

破局利刃!英伟达合成数
习惯了 Stable Diffusion,如今终于又迎来一个俄罗斯套娃式(Matryoshka)Diffusion 模型,还是苹果做的。
原文来源:机器之心

图片来源:由无界 AI生成
在生成式 AI 时代,扩散模型已经成为图像、视频、3D、音频和文本生成等生成式 AI 应用的流行工具。然而将扩散模型拓展到高分辨率领域仍然面临巨大挑战,这是因为模型必须在每个步骤重新编码所有的高分辨率输入。解决这些挑战需要使用带有注意力块的深层架构,这使得优化更困难,消耗的算力和内存也更多。
怎么办呢?最近的一些工作专注于研究用于高分辨率图像的高效网络架构。但是现有方法都没有展示出超过 512×512 分辨率的效果,并且生成质量落后于主流的级联或 latent 方法。
我们以 OpenAI DALL-E 2、谷歌 IMAGEN 和英伟达 eDiffI 为例,它们通过学习一个低分辨率模型和多个超分辨率扩散模型来节省算力,其中每个组件都单独训练。另一方面,latent 扩散模型(LDM)仅学习低分辨率扩散模型,并依赖单独训练的高分辨率自编码器。对于这两种方案,多阶段式 pipeline 使训练与推理复杂化,从而往往需要精心调整或进行超参。
本文中,研究者提出了俄罗斯套娃式扩散模型(Matryoshka Diffusion Models,MDM)它是用于端到端高分辨率图像生成的全新扩散模型。代码很快将释出。

论文地址:https://arxiv.org/pdf/2310.15111.pdf
该研究提出的主要观点是将低分辨率扩散过程作为高分辨率生成的一部分,通过使用嵌套 UNet 架构在多个分辨率上执行联合扩散过程。
该研究发现:MDM 与嵌套 UNet 架构一起实现了 1)多分辨率损失:大大提高了高分辨率输入去噪的收敛速度;2)高效的渐进式训练计划,从训练低分辨率扩散模型开始,按照计划逐步添加高分辨率输入和输出。实验结果表明,多分辨率损失与渐进式训练相结合可以让训练成本和模型质量获得更好的平衡。
该研究在类条件图像生成以及文本条件图像和视频生成方面评估了 MDM。MDM 让训练高分辨率模型无需使用级联或潜在扩散(latent diffusion)。消融研究表明,多分辨率损失和渐进训练都极大地提高了训练效率和质量。
我们来欣赏以下 MDM 生成的图片和视频。


方法概览
研究者介绍称,MDM 扩散模型在高分辨率中进行端到端训练,同时利用层级结构的数据形成。MDM 首先在扩散空间中泛化了标准扩散模型,然后提出了专用的嵌套架构和训练流程。
首先来看如何在扩展空间对标准扩散模型进行泛化。
与级联或 latent 方法的不同之处在于,MDM 通过在一个扩展空间中引入多分辨率扩散过程,学得了具有层级结构的单个扩散过程。具体如下图 2 所示。
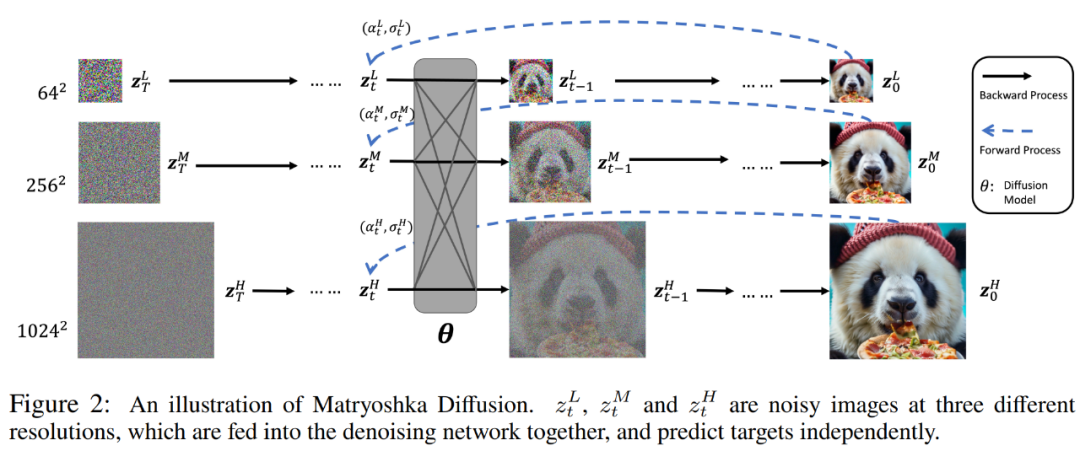
具体来讲,给定一个数据点 x ∈ R^N,研究者定义了与时间相关的隐变量 z_t = z_t^1 , . . . , z_t^R ∈ R^N_1+...NR。
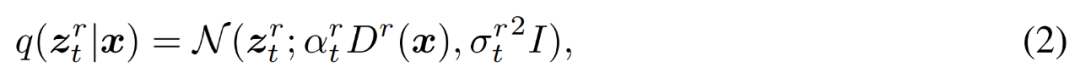
研究者表示,在扩展空间中进行扩散建模有以下两点优点。其一,我们在推理期间通常关心全分辨率输出 z_t^R,那么所有其他中等分辨率被看作是额外的隐变量 z_t^r,增加了建模分布的复杂度。其二,多分辨率依赖性为跨 z_t^r 共享权重和计算提供了机会,从而以更高效的方式重新分配计算,并实现高效训练和推理。
接下来看嵌套架构(NestedUNet)如何工作。
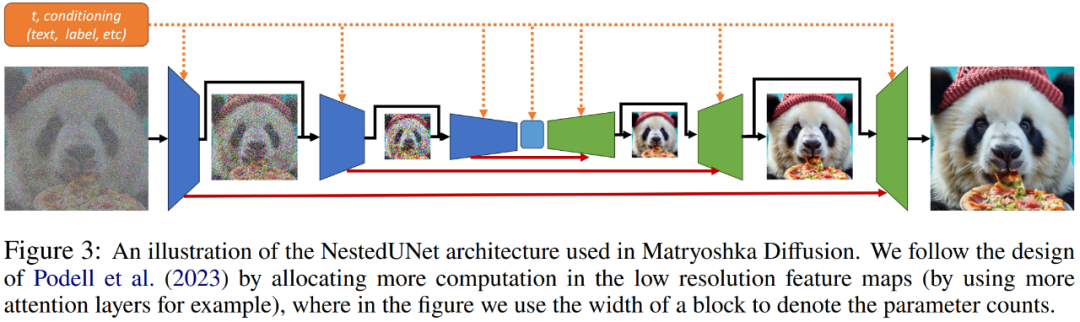
与典型的扩散模型类似,研究者使用 UNet 网络结构来实现 MDM,其中并行使用残差连接和计算块以保留细粒度的输入信息。这里的计算块包含多层卷积和自注意力层。NestedUNet 与标准 UNet 的代码分别如下。

除了相较于其他层级方法的简单性,NestedUNet 允许以最高效的方式对计算进行分配。如下图 3 所示,研究者早期探索发现,当以最低分辨率分配大部分参数和计算时,MDM 实现了明显更好的扩展性。
最后是学习。
研究者使用常规去噪目标在多个分辨率下训练 MDM,如下公式 (3) 所示。
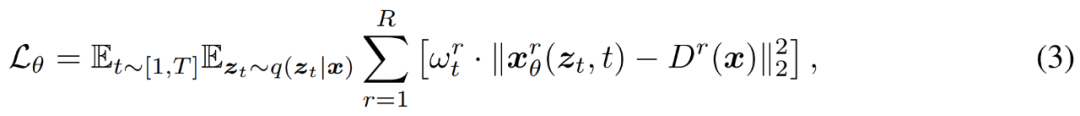
这里用到了渐进式训练。研究者按照上述公式 (3) 直接对 MDM 进行端到端训练,并展示出了比原始基线方法更好的收敛性。他们发现,使用类似于 GAN 论文中提出的简单渐进式训练方法,极大地加速了高分辨率模型的训练。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

