

金花235(金花235能吃什么
原文来源:机器之心

图片来源:由无界 AI生成
电子游戏已经成为如今现实世界的模拟舞台,展现出无限可能。以游戏《侠盗猎车手》(GTA)为例,在 GTA 的世界里,玩家可以以第一人称视角,在洛圣都(游戏虚拟城市)当中经历丰富多彩的生活。然而,既然人类玩家能够在洛圣都里尽情遨游完成若干任务,我们是否也能有一个 AI 视觉模型,操控 GTA 中的角色,成为执行任务的 “玩家” 呢?GTA 的 AI 玩家又是否能够扮演一个五星好市民,遵守交通规则,帮助警方抓捕罪犯,甚至做个热心肠的路人,帮助流浪汉找到合适的住所?
目前的视觉 - 语言模型(VLMs)在多模态感知和推理方面取得了实质性的进步,但它们往往基于较为简单的视觉问答(VQA)或者视觉标注(Caption)任务。这些任务设定显然无法使 VLM 真正完成现实世界当中的任务。因为实际任务不仅需要对于视觉信息的理解,更需要模型具有规划推理以及根据实时更新的环境信息做出反馈的能力。同时生成的规划也需要能够操纵环境中的实体来真实地完成任务。
尽管已有的语言模型(LLMs)能够根据所提供的信息进行任务规划,但其无法理解视觉输入,极大的限制了语言模型在执行现实世界的具体任务时的应用范围,尤其是对于一些具身智能任务,基于文本的输入往往很难详尽或过于复杂,从而使得语言模型无法从中高效地提取信息从而完成任务。而当前的语言模型对于程序生成已经进行了若干探索,但是根据视觉输入来生成结构化,可执行,且稳健的代码的探索还尚未深入。
为了解决如何使大模型具身智能化的问题,创建能够准确制定计划并执行命令的自主和情境感知系统,来自新加坡南洋理工大学,清华大学等的学者提出了 Octopus。Octopus 是一种基于视觉的可编程智能体,它的目的是通过视觉输入学习,理解真实世界,并以生成可执行代码的方式完成各种实际任务。通过在大量视觉输入和可执行代码的数据对的训练,Octopus学会了如何操控电子游戏的角色完成游戏任务,或者完成复杂的家务活动。

数据采集与训练
为了训练能够完成具身智能化任务的视觉 - 语言模型,研究者们还开发了 OctoVerse,其包含两个仿真系统用于为 Octopus 的训练提供训练数据以及测试环境。这两个仿真环境为 VLM 的具身智能化提供了可用 的训练以及测试场景,对模型的推理和任务规划能力都提出了更高的要求。具体如下:
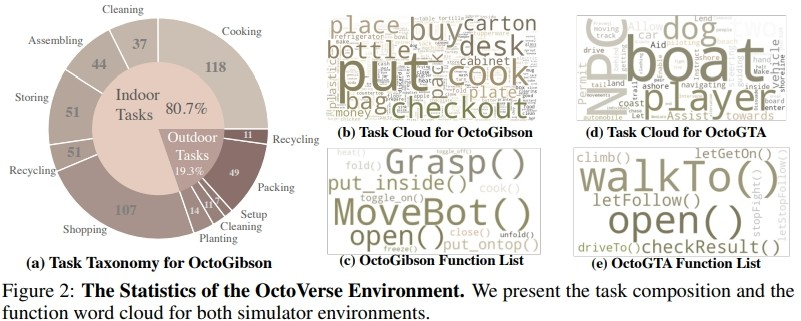
1.OctoGibson:基于斯坦福大学开发的 OmniGibson 进行开发,一共包括了 476 个符合现实生活的家 务活动。整个仿真环境中包括 16 种不同类别的家庭场景,涵盖 155 个实际的家庭环境实例。模型可 以操作其中存在的大量可交互物体来完成最终的任务。
2.OctoGTA:基于《侠盗猎车手》(GTA)游戏进行开发,一共构建了 20 个任务并将其泛化到五个不 同的场景当中。通过预先设定好的程序将玩家设定在固定的位置,提供完成任务必须的物品和 NPC,以保证任务能够顺利进行。
下图展示了 OctoGibson 的任务分类以及 OctoGibson 和 OctoGTA 的一些统计结果。
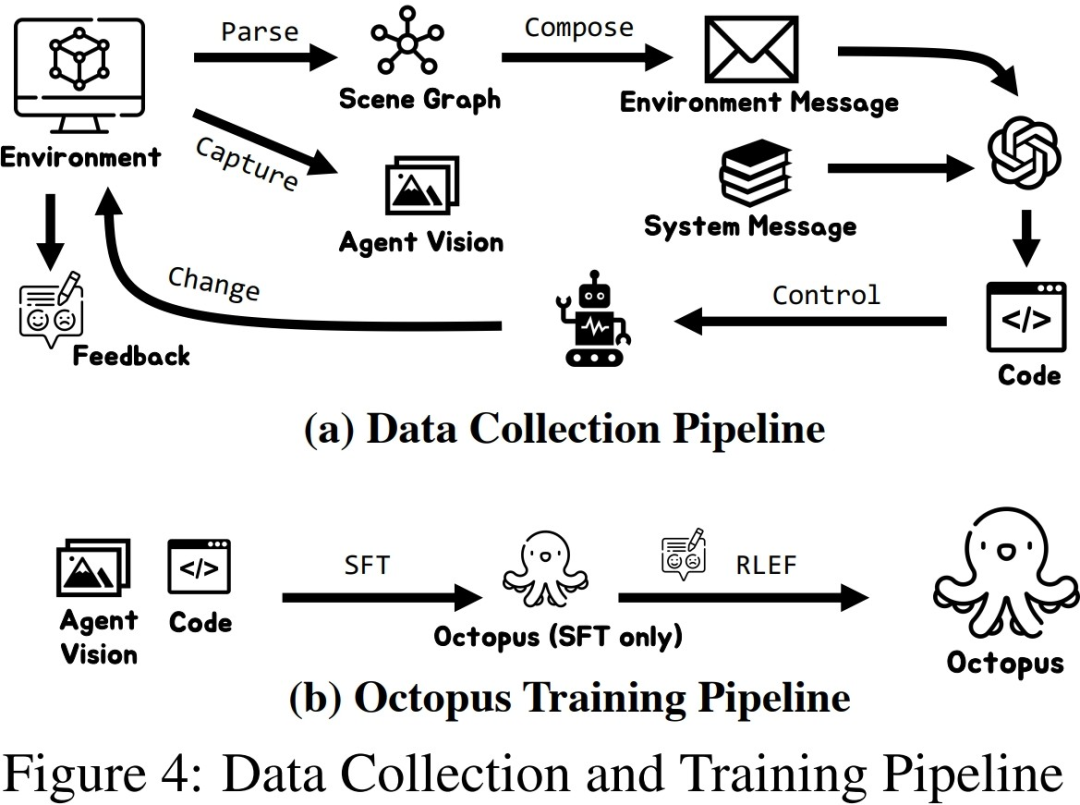
为了在构建的两个仿真环境中高效的收集训练数据,研究者构建了一套完整的数据收集系统。通过引入 GPT-4 作为任务的执行者,研究者们使用预先实现的函数将在仿真环境当中采集到的视觉输入处理为文本信息提供给 GPT-4,在 GPT-4 返回当前一步的任务规划和可执行代码后,再在仿真环境当中执行代码,并 判断当前一步的任务是否完成。如果成功,则继续采集下一步的视觉输入;如果失败,则回到上一步的起始位置,重新采集数据。
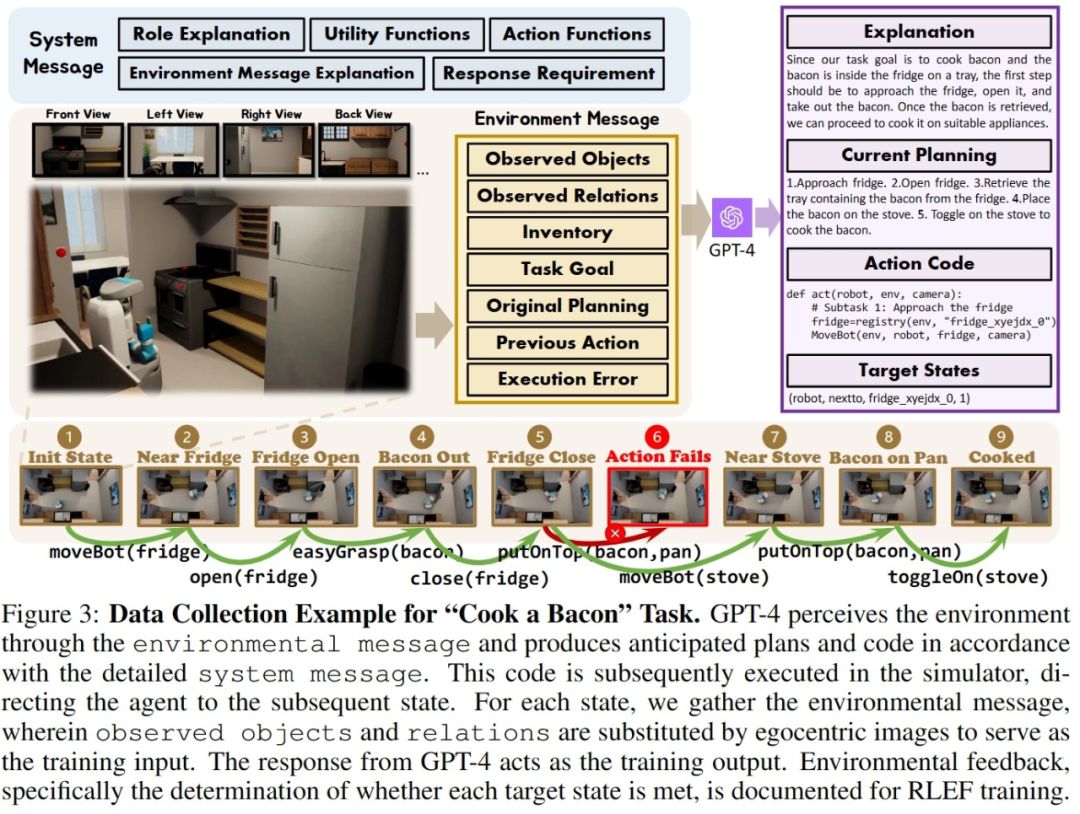
上图以 OctoGibson 环境当中的 Cook a Bacon 任务为例,展示了收集数据的完整流程。需要指出的是,在收集数据的过程中,研究者不仅记录了任务执行过程中的视觉信息,GPT-4 返回的可执行代码等,还记录了每一个子任务的成功情况,这些将作为后续引入强化学习来构建更高效的 VLM 的基础。GPT-4 的功能虽然强大,但并非无懈可击。错误可以以多种方式显现,包括语法错误和模拟器中的物理挑战。例如,如图 3 所示,在状态 #5 和 #6 之间,由于 agent 拿着的培根与平底锅之间的距离过远,导致 “把培根放到平底锅” 的行动失败。此类挫折会将任务重置到之前的状态。如果一个任务在 10 步之后仍未完成,则被认定为不成功,我们会因预算问题而终止这个任务,而这个任务的所有子任务的数据对都会认为执行失败。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

