

金花235(金花235能吃什么
Transformer模型是否能够泛化出新的认知和能力?最近,谷歌的研究人员进行了有关实验,对于这一问题给出了自己的答案。
原文来源:新智元

图片来源:由无界 AI生成
Transformer模型是否能够超越预训练数据范围,泛化出新的认知和能力,一直是学界争议已久的问题。
最近谷歌DeepMind的3位研究研究人员认为,要求模型在超出预训练数据范围之外泛化出解决新问题的能力,几乎是不可能的。
LLM的终局就是人类智慧总和?

论文地址:https://arxiv.org/abs/2311.00871
Jim Fan转发论文后评论说,这明确说明了训练数据对于模型性能的重要性,所以数据质量对于LLM来说实在是太重要了。
研究人员在论文中专注于研究预训练过程的一个特定方面——预训练中使用的数据——并研究它如何影响最终Transformer模型的少样本学习能力。
研究人员使用一组
来作为输入和标签, 来对新输入的
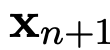
的标签
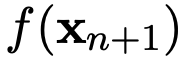
进行预测。要训练模型做出这样的预测,需要在
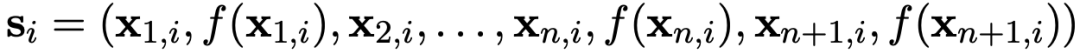
形式的许多序列上拟合模型。
研究人员使用包含多种不同函数类别的混合对Transformer模型进行预训练,以便在上下文中学习,并展示了所表现出的模型选择行为(Model Selection Phenomena)。
他们还研究了预训练Transformer模型在与预训练数据中的函数类别 「不一致 (out-of-distribution)」的函数上的情境学习行为。
通过这种方式,研究人员研究了预训练数据组成与Transformer模型对相关任务进行少量学习的能力之间的相互作用和影响后发现:
1. 在所研究的机制中,有明确的证据表明,模型在上下文学习过程中可以在预训练的函数类别中进行模型选择,而且几乎不需要额外的统计成本。
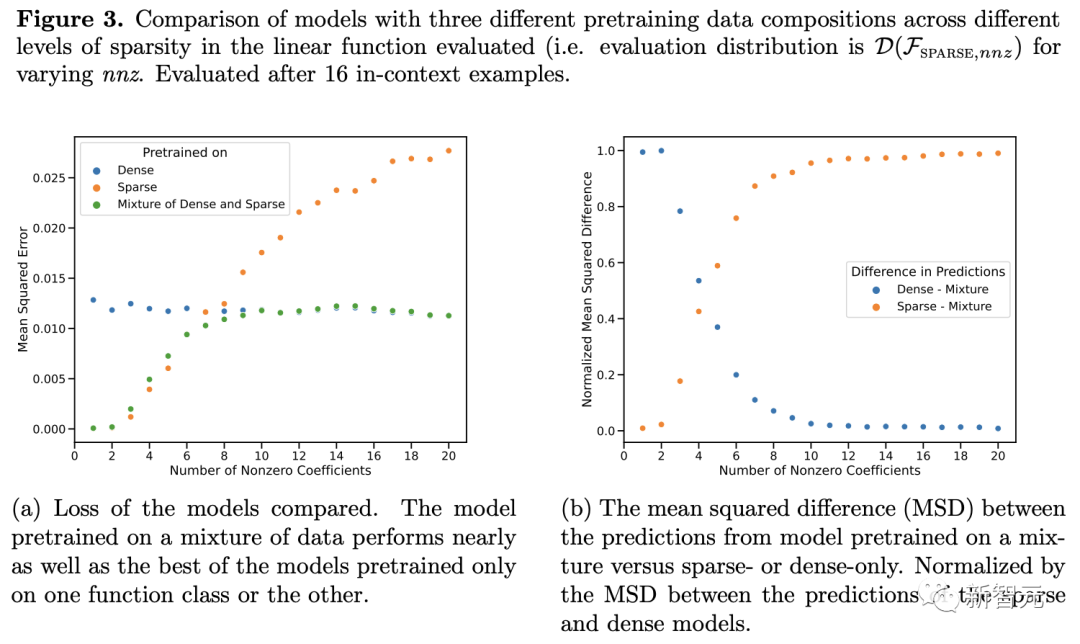
预训练数据中各个稀疏程度的线性函数都被很好地覆盖的情况下,Transformer可以进行近似最优的预测。
2. 但几乎没有证据表明,模型的上下文学习行为能够超出其预训练数据的范围。
当组合函数主要来自一个函数类时,预测合理。当两个类同时显著贡献时,预测失效。
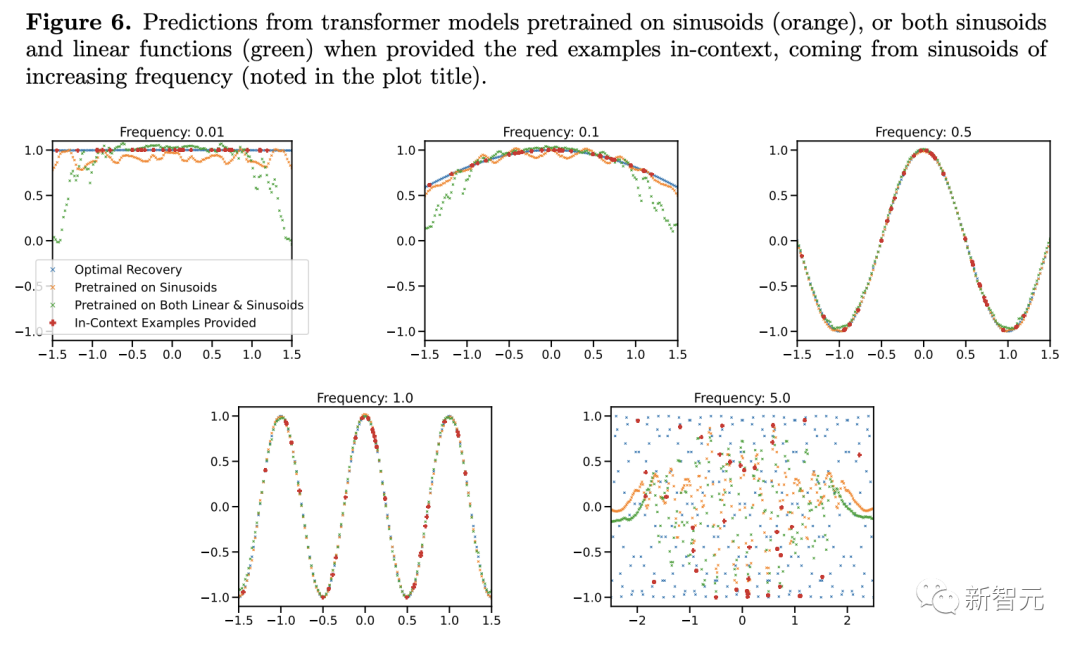
对于预训练数据中极为罕见的高低频正弦函数,模型的泛化会失败。
研究过程细节
首先,为了避免产生误解,这里先声明本实验所采用的模型:类似于GPT-2,包含12层,256维嵌入空间。
之前提到了文章使用不同函数混合的方法进行研究,
那么我们不禁要问:「当提供支持预训练混合的上下文示例时,模型如何在不同的函数类之间进行选择?」
之前的研究表明,在线性函数上预训练的Transformer在对新的线性函数进行上下文学习时表现几乎最优。
于是研究人员采用两个线性模型来进行研究:一个在密集线性函数上训练(其中线性模型的所有系数都是非零的),另一个在稀疏线性函数上训练(假设20个系数中只有2个是非零的)。
每个模型分别对新的密集线性函数和稀疏线性函数执行相应的线性回归和套索回归(Lasso)。此外,还将这两个模型与在稀疏线性函数和密集线性函数的混合上预训练的模型进行了比较。
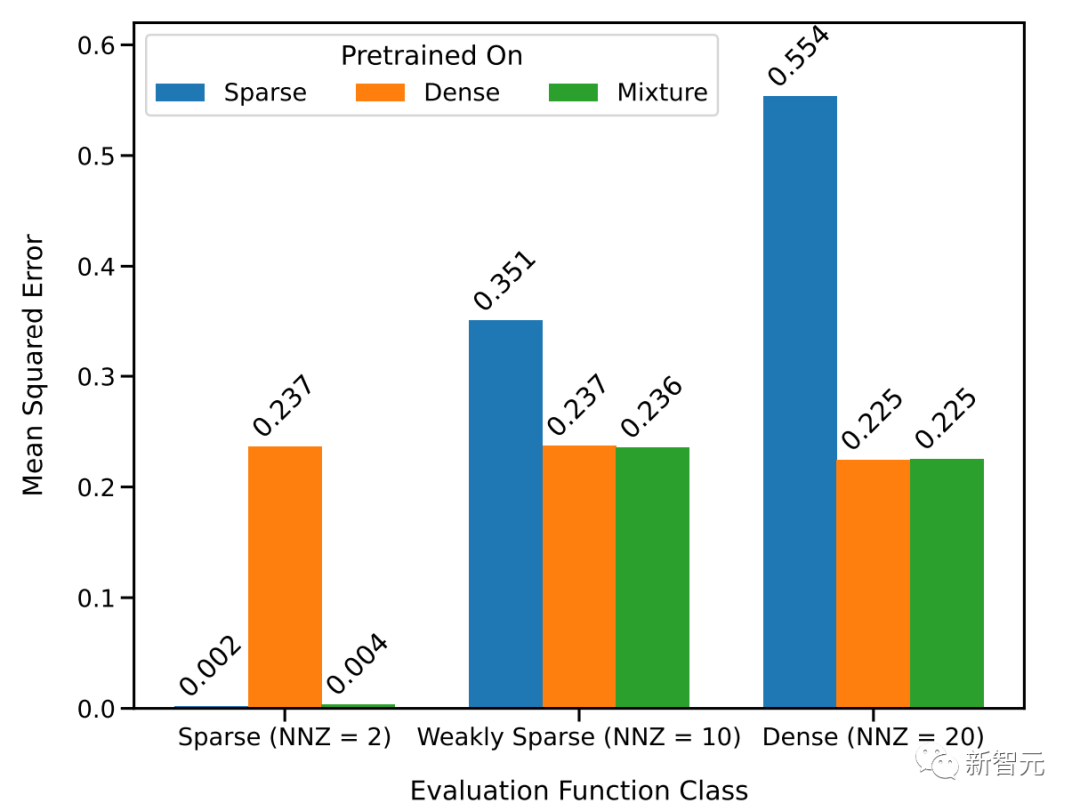
上图显示,在以D(F) = 0.5*D(F1)+0.5*D(F2)的比例混合两个函数的情况下,新的函数在上下文学习中的表现与仅在一个函数类上预训练的模型相似。
而在新的混合函数上预训练的模型与前人研究中所展示的模型(理论上最优)相似,因此可以推断该模型也几乎是最优的。
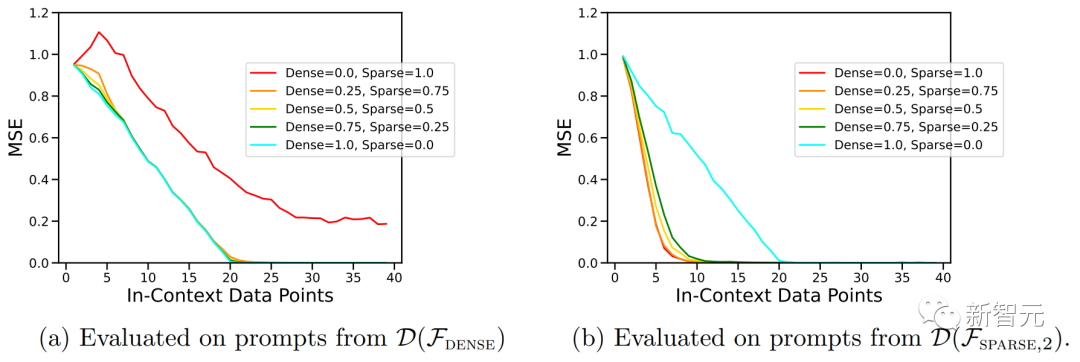
上图中的ICL学习曲线向我们表明,这种上下文模型选择能力相对于提供的上下文示例数量相对一致。
我们还可以看到,与纯粹基于该函数类预训练模型相比,对于给定函数类,这种使用权重来进行预训练数据混合的ICL学习曲线几乎与最佳基线样本复杂度相匹配。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

