭尽全力阻止制裁落地。

Gregory C. Allen,为数不多能拿捏黄总的男人
除去给智库施压,黄仁勋还当面警告了华盛顿决策层,认为制裁会造成严重代价。与此同时,他还不忘敦促美国半导体行业协会发表谴责声明,强调进一步限制将损害行业的竞争力[2]。
今年7月,黄仁勋还拉上高通和英特尔去了趟华盛顿,目的也是说服美国政府放松对华限制。
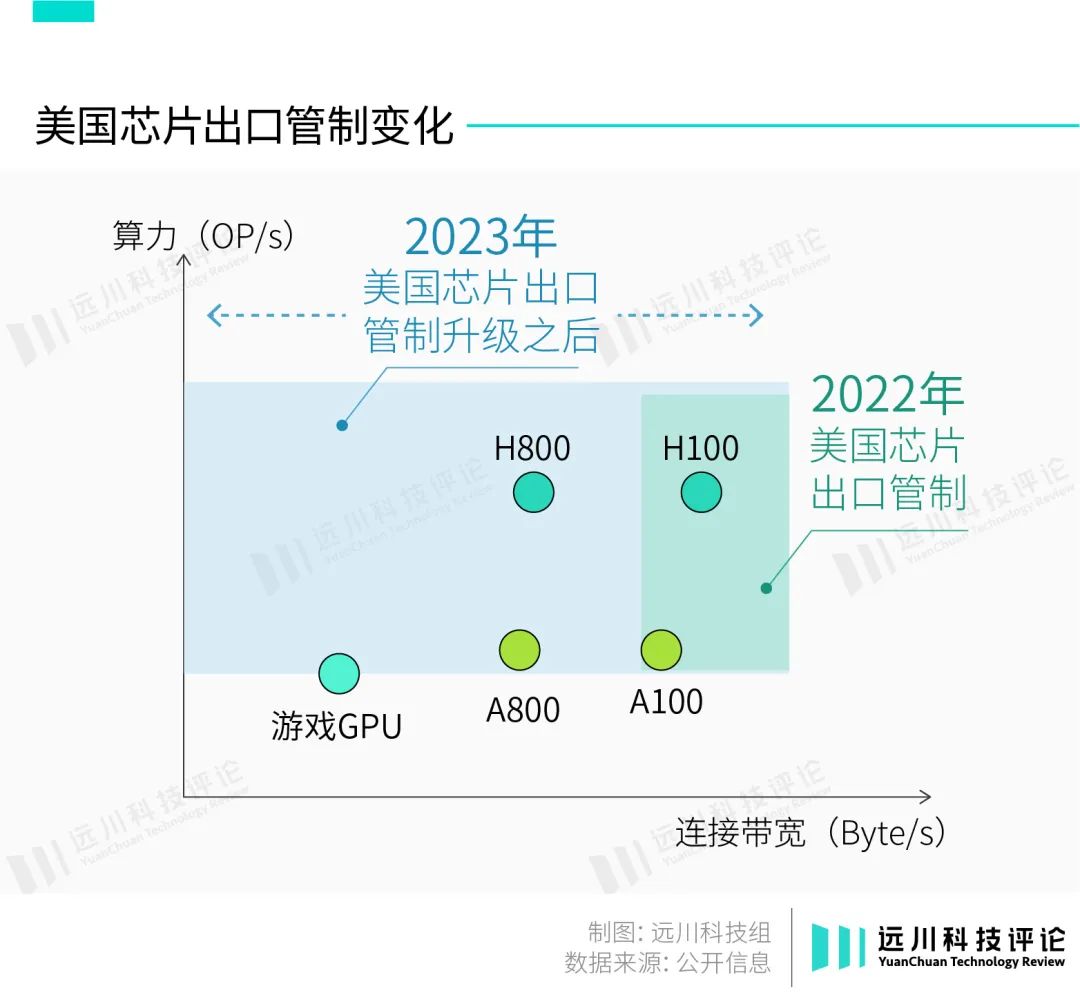
然而,美国依然在10月17日更新了芯片出口管制,中国特供版芯片H800和A800也被列入禁售范围。更令人惊讶的是,用于游戏的消费级显卡RTX 4090也进了名单。
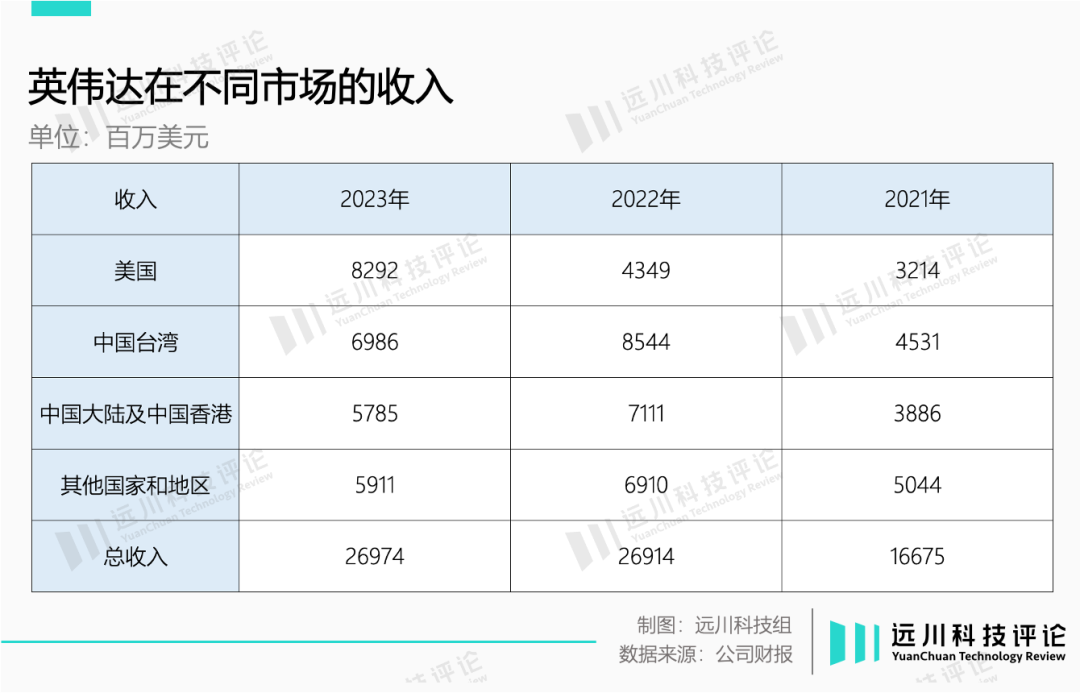
这对英伟达来说无疑是致命一击,长期以来,中国大陆市场一直占据其20%以上的收入。10月17日出口管制发布当天,英伟达股价下跌近5%,AMD和英特尔也跟风跌了1%。
那么,英伟达是否真的无法替代?中国市场之于英伟达又意味着什么?
最好的选择
简单来说,美国政府在新的出口管制政策中添加了多个新指标,不仅把特供产品H800和A800牢牢卡死,还顺便误伤了消费级显卡RTX4090,搞得国内黄牛趁机涨了一波价。
为什么说是“误伤”?虽然RTX4090和p00都是GPU,但两者的设计思路截然不同。
比如,RTX4090的频率强于p00,因为更高的频率能够提供更强的图形渲染能力。而p00的强项则是理论算力、显存大小和显存带宽,这是因为AI推理和训练都非常考验数据的吞吐效率,这也是为什么p00需要昂贵的HBM3内存。
至于玩游戏,p00甚至都不支持主流游戏的图形接口。这也符合英伟达官方的“消费类”和“计算类”归类。
在一些讨论中,RTX 4090由于更低的价格、不差的算力、更低的功耗,一度被认为同样可以用于高性能计算。
客观地说——铁了心也能用。但一般而言,RTX 4090由于显存和带宽的限制,最多只能用作推理芯片。
AI芯片根据部署位置区分,大致上可分为云端芯片和终端芯片。云端芯片用于训练模型,俗称训练芯片;终端芯片用于终端设备,根据训练好的模型对实时数据执行推理任务,俗称推理芯片。
职责不同,导致对训练芯片和推理芯片的性能要求也有很大差异:
训练芯片需要通过海量数据训练可靠的模型,因此对数据传输速率、算力等指标有相当极端的要求。这也是为什么p00不惜用上昂贵的HBM内存和CoWoS封装,目的都是为了数据吞吐效率。
“特供版”的H800和A100,阉割的也是内存带宽,算力其实没有变化。
推理芯片一般处理实时任务,对于低延迟的要求更高,而且由于部署在终端,还要考虑功耗、大小、成本等问题。因此,用RTX4090这类消费级显卡强行训练,过低的带宽会带来“内存墙”的问题。
无论是谷歌的TPU、还是特斯拉的FSD芯片,大部分应用场景都是推理。大部分国产AI芯片,也都是走推理芯片的路子。
而在训练芯片这个场景下,英伟达的确是目前最好的选择。
从绝对的算力来讲,p00并不是巅峰。但在AI训练这件事上,一口气买几百块显卡的科技公司更在意的是另一个指标:单位成本的算力。
这也是为什么大家宁愿加价抢p00,也不愿意买“青春版p00”A100:按照p00 SXM版本、A100 80GB SXM版本8月的销售价格(24000美元、15000美元)计算,每单位算力的成本分别为12.13美元、24.04美元,p00 SXM优势明显。
另外,数据中心搭建完成后,还需要考虑电力、运维、故障、后期支持等多方面成本。种种因素叠加,大家还是老老实实地拿起了号码牌,加入了漫长的p00等待序列中。
比如特斯拉,前脚宣布给自研的Dojo超级计算机投10亿美元,后脚就透露要购买10000张p00用于驱动AI负载。
简而言之,在推理场景下,英伟达尚有替代方案;但在训练芯片里,英伟达是事实上的唯一方案。
原因在于,英伟达真正的护城河,是软件。
今年10月10日,AMD宣布打算收购一家名为Nod.ai的AI开源软件初创公司,以补足其软件短板。
虽然贵为GPU行业的世界第二,但长期以来AMD的市场份额只能和英伟达二八开,在以AI为代表的高性能计算市场,存在感就几乎为0。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

