

云巨头「站队」AI独角兽
文章来源:光锥智能
文:郝鑫
编:王一粟

图片来源:由无界 AI生成
226天、7个多月后,头部的国产通用大模型已陆续突破了GPT3.5的基准线。
近日,腾讯混元大模型升级,称中文能力整体超过GPT3.5;百度发布文心大模型4.0,表示综合水平与GPT4相比已经毫不逊色;商汤“商量SenseChat2.0”测评表现均领先ChatGPT,部分已十分接近GPT4的水平;科大讯飞发布“讯飞星火”认知大模型V3.0,宣布已全面对标GPT3.5。
“国内(大模型)在GPT3.5这条线都过了,但要理性看待。所谓的超过,可能要基于各自平台和局部的指标,比如利用腾讯混元大模型在广告行业,生成的图片风格、采用率等就小胜GPT4”,腾讯机器学习平台算法负责人康战辉,在腾讯混元大模型升级媒体交流会现场的自我评价,一如既往地非常克制。
当技术逐渐拉齐,除了继续追赶GPT4的步伐,从实验室走向千行百业,一些过去曾被忽视的问题也随之浮出水面:
不计成本,大力出奇迹、扩大参数的暴力路径走不通后,如何才能用较少的成本,达到原来同等或近似的训练、推理效果?
千亿级的大模型和70亿、50亿的中小模型,通用大模型和行业模型、业务场景模型,如何才能优势最大化?
总之,走出象牙塔的大模型,需要在效果、成本支出、商业化三方面,找寻到平衡点。
以上种种问题的答案,或许能从腾讯混元大模型的此次升级中得以一窥。既从一开始的大模型框架底座层去优化设计,并提升推理、训练、数学、代码、文生图等基础能力,也在广告、游戏、会议、文档等优势业务场景实践中摸索。
与其他的大模型相比,腾讯混元是算法与工程优化两条腿走路,底层大模型的能力固然很重要,但在业务场景倒逼出来的实践,更加实用。
新增“文生图” 混元大模型迈向多模态
9月7日,2023腾讯全球数字生态大会上,混元大模型初次亮相。
仅一个月过后,腾讯混元大模型迎来重要升级。中文能力整体超过GPT3.5,其中代码能力处理水平提升超过20%,代码处理效果胜出ChatGPT 6.34%,数学能力较老版效果提升15%。
最为重要的是,此次腾讯还推出了自研混元文生图算法模型,给混元增加了“文生图”的能力。
“文生图”是混元大模型向多模态探索的第一步,也是关键的一步。据光锥智能实测,相比其他大模型,混元大模型在人像真实感、场景真实感上有比较明显的优势,同时,在中国风景、动漫游戏等场景生成上有较好的表现。

(混元大模型生成)
据腾讯混元大模型文生图技术负责人芦清林介绍,文生图算法有三个难点:
一是,能不能把想输入的文本准确地生成出来,并用图片来表达,比如能否理解中文语境中的“女娲补天”;
二是,怎样能让生成图片的构图更加合理;
三是,生成的质感和细节是否足够丰富。
为了解决以上的难点,混元从0到1自研了一个文生图模型结构。
该结构不同于市面上流行的“一步到位”模型,而是将文生图分解为了三部分,第一部分是跨模态的预训练大模型,专门做图文对齐,保障输入文字编码、解码语义准确;第二部分是基于像素空间扩散的生成主模型,通过逐步去噪,来还原图片,并生成小图;第三部分是影空间的超生模型,也是混元区别于市面上SD主流文生图的地方,把之前的小图进一步扩展成大图,保证最终生成后的纹理和质感。

腾讯官方透露,该能力已运用到了广告业务场景中,腾讯混元文生图的案例优秀率和广告主采纳率分别达到86%和26%,均高于同类模型。
与走精专路线的Midjourney相比,在广告场景下,腾讯混元众测goodcase率比Midjourney高16%,广告主测评采纳率高48%。且广告主也普遍反映,混元生成的广告素材也更接近投放的场景构图和质感要求。

除了文生图,能让“程序员干掉程序员”的代码能力的升级也是重要的一块儿,分为两个具体方向:
一方面支持自然语言和多种程序语言生成代码。
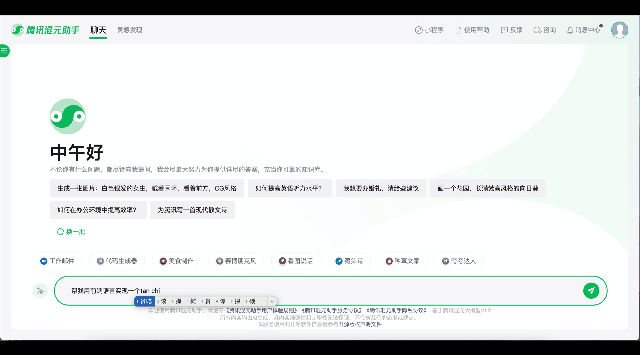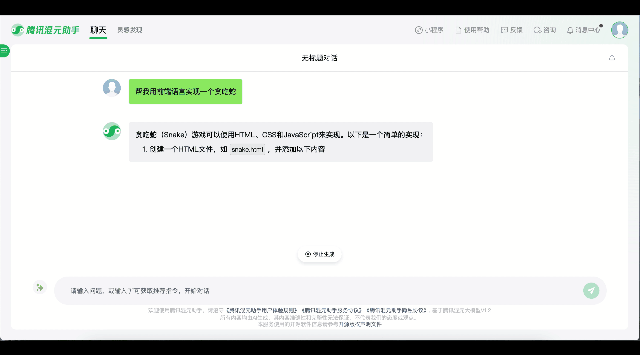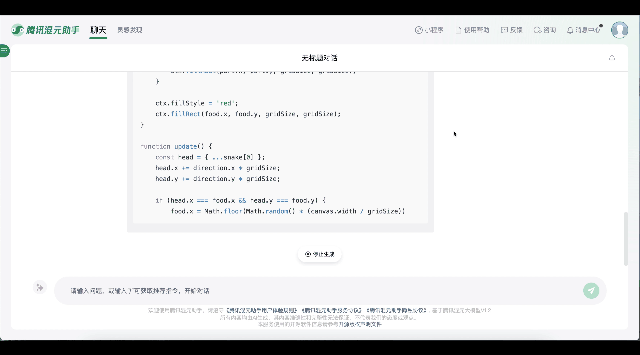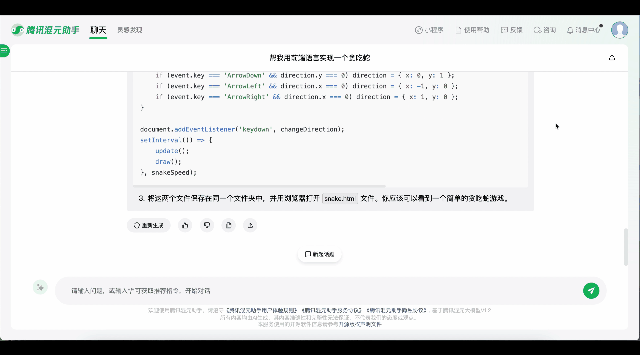
比如只需输入简单的指令“帮我用前端语言实现一个贪吃蛇”,腾讯混元便能自动生成可运行的代码,快速制作出一个贪吃蛇小游戏;还支持Python、C++、Java、Javascript等多种语言的指令生成,比如输入“用Python画红色的心形线”,腾讯混元会提供代码库选择、安装命令、绘制代码等具体操作步骤的指引。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

