

英国将对未缴税款的加密
研究人员利用GPT4-Vision构建了一个大规模高质量图文数据集ShareGPT4V,并在此基础上训练了一个7B模型,在多项多模态榜单上超越了其他同级模型。
原文来源:新智元

图片来源:由无界 AI生成
OpenAI在九月份为ChatGPT添加了图像输入功能,允许用户使用上传一张或多张图像配合进行对话,这一新兴功能的背后是一个被OpenAI称为GPT4-Vision的多模态(vision-language)大模型。
鉴于OpenAI对「闭源」的坚持,多模态开源社区如雨后春笋般涌出了众多优秀的多模态大模型研究成果,例如两大代表作MiniGPT4和LLaVA已经向用户们展示了多模态对话和推理的无限可能性。
在多模态大模型(Large Multi-modal Models)领域,高效的模态对齐(modality alignment)是至关重要的,但现有工作中模态对齐的效果却往往受制于缺少大规模的高质量的「图像-文本」数据。
为了解决这一瓶颈,近日,中科大和上海AI Lab的研究者们最近推出了具有开创性意义的大型图文数据集ShareGPT4V。

论文地址:https://arxiv.org/abs/2311.12793Demo演示:https://huggingface.co/spaces/Lin-Chen/ShareGPT4V-7B项目地址:https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V
ShareGPT4V数据集包含120万条「图像-高度详细的文本描述」数据,囊括了了世界知识、对象属性、空间关系、艺术评价等众多方面,在多样性和信息涵盖度等方面超越了现有的数据。

表1 ShareGPT4V和主流标注数据集的比较。其中「LCS」指LAION, CC和SBU数据集,「Visible」指明了图片在被标注时是否可见,「Avg.」展示了文本描述的平均英文字符数。
目前,该数据集已经登上了Hugging Face Datasets Trending排行第一。
数据
ShareGPT4V来源于从先进的GPT4-Vision模型获得的10万条「图像-高度详细的文本描述」数据。
研究者们从多种图片数据源(如COCO,LAION,CC,SAM等)搜集图片数据,接着使用各自数据源特定的prompt来控制GPT4-Vision产生高质量的初始数据。
如下图所示,给GPT4-Vision模型一张《超人》剧照,其不仅可以准确地识别出《超人》剧照中的超人角色以及其扮演者Henry Cavill,还可以充分分析出图像内物体间的位置关系以及物体的颜色属性等。
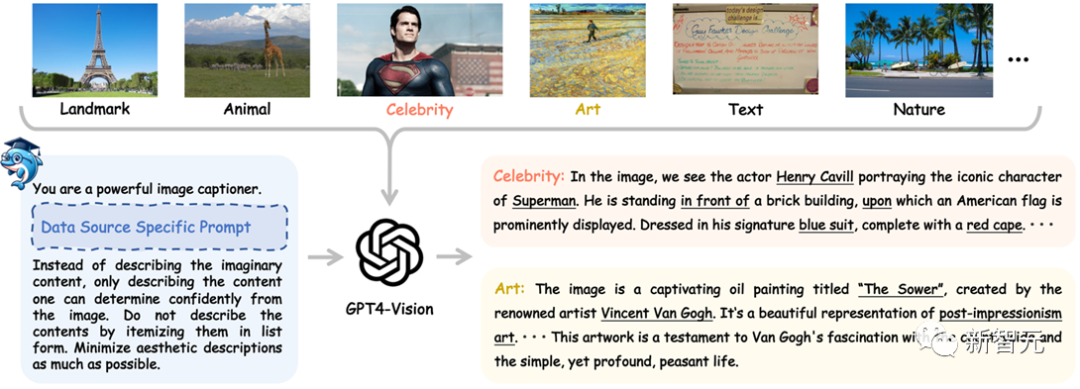
图1 利用GPT4-Vision 收集ShareGPT4V原始数据流程图
如果给GPT4-Vision模型一个梵高的画作《播种者》,其不仅可以准确地识别出画作的名称,创作者,还可以分析出画作所属的艺术流派,画作内容,以及画作本身表达出的情感与想法等信息。
为了更充分地与现有的图像描述数据集进行对比。我们在下图中将ShareGPT4V数据集中的高质量文本描述与当前多模态大模型所使用的数据集中的文本描述一起罗列出来:

图 2 「图片-文本描述」数据质量对比图
从图中可以看出,使用人工标注的COCO数据集虽然正确但通常十分的短,提供的信息极其有限。
LLaVA数据集使用语言模型GPT4想象出的场景描述通常过度依赖bounding box而不可避免地带来幻觉问题。比如bounding box确实会提供8个人的标注,但其中两个人在火车上而不是在等车。
其次,LLaVA数据集还只能局限于COCO的标注信息,通常会遗漏人工标注中没提及的内容(比如树木)。
在比较之下,我们收集的图像描述不仅可以给出综合性的描述,还不容易遗漏图像中的重要信息(比如站台信息和告示牌文字等)。
通过在该初始数据上进行深入训练后,研究者们开发出了一个强大的图像描述模型Share-Captioner。利用这一模型,他们进一步生成了120万高质量的「图片-文本描述」数据ShareGPT4V-PT以用于预训练阶段。

图3 图像描述模型扩大数据集规模流程图
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

