

BRC20 真的懂 Web3.0 ?Yuga
来源:阿尔法工场
最近,正在进行AI大战的各个大厂,被谷歌泄漏的一份内部文件,翻开了窘迫的一面。
这份泄露的内部文件声称:“我们没有‘护城河’,OpenAI 也没有。当我们还在争吵时,第三个方已经悄悄地抢了我们的饭碗——开源。”
这份文件认为,现在的一些开源模型,一直在照搬谷歌、微软这些大厂的劳动成果,并且双方差距正在以惊人的速度缩小。开源模型更快、可定制性更强、更私密,而且功能性也不落下风。
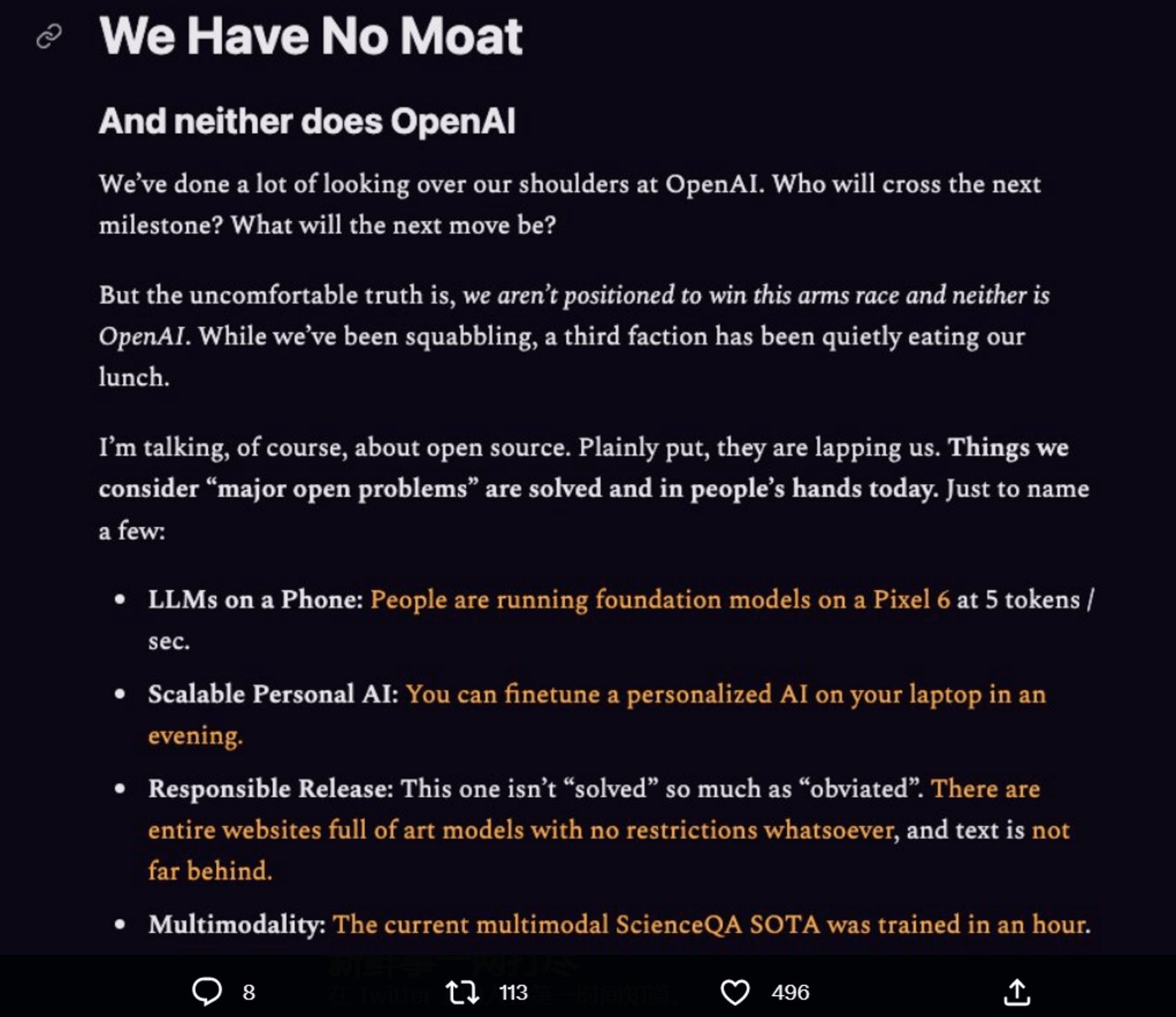
比如,这些开源模型可以用 100 美元外加 13B 参数,加上几个礼拜的时间就能出炉,而谷歌这样的大厂,要想训练大模型,则需要面对千万美元的成本和 540B 参数,以及长达数月的训练周期。
那么,事实是否真的像这份文件所说的那样,谷歌和OpenAI在AI方面的种种积累,最终真的会败给一群隐藏在民间的“草头侠”?
所谓“大厂垄断大模型”的时代,真的要终结了吗?
要回答这个问题,我们就得先了解下目前开源模型的生态,看看这些如雨后春笋般涌现的开源模型,究竟是如何一步步蚕食谷歌这些“正规军”的江山的。
其实,最早的开源模型,其诞生完全是一场“偶然”。
今年2月,Meta发布了自家的大型语言模型LLaMA,参数量从70亿到650亿不等,并仅用130亿的参数,就在大多数基准测试下超越了GPT-3。
但万万没想到的是,刚发布没几天,LLaMA的模型文件就被泄露了。
至此之后,开源模型的浪潮就如决堤一般,变得一发不可收拾。
如八仙过海一般的ChatGPT开源替代品——「羊驼家族」,随即粉墨登场。
与ChatGPT这类大模型相比,此类开源模型最显著的特点,就是训练成本与时间都极其低廉。
以LlaMA的衍生模型Alpaca为例,其训练成本仅用了52k数据和600美元。
然而,如果开源光靠低成本,还不足以让谷歌这类大厂感到威胁,重要的是,在极低的训练成本下,这些开源模型还能屡次达到和GPT-3.5匹敌的性能。
这下谷歌和OpenAI就坐不住了。
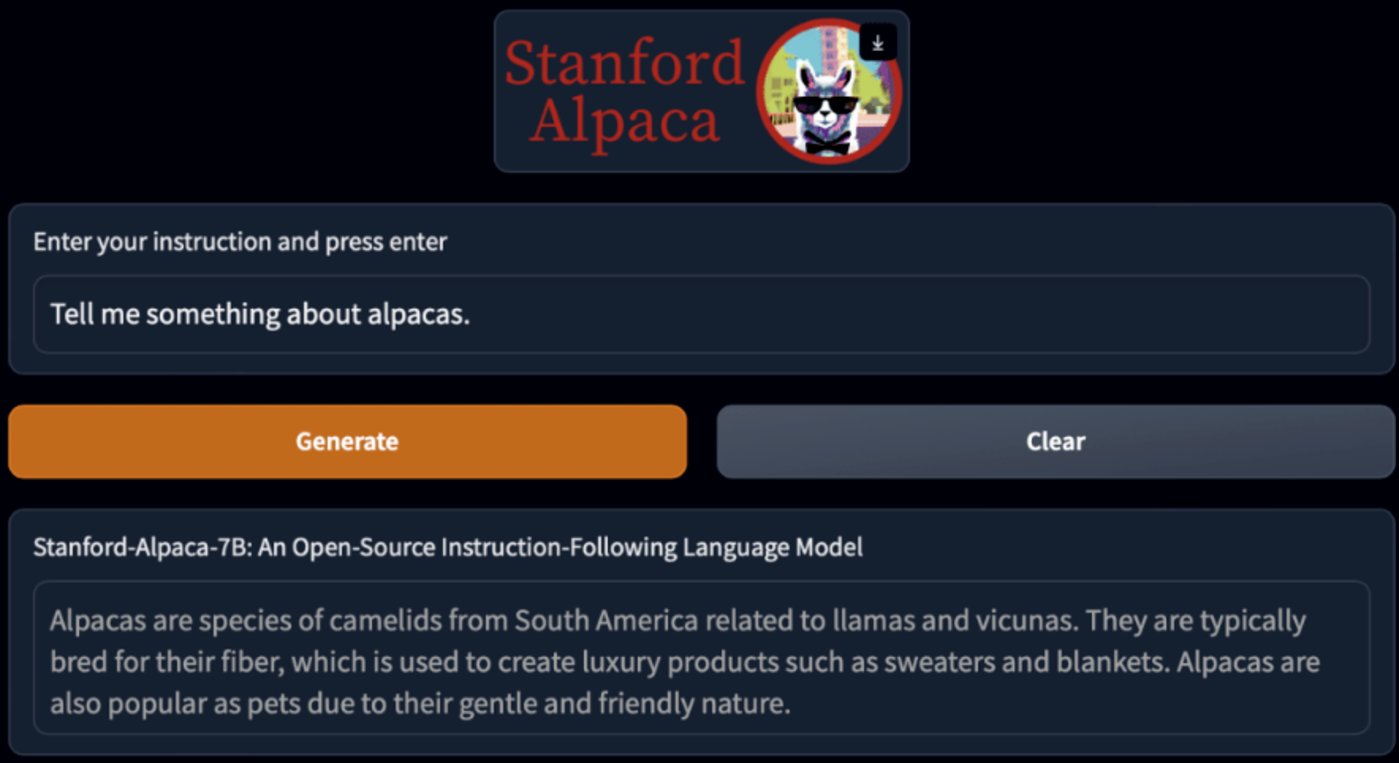
斯坦福研究者对GPT-3.5(text-davinci-003)和Alpaca 7B进行了比较,发现这两个模型的性能非常相似。Alpaca在与GPT-3.5的比较中,获胜次数为90对89。
重点来了:这些开源模型,究竟是怎么做到这点的?
斯坦福团队的答案是两点:1、一个强大的预训练语言模型;2、一个高质量的指令遵循数据。
在这里,我们将强大的预训练语言模型(如LlaMA或GPT-3),比喻为一位有着丰富知识和经验的老师。
对于自然语言处理领域的任务,强大的预训练语言模型,可以利用大规模的文本数据进行训练,学习到自然语言的模式和规律,并且可以帮助指令遵循等任务的模型更好地理解和生成文本,提高模型的表达和理解能力。
这就相当于学生使用老师的知识和经验,来提高语言能力,指令遵循等任务的模型可以使用预训练语言模型的知识和经验来提高自己的表现。
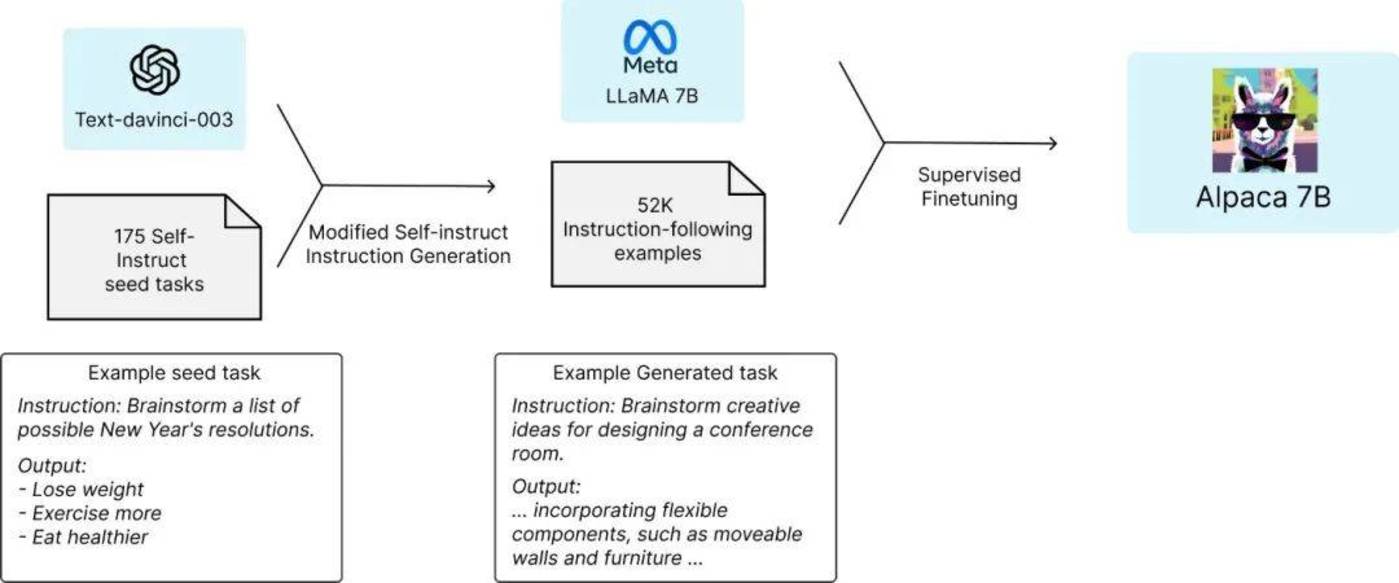
除了借助这位“老师”的知识外,开源模型的另一“利刃”,就是指令微调。
指令微调,或指令调优,是指现有的大语言模型生成指令遵循数据后,对数据进行优化的过程。
具体来说,指令微调是指在生成的指令数据中,对一些不合适或错误的指令进行修正,使其更符合实际应用场景。
而指令调优是指在生成的指令数据中,对一些重要、复杂或容易出错的指令进行加重或重复,以提高指令遵循模型对这些指令的理解和表现能力。
凭借着这样的“微调”,人们可以生成更准确、更有针对性的指令遵循数据,从而提高开源模型在特定任务上的表现能力。
如此一来,即使只用很少的数据,开源社区也能训练出性能匹敌ChatGPT的新模型。
然而,又一个问题是:面对自己辛苦打下的江山,被开源社区用“四两拨千斤”的方式步步蚕食,谷歌和OpenAI为何一直没有予以反制呢?
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

