

AI 大语言模型 LLM,为啥老
原文来源:量子位

图片来源:由无界 AI生成
百模大战,最备受期待的一位选手,终于正式亮相!
它便是来自李开复博士创办的AI 2.0公司零一万物的首款开源大模型——Yi系列大模型:
Yi-34B和Yi-6B。

虽然Yi系列大模型出道时间相对较晚,但从效果上来看,绝对称得上是后发制人。
一出手即问鼎多项全球第一:
值得注意的是,零一万物及其大模型并非是一蹴而就,而是酝酿了足足半年有余。
由此不免让人产生诸多疑问:
例如为什么要憋半年之久的大招,选择在临近岁末之际出手?
再如是如何做到一面世即能拿下如此之多的第一?
带着这些问题,我们与零一万物做了独家交流,现在就来一一揭秘。
击败千亿参数大模型
具体来看,零一万物最新发布开源的Yi系列大模型主要有两大亮点:
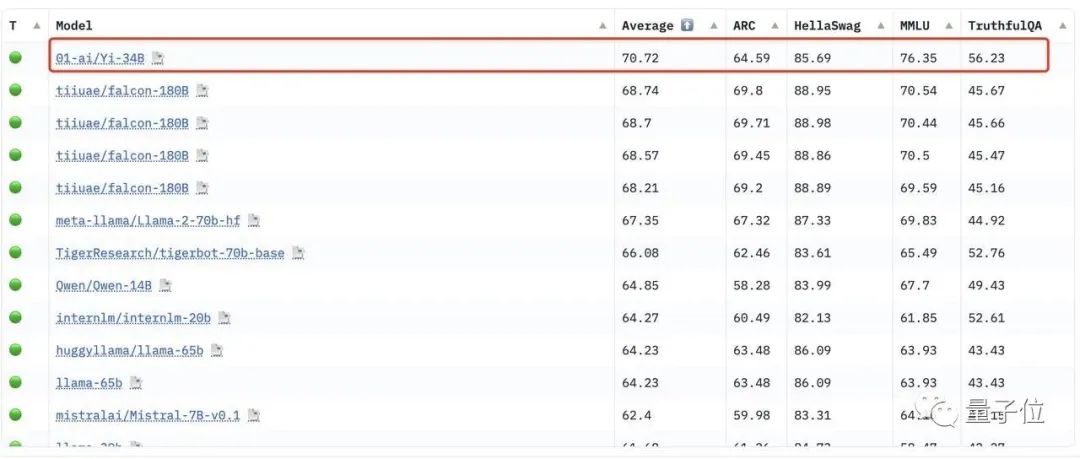
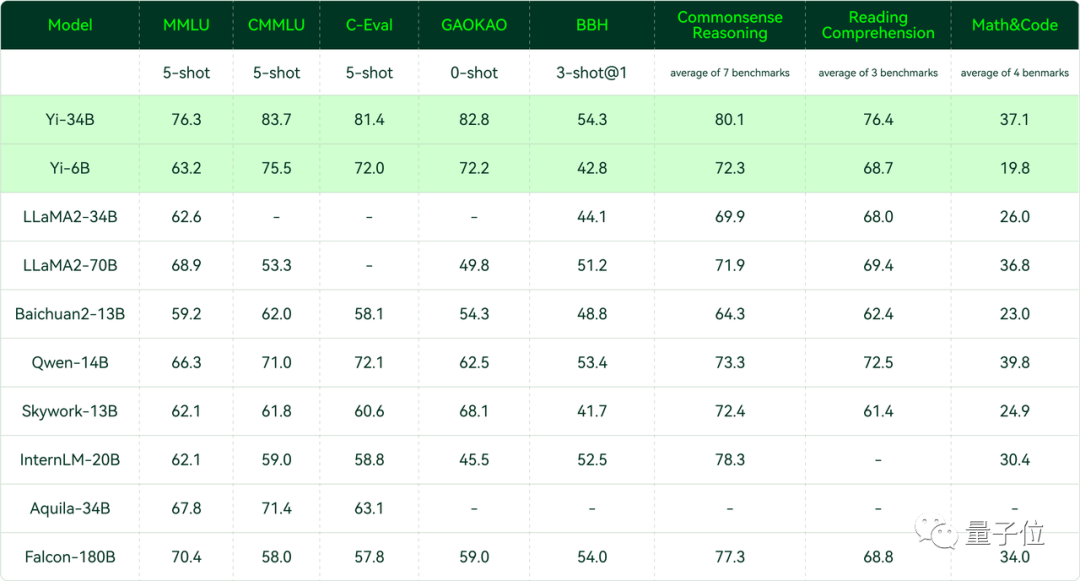
在Hugging Face英文测试公开单 Pretrained 预训练开源模型排名中,Yi-34B以70.72分数位列全球第一,超过了LLaMA-70B和Falcon-180B。
要知道,Yi-34B的参数量仅为后两者的1/2、1/5。不仅“以小博大”问鼎榜单,而且实现了跨数量级的反超,以百亿规模击败千亿级大模型。
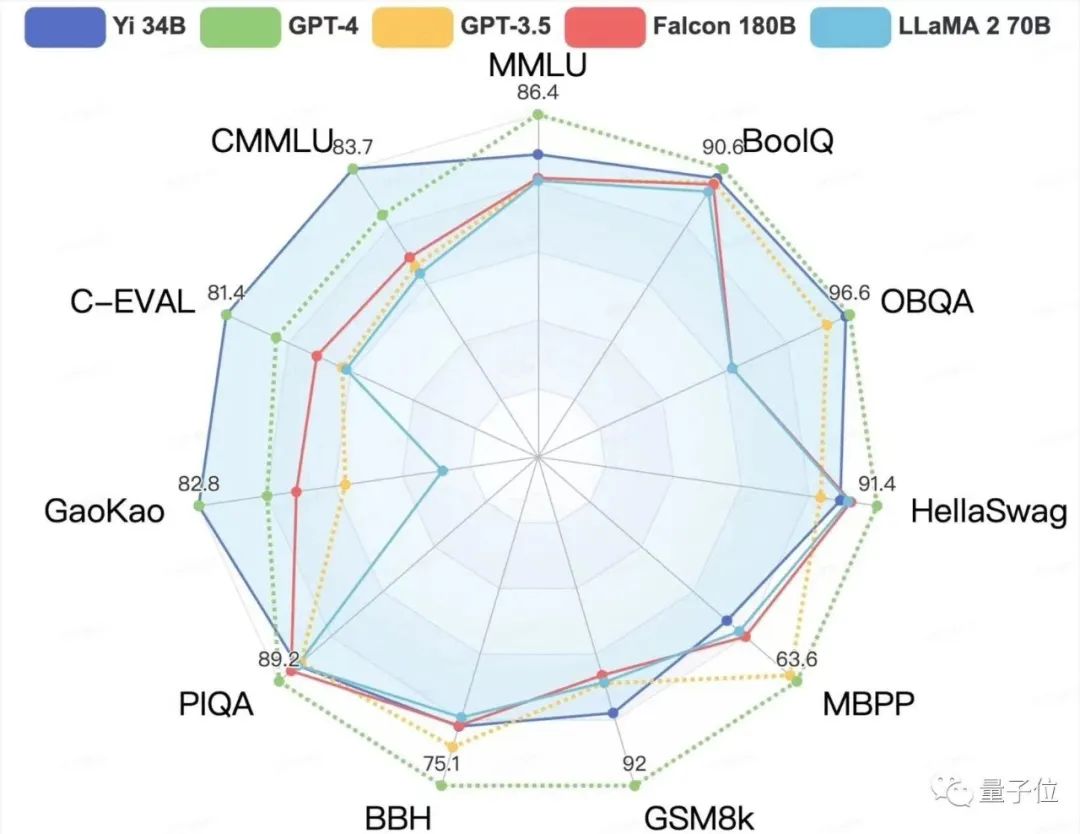
其中在MMLU(大规模多任务语言理解)、TruthfulQA(真实性基准)两项指标中,Yi-34B都大幅超越其他大模型。
聚焦到中文能力方面,Yi-34B在C-Eval中文能力能力排行榜上超越所有开源模型。
同样开源的Yi-6B也超过了同规模所有开源模型。
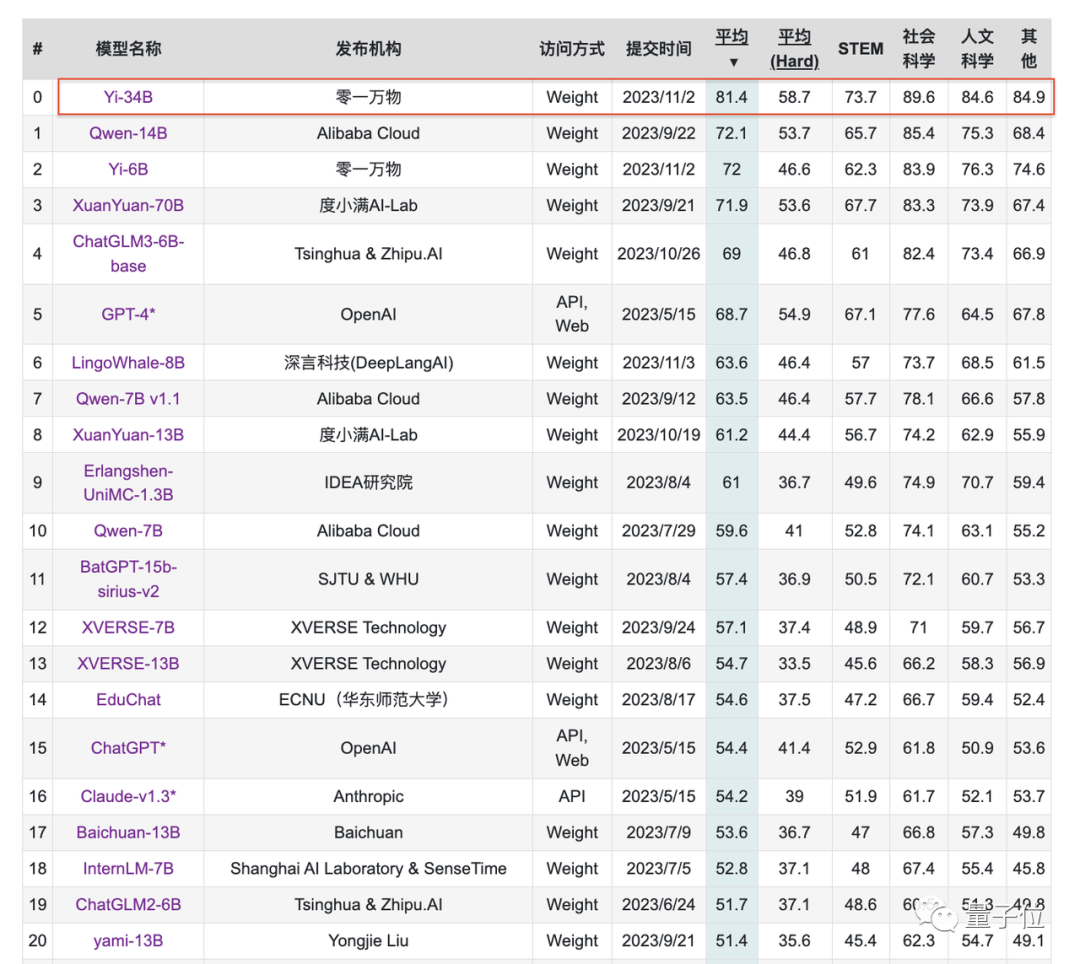
在CMMLU、E-Eval、Gaokao三个主要中文指标上,明显领先于GPT-4,彰显强大的中文优势,对咱们更知根知底

。
在BooIQ、OBQA两个问答指标上,和GPT-4水平相当。
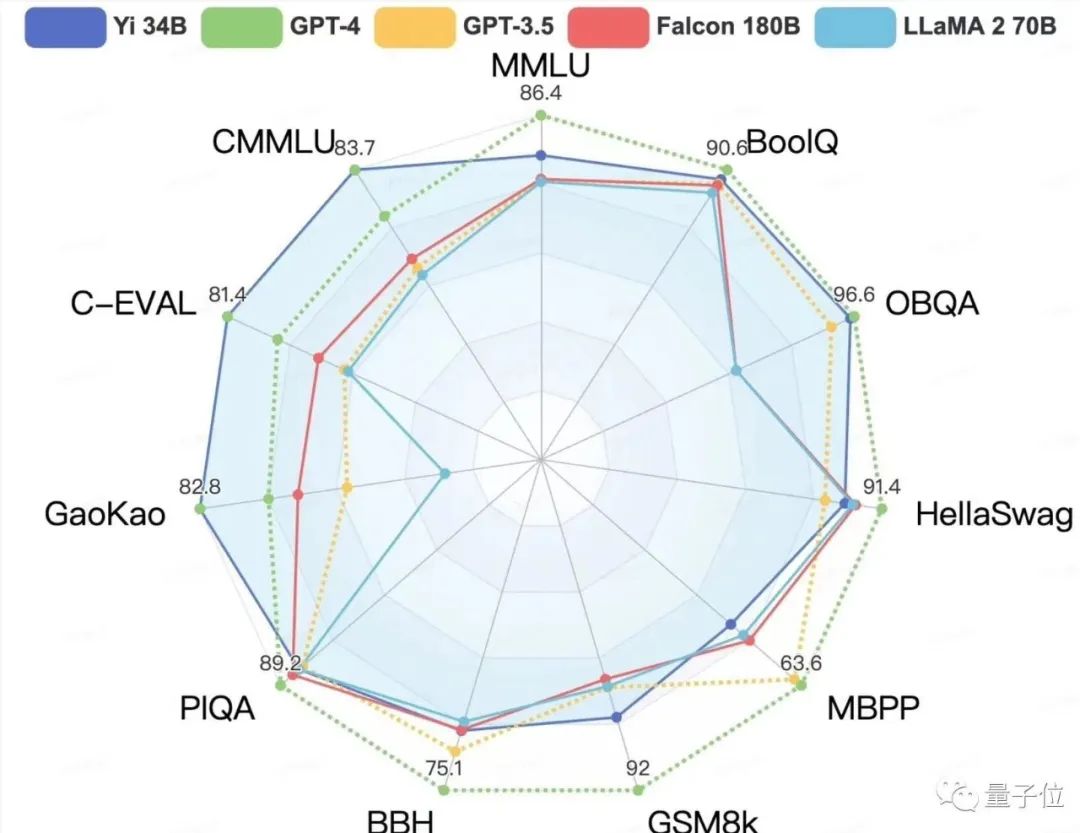
另外,在大模型最关键评测指标MMLU(Massive Multitask Language Understanding,大规模多任务语言理解)、BBH等反映模型综合能力的评测集上,Yi-34B在通用能力、知识推理、阅读理解等多项指标评比中全面超越,与Hugging Face评测高度一致。
不过在发布中零一万物也表示,Yi系列模型在GSM8k、MBPP的数学和代码测评中表现还不及GPT模型。
这是因为团队希望在预训练阶段先尽可能保留模型的通用能力,所以训练数据中没有加入过多数学和代码数据。
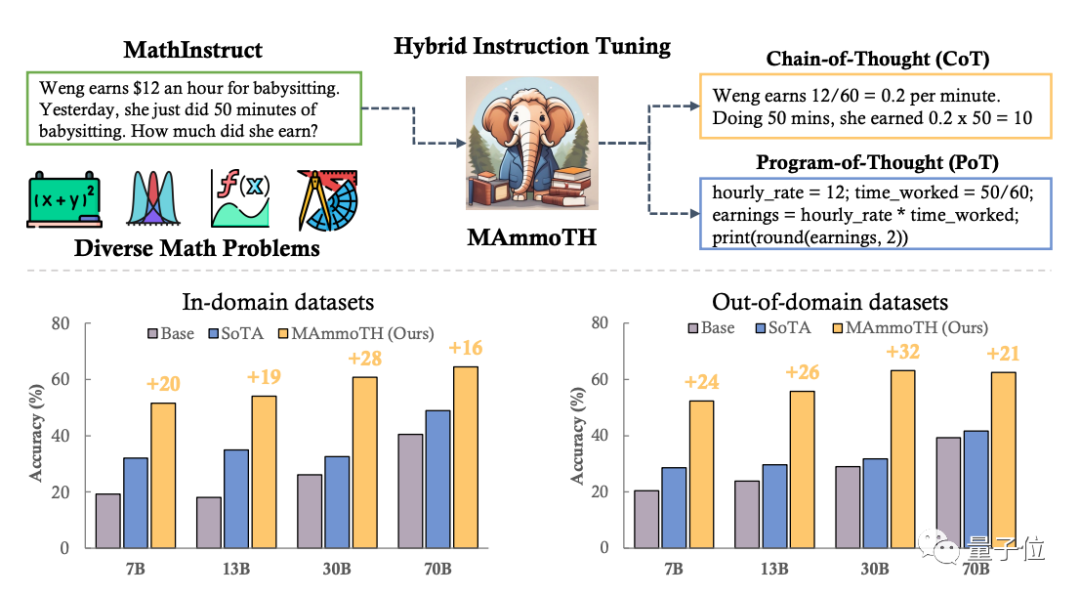
目前团队正在针对数学方向展开研究,提出了可以解决一般数学问题的大模型MammoTH,利用CoT和PoT解决数学问题,在各个规模版本、内外部测试集上均优于SOTA模型。其中MammoTH-34B在MATH上的准确率达到44%,超过了GPT-4的CoT结果。
后续Yi系列也将推出专长代码和数学的继续训练模型。
而除了亮眼的刷榜成绩外,Yi-34B还将大模型上下文窗口长度刷新到了200K,可处理约40万汉字超长文本输入。
这相当于能一次处理两本《三体 1》小说、理解超过1000页的PDF文档,甚至能替代很多依赖于向量数据库构建外部知识库的场景。

超长上下文窗口是体现大模型实力的一个重要维度,拥有更长的上下文窗口则能处理更丰富的知识库信息,生成更连贯、准确的文本,也能支持大模型更好处理文档摘要/问答等任务。
要知道,目前大模型的诸多垂直行业应用中(如金融、法律、财务等),文档处理能力是刚需。
如GPT-4可支持32K、约2.5万汉字,Claude 2可支持100K、约20万字。
零一万物不仅刷新了业界纪录,同时也是首家将超长上下文窗口在开源社区开放的大模型公司。
所以,Yi系列是如何炼成的?
超强Infra+自研训练平台
零一万物表示,Yi系列炼成的秘诀来自两方面:
如上二者结合,能让大模型训练过程更加高效、准确、自动化。在多模混战的当下,节省宝贵的时间、计算、人力成本。
它们是Yi系列大模型为何会“慢”的原因之一,但也因为有了它们,所以“慢即是快”。
首先来看模型训练部分。
这是大模型能力打基础的环节,训练数据质量和方法如何,直接关乎模型最终效果。
所以,零一万物自建了智能数据处理管线和规模化训练实验平台。
智能数据处理管线高效、自动、可评价、可扩展,团队由前Google大数据和知识图谱专家领衔。
“规模化训练实验平台”可以指导模型的设计和优化,提升模型训练效率、减少计算资源浪费。
基于这一平台,Yi-34B每个节点的预测误差都控制在0.5%以内,如数据配比、超参搜索、模型结构实验都可以在上面进行。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

