

数读 Yuga Labs 5 月数据:
原文由Guido Appenzeller, Matt Bornstein, and Martin Casado撰写
EMC爱好者编译整理
底层的算法问题在计算上非常复杂且困难,因而AI的基础设施本身就很昂贵。
不过对于Transformer来说,人们可以估计特定大小的模型将消耗多少计算和内存。因此,选择合适的硬件成为下一个考虑因素。
按照传统CPU的速度,在不利用任何并行架构的情况下,执行单个 GPT-3 的推理操作将需要花费 32 小时。这种速度显然是不行的。
生成式 AI 需要对现有的 AI 基础设施进行大量投资。训练像 GPT-3 这样的模型,是人类有史以来计算量最大的任务之一。虽然GPU越来越快,开发者们也找到了优化训练的方法,但AI的快速扩张抵消了这两种影响。
像OpenAI、Hugging Face、和Replica这样的托管模型服务,允许创始人快速搜索产品与市场的契合度,无需管理底层基础设施或模型。
这些服务的定价是基于消费的,因此它通常也比单独搭建运行的基础设施便宜。
另一方面,训练新基础模型或构建垂直集成的AI初创公司,无法避免直接在GPU上运行自己的模型。因为模型实际上是产品,团队正在寻找“模型-市场契合度”;控制训练和推理才能实现某些功/或大规模降低边际成本。无论哪种方式,管理基础架构都可以成为竞争优势的来源。
大多数情况下,云是最适合构建AI基础设施的地方。
例外情况:
(1)运营规模非常大的情况下,运行自己的数据中心可能更划算。每个地方或许价格不一,但开支通常> 5000 万美元/年。
(2)云提供商无法提供您需要的特定硬件,例如未广泛使用的 GPU 类型,以及异常的内存、存储或网络要求。
价格:特定硬件上的算力是一种商品。虽然我们期望价格统一,但事实并非如此。在价格规模的顶端,大型公共云根据品牌声誉、经过验证的可靠性以及管理各种工作负载的需求收取溢价。较小的专业AI提供商能提供较低的价格,要么通过运行专用数据中心(例如Coreweave)或套利其他云(例如Lambda Labs)。
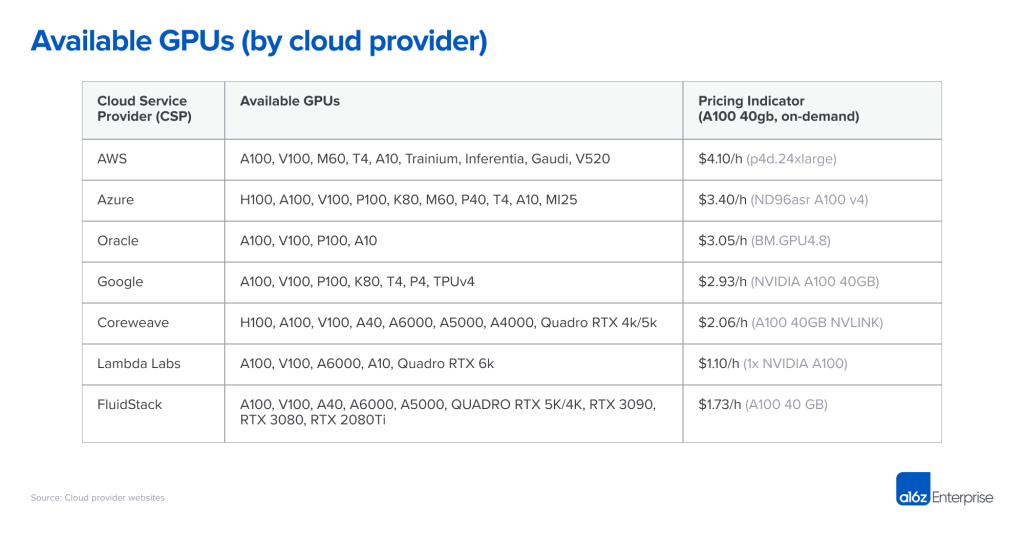
可用性:人们普遍认为前三大云服务供应商可用性最前,不过许多初创企业发现事实未必如此。大型云有很多硬件,但也需要满足大量的客户需求, 例如Azure是ChatGPT的主要主机,并且不断增加/租赁容量以满足需求。与此同时,英伟达致力于在整个行业中广泛提供硬件,包括为新的专业提供商分配硬件。
计算交付模型:由于尚未解决GPU虚拟化的问题,今天的大型云仅提供具有专用GPU的实例。专用 AI 云提供其他模型,例如容器或批处理作业,这些模型可以处理单个任务,而不会产生实例的启动和拆卸成本。如果您对这种模型感到满意,它可以大大降低成本。
网络互连:对于模型训练而言,选择提供商时主要考虑网络带宽。需要节点之间具有专用结构的集群(例如 NVLink)来训练某些大型模型。对于图像生成AI而言,出口流量费用也可能是一个主要的成本驱动因素。
训练与推理:训练大型模型是在机器集群上完成的,每台服务器最好有许多 GPU、大量 VRAM 以及服务器之间的高带宽连接。许多型号在 NVIDIA H100 上最具成本效益,但截至今天很难找到,而且通常需要一年以上的长期投入。而今NVIDIA A100 可以运行大多数模型训练,也容易接触到,但对于大型集群,可能还需要长期投入。
内存要求:大语言模型的参数计数太高,往往需要H100或A100,但是较小模型(例如稳定扩散)所需要的VRAM要少得多。虽然A100仍然很受欢迎,不过许多初创公司已开始使用A10,A40,A4000,A5000和A6000,甚至RTX卡。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

