

Amber Group地址近十日内从币
核心提示:
ChatGPT等基于自然语言处理技术的聊天AI,就短期来看亟需要解决的法律合规问题主要有三个:
其一,聊天AI提供的答复的知识产权问题,其中最主要的合规难题是聊天AI产出的答复是否产生相应的知识产权?是否需要知识产权授权?;
其二,聊天AI对巨量的自然语言处理文本(一般称之为语料库)进行数据挖掘和训练的过程是否需要获得相应的知识产权授权?
其三,ChatGPT等聊天AI的回答是机制之一是通过对大量已经存在的自然语言文本进行数学上的统计,得到一个基于统计的语言模型,这一机制导致聊天AI很可能会“一本正经的胡说八道”,进而导致虚假信息传播的法律风险,在这一技术背景下,如何尽可能降低聊天AI的虚假信息传播风险?
总体而言,目前我国对于人工智能立法依然处在预研究阶段,还没有正式的立法计划或者相关的动议草案,相关部门对于人工智能领域的监管尤为谨慎,随着人工智能的逐步发展,相应的法律合规难题只会越来越多。
ChatGPT并非是“跨时代的人工
智能技术”
ChatGPT本质上是自然语言处理技术发展的产物,本质上依然仅是一个语言模型。
2023开年之初全球科技巨头微软的巨额投资让ChatGPT成为科技领域的“顶流”并成功出圈。随着资本市场ChatGPT概念板块的大涨,国内众多科技企业也着手布局这一领域,在资本市场热捧“ChatGPT概念的同时,作为法律工作者,我们不禁要评估ChatGPT自身可能会带来哪些法律安全风险,其法律合规路径何在?
在讨论ChatGPT的法律风险及合规路径之前,我们首先应当审视ChatGPT的技术原理——ChatGPT是否如新闻所言一样,可以给提问者任何其想要的问题?
在飒姐团队看来,ChatGPT似乎远没有部分新闻所宣传的那样“神”——一句话总结,其仅仅是Transformer和GPT等自然语言处理技术的集成,本质上依然是一个基于神经网络的语言模型,而非一项“跨时代的AI进步”。
前面已经提到ChatGPT是自然语言处理技术发展的产物,就该技术的发展史来看,其大致经历了基于语法的语言模型——基于统计的语言模型——基于神经网络的语言模型三大阶段,ChatGPT所在的阶段正是基于神经网络的语言模型阶段,想要更为直白地理解ChatGPT的工作原理及该原理可能引发的法律风险,必须首先阐明的就是基于神经网络的语言模型的前身——基于统计的语言模型的工作原理。
在基于统计的语言模型阶段,AI工程师通过对巨量的自然语言文本进行统计,确定词语之间先后连结的概率,当人们提出一个问题时,AI开始分析该问题的构成词语共同组成的语言环境之下,哪些词语搭配是高概率的,之后再将这些高概率的词语拼接在一起,返回一个基于统计学的答案。可以说这一原理自出现以来就贯穿了自然语言处理技术的发展,甚至从某种意义上说,之后出现的基于神经网络的语言模型亦是对基于统计的语言模型的修正。
举一个容易理解的例子,飒姐团队在ChatGPT聊天框中输入问题“大连有哪些旅游胜地?”如下图所示:
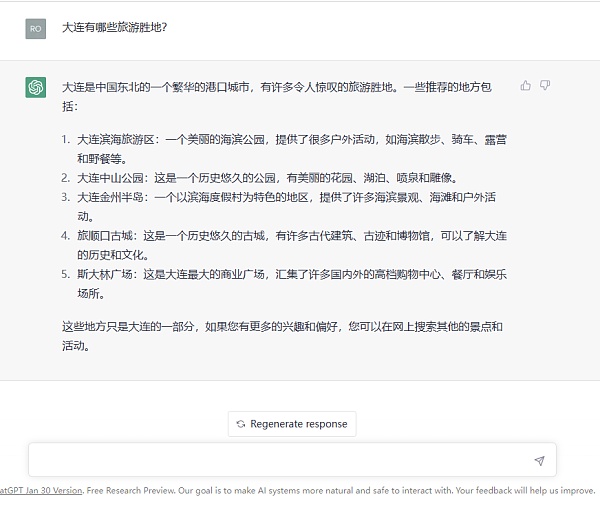
AI第一步会分析问题中的基本语素“大连、哪些、旅游、胜地”,再在已有的语料库中找到这些语素所在的自然语言文本集合,在这个集合中找寻出现概率最多的搭配,再将这些搭配组合以形成最终的答案。如AI会发现在“大连、旅游、胜地”这三个词高概率出现的语料库中,有“中山公园”一词,于是就会返回“中山公园”,又如“公园”这个词与花园、湖泊、喷泉、雕像等词语搭配的概率最大,因此就会进一步返回“这是一个历史悠久的公园,有美丽的花园、湖泊、喷泉和雕像。”
换言之,整个过程都是基于AI背后已有的自然语言文本信息(语料库)进行的概率统计,因此返回的答案也都是“统计的结果”,这就导致了ChatGPT在许多问题上会“一本正经的胡说八道”。如刚才的这个问题“大连有哪些旅游胜地”的回答,大连虽然有中山公园,但是中山公园中并没有湖泊、喷泉和雕像。大连在历史上的确有“斯大林广场”,但是斯大林广场自始至终都不是一个商业广场,也没有任何购物中心、餐厅和娱乐场所。显然,ChatGPT返回的信息是虚假的。
ChatGPT作为语言模型目前其
最适合的应用场景
虽然上个部分我们直白的讲明了基于统计的语言模型的弊端,但ChatGPT毕竟已经是对基于统计的语言模型大幅度改良的基于神经网络的语言模型,其技术基础Transformer和GPT都是最新一代的语言模型,ChatGPT本质上就是将海量的数据结合表达能力很强的Transformer模型结合,从而对自然语言进行了一个非常深度的建模,返回的语句虽然有时候是“胡说八道”,但乍一看还是很像“人类回复的”,因此这一技术在需要海量的人机交互的场景下具有广泛的应用场景。
就目前来看,这样的场景有三个:
其一,搜索引擎;
其二,银行、律所、各类中介机构、商场、医院、政府政务服务平台中的人机交互机制,如上述场所中的客诉系统、导诊导航、政务咨询系统;
第三,智能汽车、智能家居(如智能音箱、智能灯光)等的交互机制。
结合ChatGPT等AI聊天技术的搜索引擎很可能会呈现出传统搜索引擎为主+基于神经网络的语言模型为辅的途径。目前传统的搜索巨头如谷歌和百度均在基于神经网络的语言模型技术上有着深厚的积累,譬如谷歌就有与ChatGPT相媲美的Sparrow和Lamda,有着这些语言模型的加持,搜索引擎将会更加“人性化”。
ChatGPT等AI聊天技术运用在客诉系统和医院、商场的导诊导航以及政府机关的政务咨询系统中将大幅度降低相关单位的人力资源成本,节约沟通时间,但问题在于基于统计的回答有可能产生完全错误的内容回复,由此带来的风控风险恐怕还需要进一步评估。
相比于上述两个应用场景,ChatGPT应用在智能汽车、智能家居等领域成为上述设备的人机交互机制的法律风险则要小很多,因为这类领域应用环境较为私密,AI反馈的错误内容不至于引起大的法律风险,同时这类场景对内容准确性要求不高,商业模式也更为成熟。三
ChatGPT的法律风险及合规路径
初探
第一,人工智能在我国的整体监管图景
和许多新兴技术一样,ChatGPT所代表的自然语言处理技术也面临着“科林格里奇窘境(Collingridge dilemma)”这一窘境包含了信息困境与控制困境,所谓信息困境,即一项新兴技术所带来的社会后果不能在该技术的早期被预料到;所谓控制困境,即当一项新兴技术所带来的不利的社会后果被发现时,技术却往往已经成为整个社会和经济结构的一部分,致使不利的社会后果无法被有效控制。
目前人工智能领域,尤其是自然语言处理技术领域正在快速发展阶段,该技术很可能会陷入所谓的“科林格里奇窘境”,与此相对应的法律监管似乎并未“跟得上步伐”。我国目前尚无国家层面上的人工智能产业立法,但地方已经有相关的立法尝试。就在去年9月,深圳市公布了全国收不人工智能产业专项立法《深圳经济特区人工智能产业促进条例》,紧接着上海也通过了《上海市促进人工智能产业发展条例》,相信不久之后各地均会出台类似的人工智能产业立法。
在人工智能的伦理规制方面,国家新一代人工智能治理专业委员会亦在2021年发布了《新一代人工智能伦理规范》,提出将伦理道德融入人工智能研发和应用的全生命周期,或许在不久的将来,类似阿西莫夫小说中的“机器人三定律”将成为人工智能领域监管的铁律。
第二,ChatGPT带来的虚假信息法律风险问题
将目光由宏观转向微观,抛开人工智能产业的整体监管图景和人工智能伦理规制问题,ChatGPT等AI聊天基础存在的现实合规问题也急需重视。
这其中较为棘手的是ChatGPT回复的虚假信息问题,正如本文在第二部分提及的,ChatGPT的工作原理导致其回复可能完全是“一本正经的胡说八道”,这种看似真实实则离谱的虚假信息具有极大的误导性。当然,像对“大连有哪些旅游胜地”这类问题的虚假回复可能不会造成严重后果,但倘若ChatGPT应用到搜索引擎、客诉系统等领域,其回复的虚假信息可能造成极为严重的法律风险。
实际上这样的法律风险已经出现,2022年11月几乎与ChatGPT同一时间上线的Meta服务科研领域的语言模型Galactica就因为真假答案混杂的问题,测试仅仅3天就被用户投诉下线。在技术原理无法短时间突破的前提下,倘若将ChatGPT及类似的语言模型应用到搜索引擎、客诉系统等领域,就必须对其进行合规性改造。当检测到用户可能询问专业性问题时,应当引导用户咨询相应的专业人员,而非在人工智能处寻找答案,同时应当显著提醒用户聊天AI返回的问题真实性可能需要进一步验证,以最大程度降低相应的合规风险。
第三,ChatGPT带来的知识产权合规问题
当将目光由宏观转向微观时,除了AI回复信息的真实性问题,聊天AI尤其是像ChatGPT这样的大型语言模型的知识产权问题亦应该引起合规人员的注意。
首先的合规难题是“文本数据挖掘”是否需要相应的知识产权授权问题。正如前文所指明的ChatGPT的工作原理,其依靠巨量的自然语言本文(或言语料库),ChatGPT需要对语料库中的数据进行挖掘和训练,ChatGPT需要将语料库中的内容复制到自己的数据库中,相应的行为通常在自然语言处理领域被称之为“文本数据挖掘”。当相应的文本数据可能构成作品的前提下,文本数据挖掘行为是否侵犯复制权当前仍存在争议。
在比较法领域,日本和欧盟在其著作权立法中均对合理使用的范围进行了扩大,将AI中的“文本数据挖掘”增列为一项新的合理使用的情形。虽然2020年我国著作权法修法过程中有学者主张将我国的合理使用制度由“封闭式”转向“开放式”,但这一主张最后并未被采纳,目前我国著作权法依旧保持了合理使用制度的封闭式规定,仅著作权法第二十四条规定的十三中情形可以被认定为合理使用,换言之,目前我国著作权法并未将AI中的“文本数据挖掘”纳入到合理适用的范围内,文本数据挖掘在我国依然需要相应的知识产权授权。
其次的合规难题是ChatGPT产生的答复是否具有独创性?对于AI生成的作品是否具有独创性的问题,飒姐团队认为其判定标准不应当与现有的判定标准有所区别,换言之,无论某一答复是AI完成的还是人类完成的,其都应当根据现有的独创性标准进行判定。其实这个问题背后是另一个更具有争议性的问题,如果AI生成的答复具有独创性,那么著作权人可以是AI吗?显然,在包括我国在内的大部分国家的知识产权法律下,作品的作者仅有可能是自然人,AI无法成为作品的作者。
最后,ChatGPT倘若在自己的回复中拼接了第三方作品,其知识产权问题应当如何处理?飒姐团队认为,如果ChatGPT的答复中拼接了语料库中拥有著作权的作品(虽然依据ChatGPT的工作原理,这种情况出现的概率较小),那么按照中国现行的著作权法,除非构成合理使用,否则非必须获得著作权人的授权后才可以复制。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

