

武昌警方打掉一涉案10亿元
原文来源:脑极体

图片来源:由无界 AI生成
这两天AI圈最热闹的消息,应该就OpenAI高层内讧,标志性人物、原CEO Sam Altman被董事会解雇,数位科学家和高层离职。
关于“政变”的原因,坊间有很多传言,比如商业化和非营利原则的矛盾。总之,事件相关者在舆论场拉扯,吃瓜群众则瞪大了眼睛看戏。这场风波会给全球AI研发,尤其是大模型带来什么影响,还是未知数。
有人做了一个梗图,大模型厂商乱成一锅粥,只有卖卡的英伟达稳坐钓鱼台。
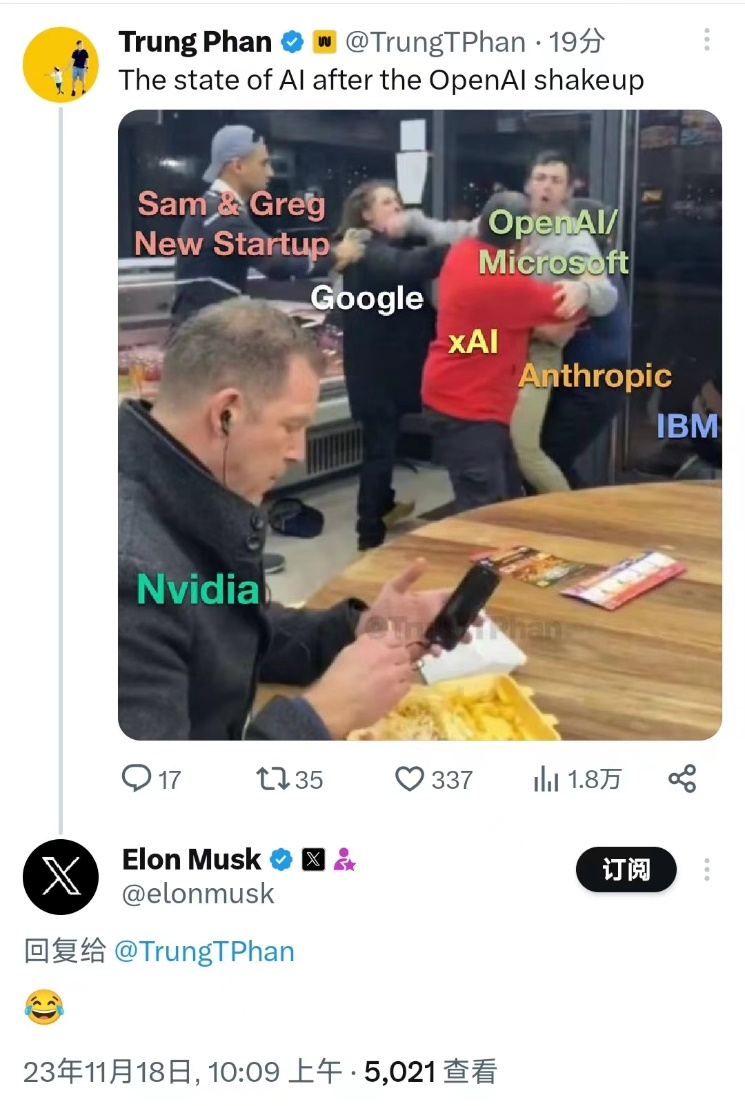
任它天边云卷云舒,可以肯定的是,中国的AI大模型在取得广泛成就的基础上,会继续向前发展,释放产业价值,并且不会一味照搬海外,尤其是OpenAI的模式。
带着这份淡定,我们将目光聚焦在国产大模型,会发现“百模大战”热潮中,还缺乏对各类大模型全面、分层、真实的能力评估。
通用大模型、行业大模型,都在比拼参数规模,但训练数据质量不确定,仅凭参数,行业客户和用户也难以选对适合的大模型。
那么看榜单呢?基准测试benchmark和标准化数据集,可以针对性调优,榜单无法反映实际应用效果差距。
而且大模型在不同任务场景下,表现的区分度很大。一位开发者说,“现在就是告诉你都有哪些大模型,实际效果还是得靠自己测测看”。
据中国信通院的数据显示,目前的大模型测试方法和数据集已有200多个。想要一个个测过来,会给用户带来非常繁重的工作量。
“百模大战”乱花渐欲迷人眼,那么,除了“跑分”打榜和参数“碾压”,还有什么办法来真实且有效地评判一个大模型的水平呢?
有必要来聊聊,“百模大战”,不同赛道都在战什么?
大模型,不看高分看高能
所谓“百模大战”,并不是每个大模型都在做着同样的事。其中,既有想做基座模型basemodle的通用大模型,如百度的文心、阿里的通义、腾讯的混元、华为的盘古、讯飞的星火、智谱的ChatGLM等,也有面向行业、场景的垂直大模型,目前在金融、教育、工业、传媒、政务等多个领域都大量涌现。
不同赛道的大模型,其核心竞争力也不一样。比如一味拼算法的打榜,对于行业大模型来说,可以作为一种宣传手段和“炫技”,但实际效果才是用户最关注的。
目前不少开发者反映,各类大模型都存在各自的问题。
1.基座模型,本身能力有限制。
提到通用大模型,大家可能第一时间想到的就是推理能力,这也是大模型基准测试的主要指标。但在实际应用中,尤其是文科类型任务,大家不会没事出“脑筋急转弯”来测试通用大模型的逻辑推理能力,而是更希望大模型在复杂任务和上下文长度上,有更可靠的表现。
比如写一篇演讲文稿,篇幅一长就开始胡说八道或泛泛而谈,文本的采用率下降;为AIGC配字幕,不能整篇生成,还需要人工将文案切割成片;编写一个程序,半路开始network error……这些都是实际应用中,大家比较关注的通用大模型的能力。
2.行业大模型,领域壁垒难翻越。
“百模大战”进行到当下,很多行业开发者和企业都意识到,独有的数据和场景,才是自己的护城河,开始打造定制化的大模型,而领域知识不够,难以形成满足某一领域需求的行业向产品。
比如大模型与行业知识不匹配、许多行业know-how还没有知识化、传统的知识图谱与大模型的协同设计等,知识计算的能力不够强,就无法真正撼动领域壁垒,让大模型解决实际的业务问题。
3.有用性,ROI是个谜。
大模型的实际应用效果难以评估,其中一个主要原因,就是模型生成结果的有用性(采用率、可用率等指标),涉及大量多模态数据。
金融、医药、交通、城市等产业中,存在着大量多模态信息,比如客服电话的语音、医学影像图片、传感器数据等,大语言模型必须具备多模态理解能力,将多模态信息与语言进行综合分析处理,才能保证较高质量的输出。
在实际任务中,上述三种问题可能会同时存在,要同时解决。
一位医药专家告诉我,在研发医学影像的算法时,就需要基座大模型在预训练阶段就具备多模态理解能力、医学影像知识,可以执行通用任务。同时,行业侧还需要根据知识设计目标函数,在特征抽取、相似性度量、迭代优化算法等,都要贡献好各自的知识,才可能训练出一个对医务工作者友好的领域大模型,不需要专业知识,也不需要建模,就能上手使用。
就像工业革命的开始,是因为瓦特改良了蒸汽机。在此之前,蒸汽机早已被发明出来了,但一直没有解决大规模高可用的问题,大模型也是如此。
大模型产业化,必须从基准测试的“跑高分”,向可信赖的“高能力”进化。
百模大战究竟在战哪些能力?
从高分到高能,让大模型具有与行业结合的可行性,也让“百模大战”正在进入新的阶段。
从产业实际需求来看,可用且有效的大模型,至少应该具备几个核心能力:
1.长文能力。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

