

破局利刃!英伟达合成数
文章来源:新智元

图片来源:由无界 AI生成
全球最长上下文窗口来了!今日,百川智能发布Baichuan2-192K大模型,上下文窗口长度高达192K(35万个汉字),是Claude 2的4.4倍,GPT-4的14倍!
长上下文窗口领域的新标杆,来了!
今天,百川智能正式发布全球上下文窗口长度最长的大模型——Baichuan2-192K。
与以往不同的是,此次模型的上下文窗口长度高达192K,相当于约35万个汉字。
再具体点,Baichuan2-192K能够处理的汉字是GPT-4(32K上下文,实测约2.5万字)的14倍,Claude 2(100K上下文,实测约8万字)的4.4倍,可以一次性读完一本《三体》。

Claude一直以来保持的上下文窗口记录,在今天被重新刷新
把三体第一部《地球往事》丢给它,Baichuan2-192K稍加咀嚼,便立刻对整个故事了如指掌。
汪淼看到的倒计时里第36张照片上的数字是多少?答:1194:16:37。 他使用的相机是什么型号?答:徕卡M2。他和大史一共喝过几次酒?答:两次。

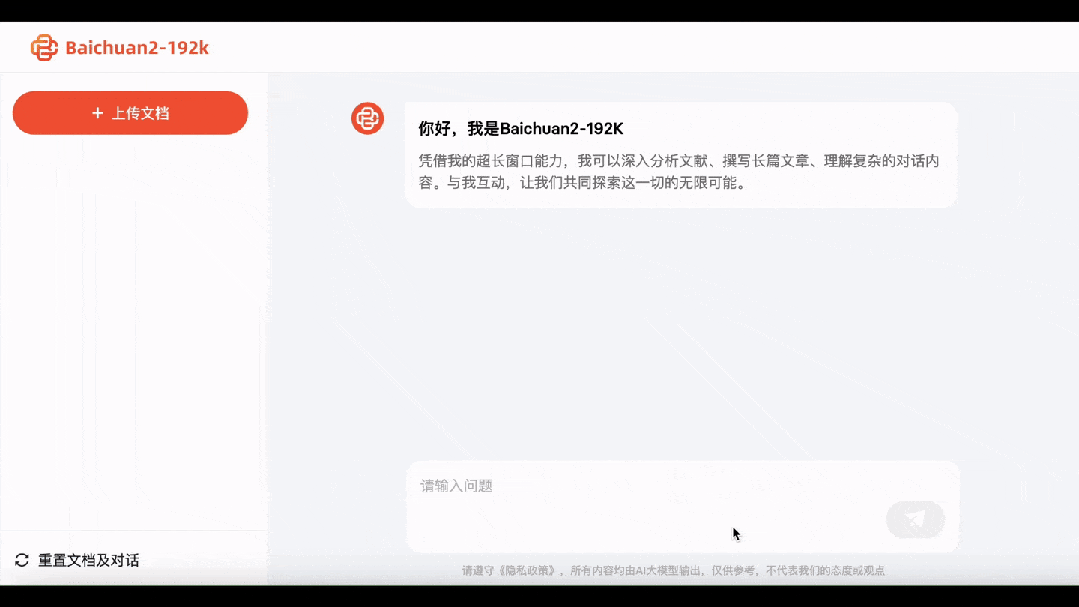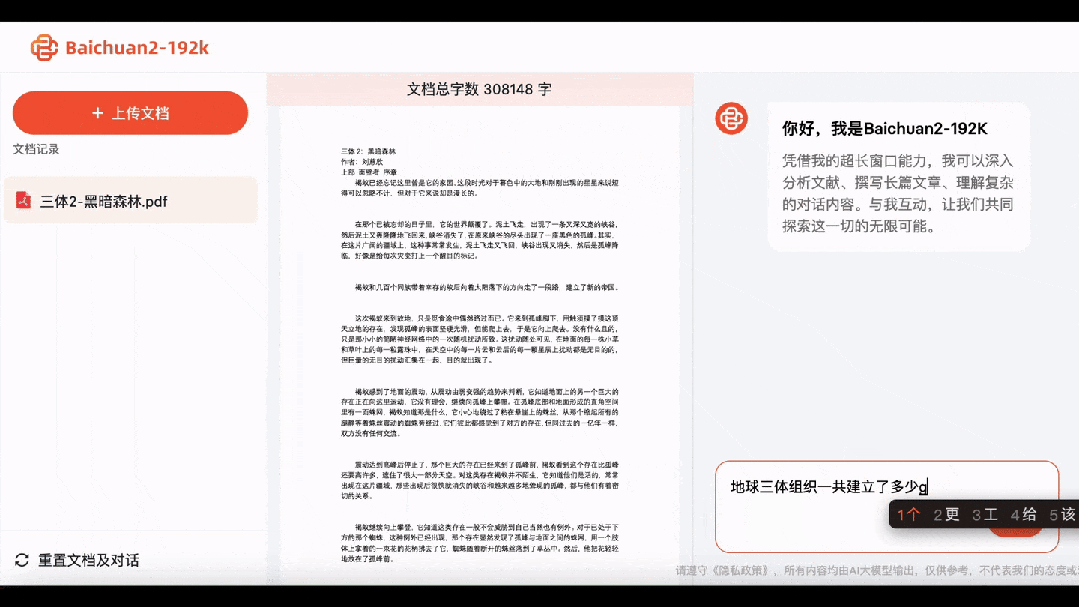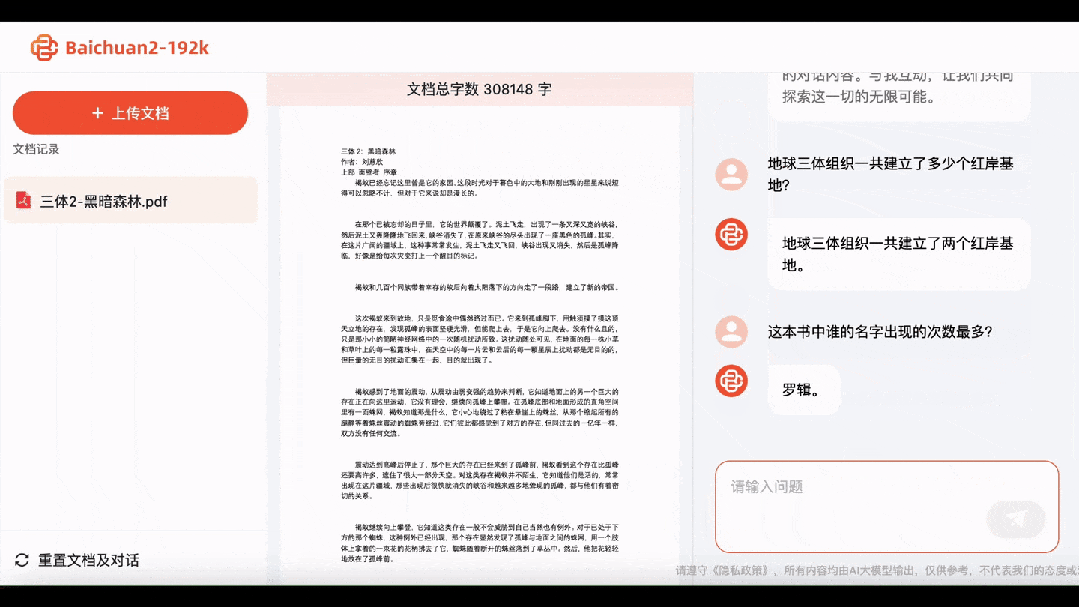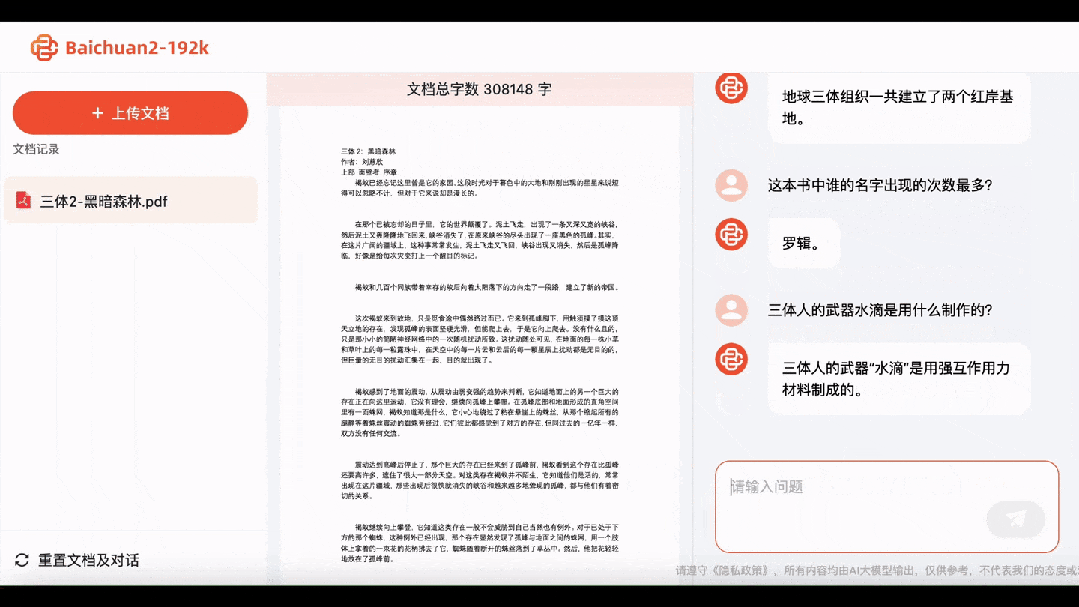
再看看第二部《黑暗森林》,Baichuan2-192K不仅一下就答出了地球三体组织建立了两个红岸基地,「水滴」是由强互作用力材料制作的。
而且,就连「三体十级学者」都未必能答上来的冷门问题,Baichuan2-192K也是对答如流,信手拈来。
谁的名字出现次数最多?答:罗辑。
可以说,当上下文窗口扩展到了35万字,大模型的使用体验,仿佛忽然打开了一个新世界!
全球最长上下文,全面领先Claude 2
大模型,会被什么卡脖子?
以ChatGPT为例,虽然能力让人惊叹,然而这个「万能」模型却有一个无法回避的掣肘——最多只支持32K tokens(2.5万汉字)的上下文。而律师、分析师等职业,在大部分的时间里需要处理比这长得多的文本。

更大的上下文窗口,可以让模型从输入中获得更丰富的语义信息,甚至直接基于全文理解进行问答和信息处理。
由此,模型不仅能更好地捕捉上下文的相关性、消除歧义,进而更加精准地生成内容,缓解「幻觉」问题,提升性能。而且,也可以在长上下文的加持下,与更多的垂直场景深度结合,真正在人们的工作、生活、学习中发挥作用。
最近,硅谷独角兽Anthropic先后获得亚马逊投资40亿、谷歌投资20亿。能获得两家巨头的青睐,当然跟Claude在长上下文能力技术上的领先不无关系。
而这次,百川智能发布的Baichuan-192K长窗口大模型,在上下文窗口长度上远远超过了Claude 2-100K,而且在文本生成质量、上下文理解、问答能力等多个维度的评测中,也取得了全面领先。
10项权威评测,拿下7个SOTA
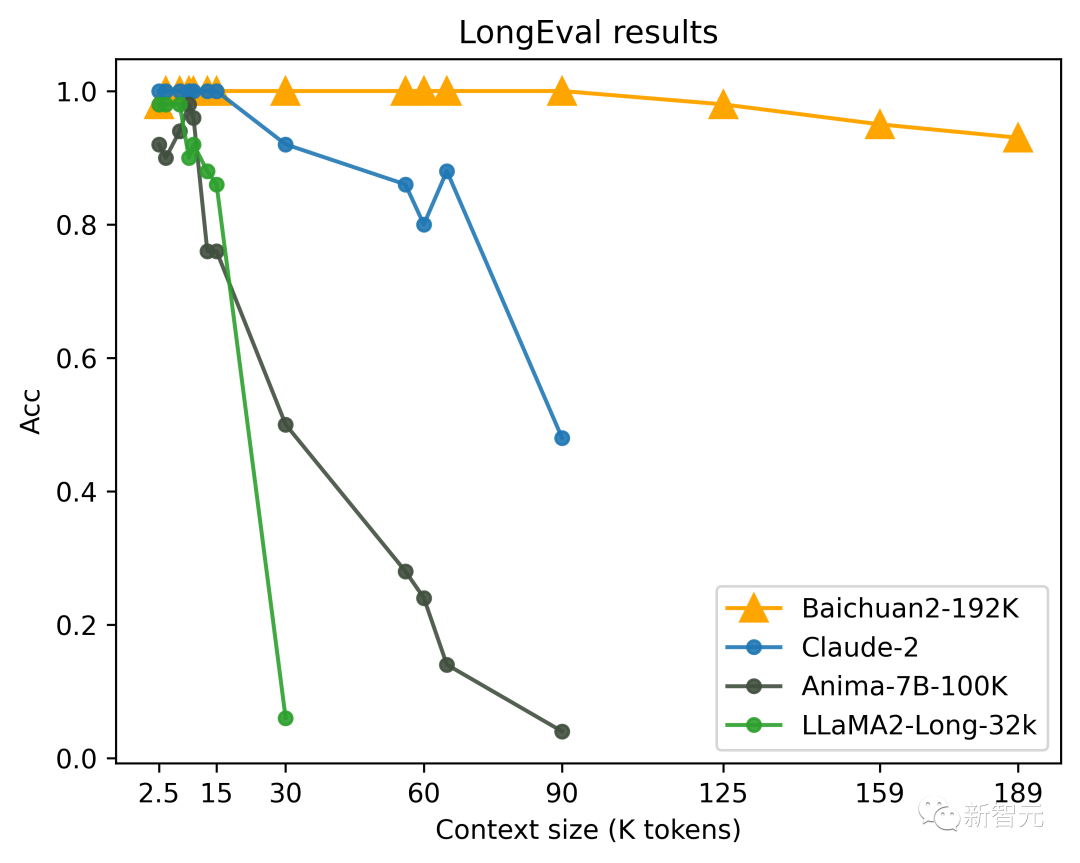
LongEval是由加州大学伯克利分校联合其他高校发布的针对长窗口模型评测的榜单,主要衡量模型对长窗口内容的记忆和理解能力。
上下文理解方面,Baichuan2-192K在权威长窗口文本理解评测榜单LongEval上大幅领先其他模型,窗口长度超过100K后依然能够保持非常强劲的性能。
相比之下,Claude 2窗口长度超过80K后整体效果下降非常严重。
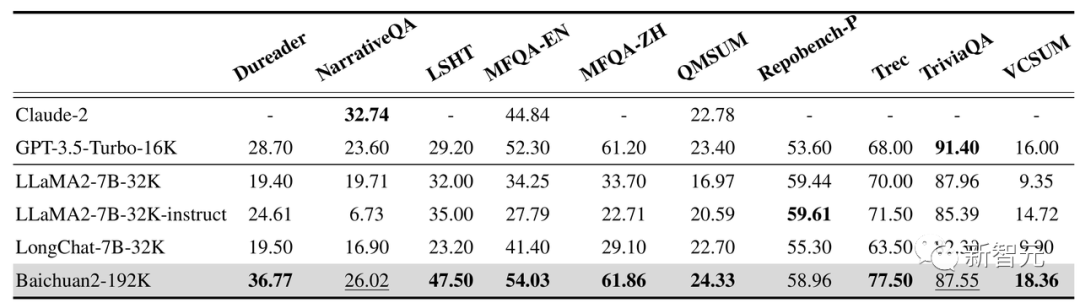
此外,Baichuan2-192K在Dureader、NarrativeQA、LSHT、TriviaQA等10项中英文长文本问答、摘要的评测集上表现同样优异。
其中,有7项取得了SOTA,性能显著超过其他长窗口模型。
在文本生成质量方面,困惑度是一个非常重要的标准。
可以简单理解为,将符合人类自然语言习惯的高质量文档作为测试集时,模型生成测试集中文本的概率越高,模型的困惑度就越小,模型也就越好。
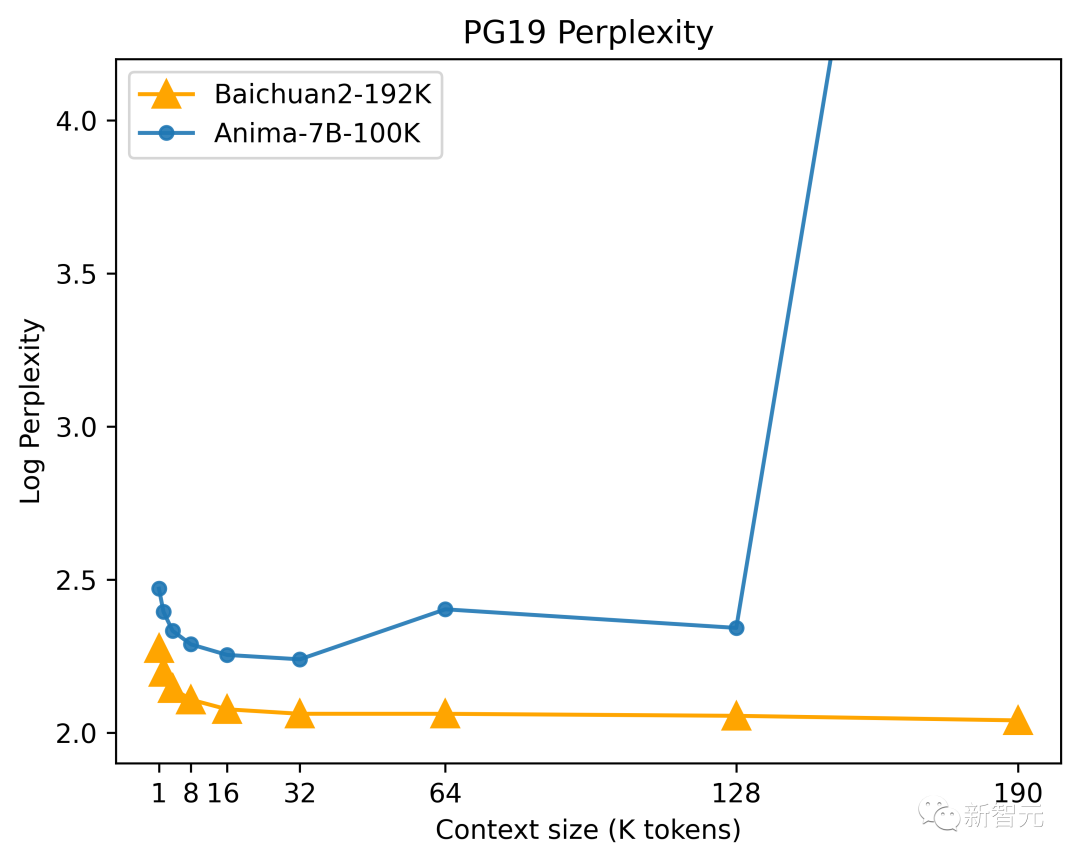
根据DeepMind发布的「语言建模基准数据集PG-19」的测试结果,Baichuan2-192K的困惑度在初始阶段便很优秀,并且随着窗口长度扩大,Baichuan2-192K的序列建模能力也持续增强。
工程算法联合优化,长度性能同步提升
虽然长上下文可以有效提升模型性能,但超长的窗口也意味着需要更强的算力,以及更多的显存。
目前,业界普遍的做法是滑动窗口、降低采样、缩小模型等等。
然而,这些方式都会在不同程度上,牺牲模型其他方面的性能。
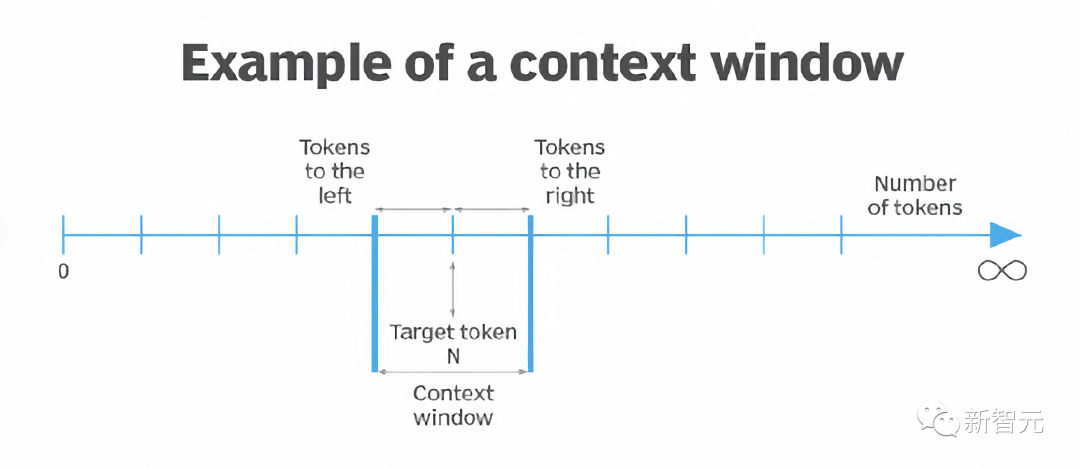
为了解决这一问题,Baichuan2-192K通过算法和工程的极致优化,实现了窗口长度和模型性能之间的平衡,做到了窗口长度和模型性能的同步提升。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

