

近期行情令人困惑,你应
比如一个班级的身高体重,一家公司的双十一业务情况,又比如一国的 GDP 及其趋势——如果要问大家「数据」是什么?
想必所有人都能快速下出定义,还能随手举出一系列通俗易懂的例子。因此,可以说「数据」离我们很近,近到它本就由我们产生或发送,近到可以依靠它来指导我们的生活。
但它仿佛又离我们极远,由手机、电脑收集正采集着大量有关个体的数据,或被简化成满屏的难以理解的 0 和 1,分散储存在不为人知的服务器里;或被塞入天花乱坠的结构化术语,被制作成五颜六色的图表。
作为生产者的我们,对于数据的理解和掌控好像愈发困难了。

为了让读者更深入地了解这个概念,网易区块链将开启有关于如何把握 Web3.0 时代下「数据」及未来趋势的连载专栏,从多个角度深入挖掘数据逻辑,分析技术变革时期数据重要性提升的缘由,描摹最具价值数据的样态,探寻攫取数据价值的多种场景。
数据是流动的,在不确定中找到确定性,是首期连载的目标所在。首篇论「数据」打开的正确方式,我们将讨论 Web 3.0 时代翩跹而至,它能否带领我们保护、理解甚至于重塑数据价值。
螺旋依旧,数据问题争论不休
数据流转的限度
数据存储与用户信息保护一直是用户难以消解的隐忧。近年来,数据泄漏事件不断消磨着用户对于数据采集、存储的信心。倘若用户将隐私信息上传中心化的存储设施,便意味着丧失了对信息的掌控权。一旦这些隐私信息发生数据丢失、泄露或被盗用,对于个人来说便是一场“社会性死亡”。
自 2013 年以来,Facebook 至少已经发生了 5 起数据泄露事件。2019 年泄漏事件甚至波及了 5.4 亿个账户,Facebook 解释称泄漏的都是「旧数据」,不会就本次事件向用户提出任何建议。
2016 年 12 月 14 日,雅虎宣布该公司有 10 亿多用户账号于 2013 年被黑客窃取。此次被盗的资料中可能包括姓名、联系方式、密码以及安全问答等内容,次年雅虎表示:所有 30 亿雅虎用户的个人信息被泄露,这一数字是 2016 年公布的 3 倍。

自《数据安全法》《个人信息保护法》先后实施,我们对数据安全和个人信息保护提出了更严格的要求。可以说,有关于数据治理,Web2.0 并没有提交一份令人满意的答卷。
数据使用的难度
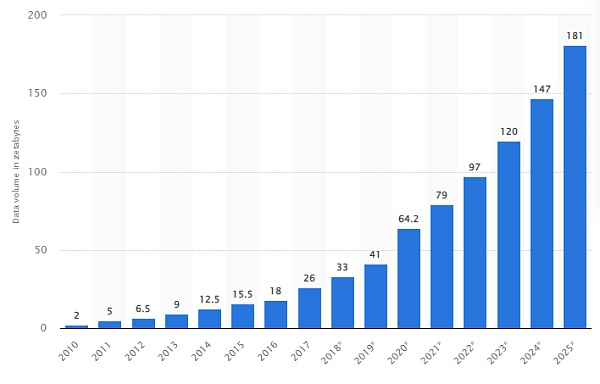
在大数据与物联网时代,万事万物都可称之为行走的「数据」源,也正因如此,数据存储的增长率也是惊人的:从 2010 年到 2020 年,全球创建、复制和消耗的数据/信息总量为 64.2 ZB,这一数字还正在增长。
根据 Statista 的数据,到 2025 年将超过 180 ZB。基于如此惊人的数据量增长,未来数据清洗和查验的难度可想而知。
这亦是Web2.0 数据孤岛所造成的负面影响之一。每打开一个应用,用户都要不厌其烦地完成一次注册,并可能在不知情的情况下,向应用开放了获许其他信息的权限。各个应用都掌握着自己的用户数据库,彼此独立,互不打通。
重复采集数据不仅会消耗大量的时间、网络带宽和计算资源,碎片化的采集状态,更限制了对数据的全面分析和挖掘,难以发现数据中的潜在价值和洞见。大量数据的唯一性和正确性等待处理,不同的数据源之间进行有效的比较和验证。
数据使用方需要花费大量的时间和资源来完成,加之提供者可能无法或不愿意提供详细的数据采集方法、处理流程或溯源信息,例如传统的无法原路自证的抽奖与摇号机制,这给使用方验证数据的真实性和可靠性增加难度。
显然,数据流通限制下的查验成为使用者无法绕过的难题。
数据价值的匹配
Web2.0 使更多用户能够交互并参与 Web 内容的创建,但并不是所有的用户获得了与之相匹配的权益。用户生成的内容不仅被用于提升用户的粘性,还有可能会被平台所有或被用于商业目的。
不少平台可能会收集和分析用户的数据,从中获取商业价值,例如通过广告定向或销售数据给第三方。

Twitter(现在名为 X) 已经准备将数据 API 作为服务,向用户打包售卖,数以亿计用户的登录信息与应用操作取向(包括屏幕截图、使用音频、广告的敏感度),正在或即将被转卖出去,在这个环节里,用户被当成了“数据劳工”,源源不断地哺育那些随意更改用户协议的平台和企业,此时用户就是产品本身。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

