

Sam Altman回归后首次专访:
原文来源:机器之心

图片来源:由无界 AI生成
目前,通义千问开源全家桶已经有了 18 亿、70 亿、140 亿、720 亿参数量的 4 款基础开源模型,以及跨语言、图像、语音等多种模态的多款开源模型。
「Qwen-72B 模型将于 11 月 30 日发布。」前几天,X 平台上的一位网友发布了这样一则消息,消息来源是一段对话。他还说,「如果(新模型)像他们的 14B 模型一样,那将是惊人的。」
有位网友转发了帖子并配文「千问模型最近表现不错」。
这句话里的 14B 模型指的是阿里云在 9 月份开源的通义千问 140 亿参数模型 Qwen-14B。当时,这个模型在多个权威评测中超越同等规模模型,部分指标甚至接近 Llama2-70B,在国内外开发者社区中非常受欢迎。在之后的两个月里,用过 Qwen-14B 的开发者自然也会对更大的模型产生好奇和期盼。
看来,日本的开发者也在期待。
正如消息中所说的,11 月 30 日,Qwen-72B 开源了。它以一己之力让追开源动态的国外开发者也过上了杭州时间。
阿里云还在今天的发布会上公布了很多细节。

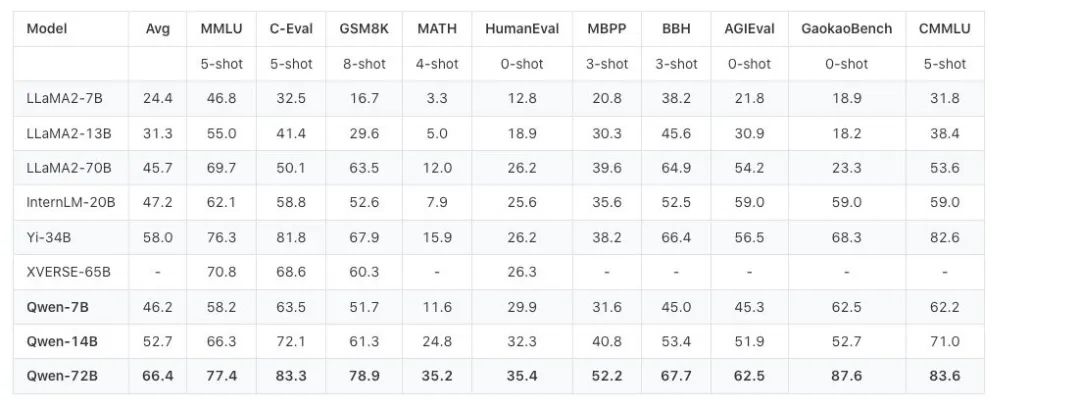
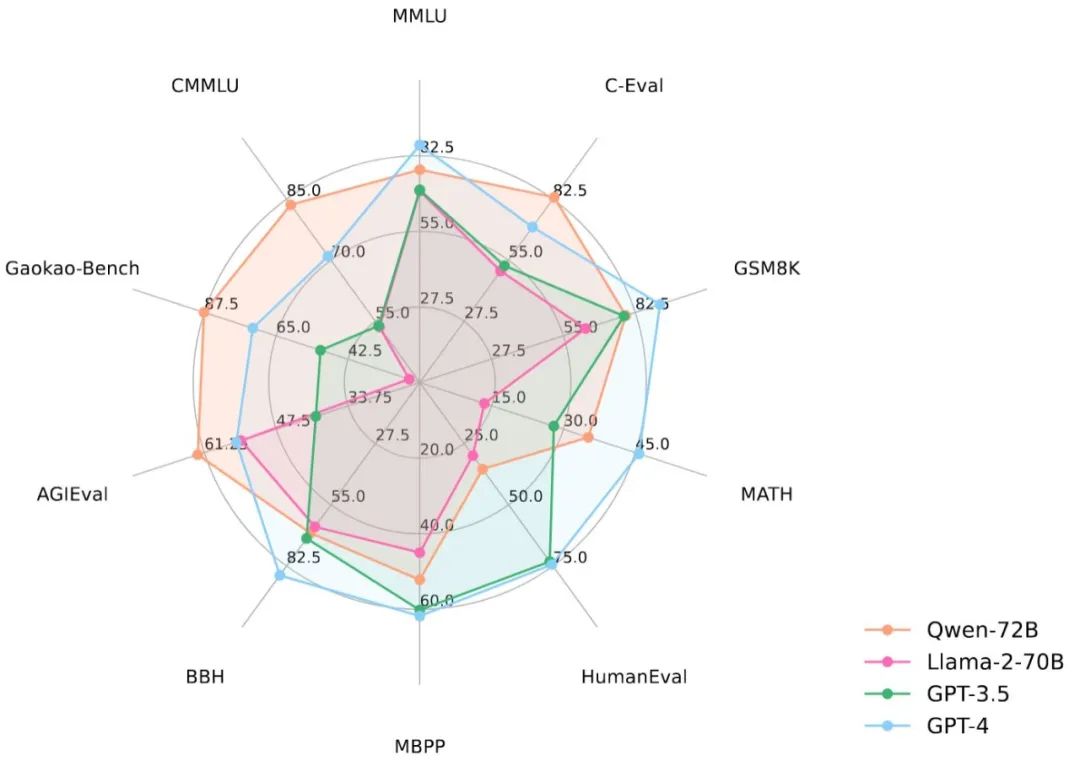
从性能数据来看,Qwen-72B 没有辜负大家的期盼。在 MMLU、AGIEval 等 10 个权威基准测评中,Qwen-72B 都拿到了开源模型的最优成绩,成为性能最强的开源模型,甚至超越了开源标杆 Llama 2-70B 和大部分商用闭源模型(部分成绩超越 GPT-3.5 和 GPT-4)。
要知道,在此之前,中国大模型市场还没有出现足以对抗 Llama 2-70B 的优质开源大模型,Qwen-72B 填补了这一空白。之后,国内大中型企业可基于它的强大推理能力开发商业应用,高校、科研院所可基于它开展 AI for Science 等科研工作。
此外,一起发布的还有一个小模型 ——Qwen-1.8B,以及一个音频模型 Qwen-Audio。Qwen-1.8B 和 Qwen-72B 一小一大,加上之前已经开源的 7B、14B 模型,组成了一个完整的开源光谱,适配各种应用场景。Qwen-Audio 和之前开源的视觉理解模型 Qwen-VL 以及基础文本模型则组成了一个多模态光谱,可以帮助开发者把大模型的能力扩展到更多真实环境。

通义千问最小开源模型Qwen-1.8B,推理2K长度文本内容仅需3G显存。看来,希望在手机等端侧部署语言模型的开发者可以上手一试。
这种「全尺寸、全模态」的开源力度,业界无出其右。Qwen-72B 更是抬升了开源模型尺寸和性能的天花板。为了验证这一开源模型的能力,机器之心在阿里云魔搭社区上手体验了一番,并讨论了通义千问开源模型对于开发者的吸引力所在。
第一手体验:
推理更强,还能自定义角色
下图是 Qwen-72B 的用户界面。你可以在下方「Input」框输入想要问的问题或其他交互内容,中间框会输出答案。目前,Qwen-72B 支持中文和英文输入,这也是通义千问和 Llama2 差别比较大的一点。此前,Llama2 中文支持不佳让很多国内开发者很头疼。
体验地址:https://modelscope.cn/studios/qwen/Qwen-72B-Chat-Demo/summary
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

