

金花235(金花235能吃什么
难道 Transformer 注定无法解决「训练数据」之外的新问题?
原文来源:机器之心

图片来源:由无界 AI生成
说起大语言模型所展示的令人印象深刻的能力,其中之一就是通过提供上下文中的样本,要求模型根据最终提供的输入生成一个响应,从而实现少样本学习的能力。这一点依靠的是底层机器学习技术「Transformer 模型」,并且它们也能在语言以外的领域执行上下文学习任务。
以往的经验表明,对于在预训练混合体中得到充分体现的任务族或函数类,选择适当函数类进行上下文学习的成本几乎为零。因此有研究者认为,Transformer 能很好地泛化与训练数据相同分布的任务 / 函数。然而,一个普遍的悬而未决的问题是:在与训练数据分布不一致的样本上,这些模型表现如何?
在最近的一项研究中,来自 DeepMind 的研究者借助实证研究,对这个问题进行了探讨。他们将泛化问题解释为以下内容:「一个模型能否利用不属于预训练数据混合体中任何基本函数类的函数的上下文样本生成良好的预测?(Can a model generate good predictions with in-context examples from a function not in any of the base function classes seen in the pretraining data mixture? )」
这篇论文重点放在了预训练过程的一个特定方面:「预训练中使用的数据」,并研究它如何影响由此产生的 Transformer 模型的少样本学习能力。为了解决上述问题,研究者首先探讨了 Transformer 在预训练中看到的不同函数类族之间进行模型选择的能力(第 3 节),然后回答了几个重点案例的 OOD 泛化问题(第 4 节)。

论文地址:https://arxiv.org/pdf/2311.00871.pdf
他们发现:首先,预训练 Transformer 在预测从预训练函数类中提取的函数的凸组合时非常吃力;其次,Transformer 虽然可以有效泛化函数类空间中较罕见的部分,但当任务变得不在分布范围内时,Transformer 仍然会崩溃。
归纳为一句话就是,Transformer 无法泛化出预训练数据之外的认知 —— 因此也解决不了认知之外的问题。
总体来说,本文的贡献如下:
这位研究者认为,这对于安全方面来说也许是个好消息,至少模型不会「为所欲为」。

但也有人指出,这篇论文所使用的模型不太合适 ——「GPT-2 规模」意味着本文模型大概是 15 亿参数作用,这确实很难泛化。


接下来,我们先来看看论文细节。
模型选择现象
在对不同函数类的数据混合体进行预训练时,会遇到一个问题:当模型看到预训练混合体支持的上下文样本时,如何在不同函数类之间进行选择?
研究者发现,模型在看到属于预训练数据混合体的函数类的上下文样本后,会做出最佳(或接近最佳)预测。他们还观察了模型在不属于任何单一成分函数类的函数上的表现,然后在第 4 节中探讨了一些与所有预训练数据完全不相关的函数。
首先从线性函数的研究开始,线性函数在上下文学习领域受到了广泛关注。去年,斯坦福大学 Percy Liang 等人的论文《What Can Transformers Learn In-Context? A Case Study of Simple Function Classes》表明,对线性函数进行预训练的 Transformer 在对新的线性函数进行上下文学习时表现近乎最佳。
他们特别考虑了两个模型:一个是在密集线性函数(线性模型的所有系数都非零)上训练的模型,另一个是在稀疏线性函数(20 个系数中只有 2 个系数非零)上训练的模型。在新的密集线性函数和稀疏线性函数上,每个模型的表现分别与线性回归和 Lasso 回归相当。此外,研究者还将这两个模型与在稀疏线性函数和密集线性函数的混合体上预训练的模型进行了比较。
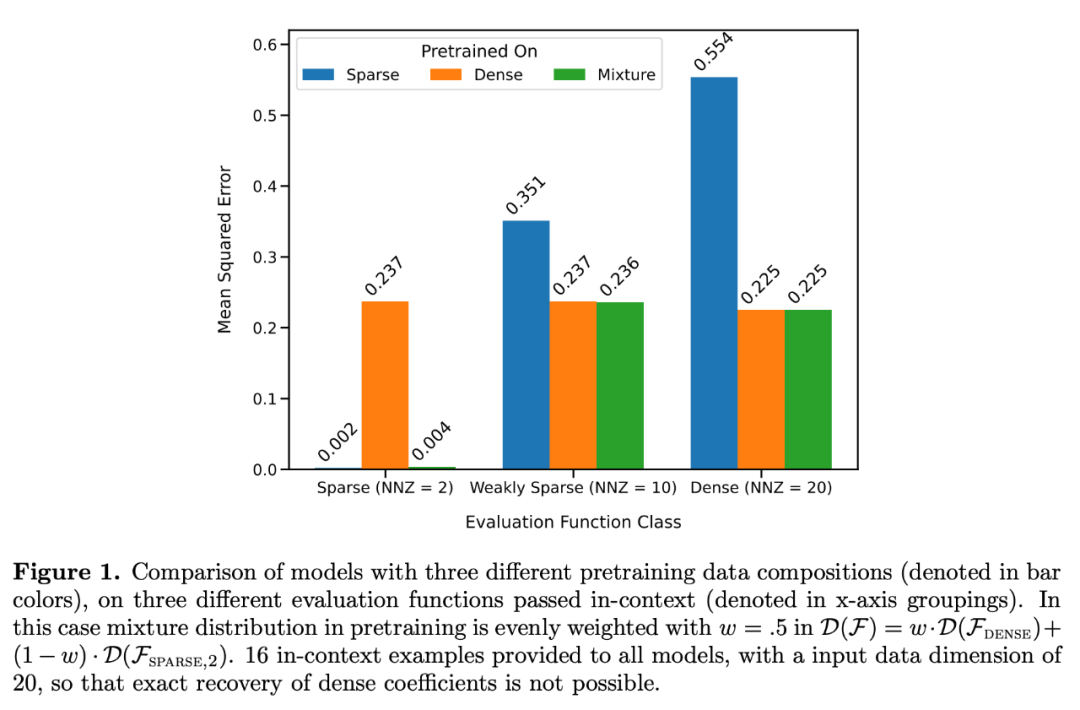
如图 1 所示,该模型在一个
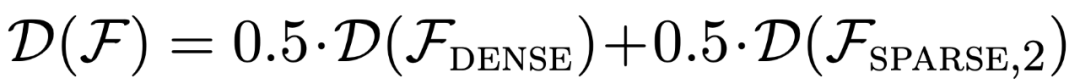
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

