

大银行正在竞购陷入困境
文章来源:新智元
编辑:Aeneas 好困

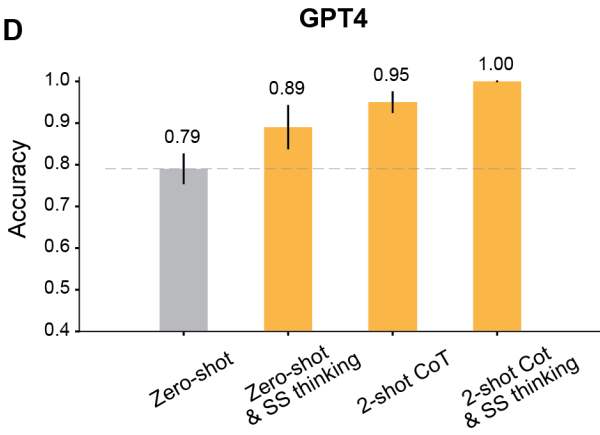
最新研究结果表明,AI在心智理论测试中的表现已经优于真人。GPT-4在推理基准测试中准确率可高达100%,而人类仅为87%。
GPT-4的心智理论,已经超越了人类!
最近,约翰斯·霍普金斯大学的专家发现,GPT-4可以利用思维链推理和逐步思考,大大提升了自己的心智理论性能。

论文地址:https://arxiv.org/abs/2304.11490
在一些测试中,人类的水平大概是87%,而GPT-4,已经达到了天花板级别的100%!
此外,在适当的提示下,所有经过RLHF训练的模型都可以实现超过80%的准确率。
我们都知道,关于日常生活场景的问题,很多大语言模型并不是很擅长。
Meta首席AI科学家、图灵奖得主LeCun曾断言:「在通往人类级别AI的道路上,大型语言模型就是一条歪路。要知道,连一只宠物猫、宠物狗都比任何LLM有更多的常识,以及对世界的理解。」

也有学者认为,人类是随着身体进化而来的生物实体,需要在物理和社会世界中运作以完成任务。而GPT-3、GPT-4、Bard、Chinchilla和LLaMA等大语言模型都没有身体。
所以除非它们长出人类的身体和感官,有着人类的目的的生活方式。否则它们根本不会像人类那样理解语言。

总之,虽然大语言模型在很多任务中的优秀表现令人惊叹,但需要推理的任务,对它们来说仍然很困难。
而尤其困难的,就是一种心智理论(ToM)推理。

为什么ToM推理这么困难呢?
因为在ToM任务中,LLM需要基于不可观察的信息(比如他人的隐藏心理状态)进行推理,这些信息都是需要从上下文推断出的,并不能从表面的文本解析出来。
但是,对LLM来说,可靠地执行ToM推理的能力又很重要。因为ToM是社会理解的基础,只有具有ToM能力,人们才能参与复杂的社会交流,并预测他人的行动或反应。
如果AI学不会社会理解、get不到人类社会交往的种种规则,也就无法为人类更好地工作,在各种需要推理的任务中为人类提供有价值的见解。

怎么办呢?
专家发现,通过一种「上下文学习」,就能大大增强LLM的推理能力。
对于大于100B参数的语言模型来说,只要输入特定的few-shot任务演示,模型性能就显著增强了。
另外,即使在没有演示的情况下,只要指示模型一步步思考,也会增强它们的推理性能。
为什么这些prompt技术这么管用?目前还没有一个理论能够解释。
基于这个背景,约翰斯·霍普金斯大学的学者评估了一些语言模型在ToM任务的表现,并且探索了它们的表现是否可以通过逐步思考、few-shot学习和思维链推理等方法来提高。
参赛选手分别是来自OpenAI家族最新的四个GPT模型——GPT-4以及GPT-3.5的三个变体,Davinci-2、Davinci-3和GPT-3.5-Turbo。
· Davinci-2(API名称:text-davinci-002)是在人类写的演示上进行监督微调训练的。
· Davinci-3(API名称:text-davinci-003)是Davinci-2的升级版,它使用近似策略优化的人类反馈强化学习(RLHF)进一步训练。
· GPT-3.5-Turbo(ChatGPT的原始版本),在人写的演示和RLHF上都进行了微调训练,然后为对话进一步优化。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

")