

A股大模型再添重磅玩家
作者:举大名耳,来源: 阿尔法工场研究院
导语:面对苹果今天在AI上的种种困境,人们不禁在想,倘若面对这些难题的是乔布斯,他又会如何决断呢?
在今年爆发的AI大战中,微软、谷歌、亚马逊等各个大厂,都纷纷使出了自己的浑身解数,渴望在未来的赛道中抢占先机。
然而,同样身为科技界龙头企业的苹果,却在这场竞争中“哑火”了。
面对不可忽视的AI大模型浪潮,苹果自己的AI究竟去哪了?
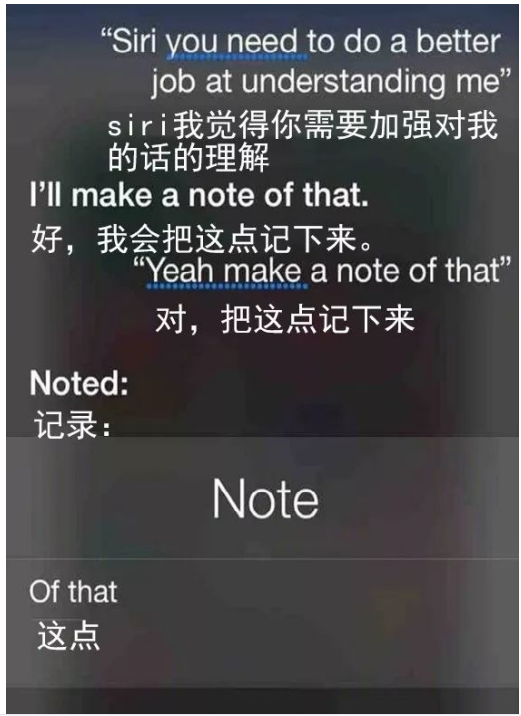
提到这个问题,很多人几乎都会想到iPhone自带的智能助手——Siri。
然而,实事求是地说,在近十年的历程中,Siri的表现不但没有变得更“智能”,反而变得愈发“智障”了。
反应间隔久、不能连续提问、回答刻板重复……等等这些特点,在GPT等AI变得愈发有“人性”的今天,都让Siri看上去比“机器”更冰冷了。
一个讽刺的事实是:这个今日连苹果内部员工都侧目的弃儿,十多年前,却是承载了乔布斯最大期望的“天之骄子”。
在当时的乔布斯看来,Siri不仅代表了苹果未来在AI领域的希望,而且“最终会在宇宙留下自己的痕迹”。
既然如此,那情况是怎么衰落到今天这个地步的?
如果要为当下苹果在AI领域的乏力,找一个最主要的病灶,那这样的病灶,则莫过于苹果长期以来对用户隐私和数据安全的“执着”。
众所周知,大模型的训练,离不开大量数据的支持,这就意味着对用户信息和数据的访问,往往是无法避免的。
然而,对用户隐私的保护,一直以来都是苹果品牌形象和商业模式的核心,这就导致了其试图在发展大模型时,出现了各种焦头烂额的情况。
例如,由于无法获得实时的用户反馈和数据,每当研发团队试图为Siri增加一个新短语时,往往就需要重建整个数据库,这一过程耗时将会长达六个星期。
如果是复杂的功能,长则一年也很有可能。
不仅如此,而且苹果设计团队还多次拒绝允许用户对Siri回答问题进行反馈,导致开发团队无法理解模型的局限。
那么,这种今天看起来如作茧自缚一般的隐私政策,究竟是怎么在苹果内部形成的呢?
与所有事物的发展一样,苹果的隐私品牌也不是生来就有的,而是经历了10年的漫长发展,其对隐私的重视程度,实际上是在一次次被市场“毒打”下不断升级,直至成为苹果的“核心价值观”的。
其中最重要的两次转折,分别发生在2011和2014年。
2011年4月,苹果被爆出将用户定位信息明文上传服务器,侵犯用户隐私;
2014年7月,苹果又被黑客爆出存在多个后门,这些后门会通过一项未公开的技术,来提取iPhone中的短信、通讯录和照片等个人数据;
经过这两次“毒打”后,痛定思痛的苹果,不得不在隐私安全上下了狠功夫,在2015年重金挖来了有“隐私三沙皇”之一称号的谷歌全球隐私顾问Jane Horvath,来协助研发IOS系统中的隐私设计。
然而,“隐私”这一核心价值观的设立,对苹果而言,既是一块金字招牌,又是一条束缚自身的枷锁。
因为此后任何有碍于“隐私”的产品改动,都无益于在挑战自身辛苦积累的品牌忠诚度和市场占有率。
但人是活的,数据是死的,在通往大模型的路上,总有一些办法能让人另辟蹊径。
在2017年的WWDC大会上,苹果宣布采用联邦学习(Federated Learning)技术来改进Siri的语音识别功能。
它可以在设备上进行识别,而不需要将用户的语音数据上传到云端进行处理,从而保护用户的隐私。
这是个十分创新的技术,因为它解决了隐私安全和训练大模型之间的冲突。
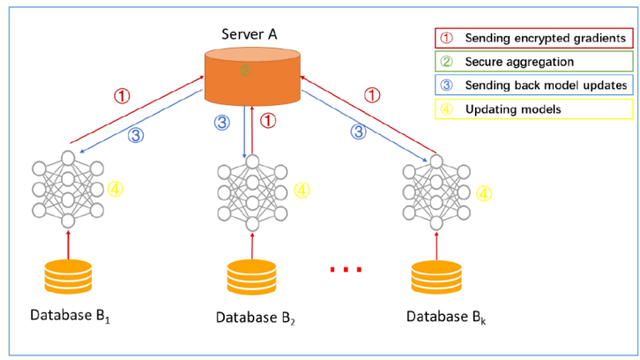
当初始化的模型,在本地完成训练后,传回云端的只是一个基于本地数据训练而得到的模型,而不是用户数据本身。
这些本地模型被传输回云端后,通过模型聚合的方式,用户所有的本地模型将合并成一个全局模型。
最后,苹果会通过模型更新的方式,将合并后的全局模型传输回用户的本地设备上,替换原有的模型。
如此一来,苹果既实现了模型的训练,又保护了用户的隐私安全,可谓一举两得。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

