

这次Pi币真的上线主网了!
自从 ChatGPT 和 GPT-4 推出后,有很多关于人工智能如何革新一切,包括 Web 3 的内容。多个行业的开发者报告称,通过利用 ChatGPT 作为共同驾驶员来自动化任务,如生成样板代码、进行单元测试、创建文档、调试和检测漏洞等,可以显著提高生产效率,范围从 50% 到 500% 不等。虽然本文将探讨人工智能如何实现新的有趣的 Web 3 用例,但其主要关注点是 Web 3 和人工智能之间的互利关系。很少有技术有能力显著影响人工智能的发展方向,而 Web 3 是其中之一。

尽管其具有巨大的潜力,但当前的人工智能模型面临着一些挑战,如数据隐私、专有模型的执行公正性以及创造和传播可信的虚假内容的能力等。一些现有的 Web 3 技术在应对这些挑战方面具有独特的优势。
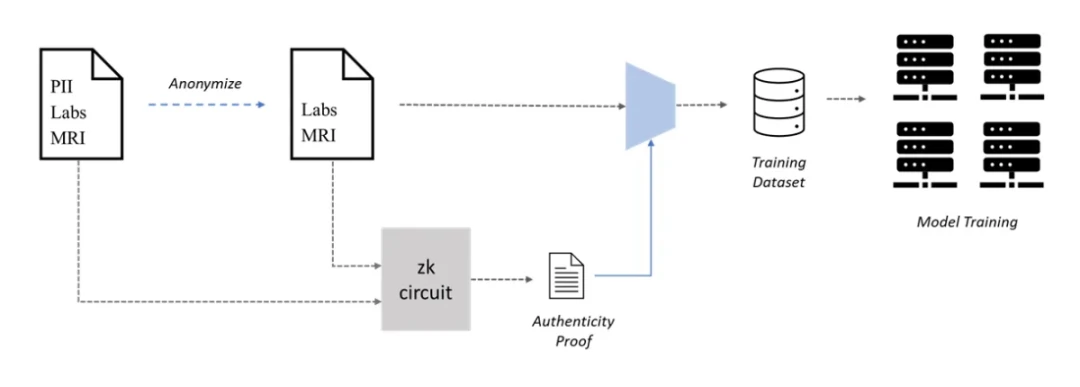
Web 3 可以帮助 AI 的一个领域是通过协作创建专有数据集进行机器学习(ML)训练,即使用 PoPW 网络进行数据集创建。大规模数据集对于准确的 ML 模型至关重要,但在需要使用私有数据(如使用 ML 进行医学诊断)的用例中,其创建可能成为瓶颈。由于患者数据隐私的关注,医疗记录的访问是训练这些模型的必要条件,但患者可能因隐私问题而不愿意分享他们的医疗记录。为了解决这个问题,患者可以通过可验证的方式对其医疗记录进行匿名化,以保护他们的隐私同时仍然可以用于 ML 训练。
但是,匿名化的医疗记录的真实性是一个问题,因为虚假数据会严重影响模型的性能。为解决这个问题,可以使用零知识证明(ZKPs)来验证匿名化的医疗记录的真实性。患者可以生成 ZKPs,以证明匿名记录确实是原始记录的副本,即使在删除个人身份信息(PII)后也是如此。这样,患者可以将匿名记录与 ZKPs 一起提供给感兴趣的各方,并甚至获得他们的贡献的奖励,而不会牺牲他们的隐私。
当前 LLM 的一个主要弱点是处理私有数据。例如,当用户与 chatGPT 互动时,OpenAI 会收集用户的私人数据,并将其用于模型的训练,这会导致敏感信息的泄露。这是三星公司的情况。零知识(zk)技术可以帮助解决 ML 模型在私有数据上执行推理时出现的一些问题。在这里,我们考虑两种情况:开源模型和专有模型。
对于开源模型,用户可以在其私有数据上本地下载模型并运行。例如,Worldcoin 计划升级 World ID。在此用例中,Worldcoin 需要处理用户的私人生物识别数据,即用户的虹膜扫描,以创建名为 IrisCode 的每个用户的唯一标识符。在这种情况下,用户可以在其设备上保持其生物识别数据的私密性,下载用于 IrisCode 生成的 ML 模型,本地运行推理,并创建证明表明其 IrisCode 已成功创建。生成的证明保证了推理的真实性,同时保持了数据的隐私。像 Modulus Labs 开发的 ML 模型的高效 zk 证明机制对于这种用例至关重要。
另一种情况是当用于推理的 ML 模型是专有的。这项任务有点困难,因为本地推理不是一种选择。但是,ZKP 有两种可能的方式可以帮助。第一种方法是使用 ZKP 将用户数据进行匿名处理,如前面数据集创建案例中所讨论的,然后将匿名化的数据发送到 ML 模型。另一种方法是在将预处理输出发送到 ML 模型之前,在私人数据上使用本地预处理步骤。在这种情况下,预处理步骤隐藏了用户的私人数据,以便无法重构。用户生成一个 ZKP,表明预处理步骤的正确执行,然后专有模型的其余部分可以在模型所有者的服务器上远程执行。这里的示例用例可能包括可以分析潜在诊断的患者的医疗记录的 AI 医生,以及评估客户私人财务信息的金融风险评估算法。
与专注于生成图片、音频和视频的生成式人工智能模型相比,chatGPT 可能已经抢占了风头。然而,这些模型目前已经能够生成逼真的深度伪造作品。最近由 AI 生成的 Drake 歌曲就是这些模型所能实现的例子。由于人类被编程成相信所见所闻,这些深度伪造作品代表了一个重大威胁。有许多初创公司正在尝试使用 Web 2 技术来解决这个问题。然而,Web 3 技术,如数字签名,更适合解决这个问题。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

