

Starknet生态Dapp已超过170个
文章来源:机器之心
站在巨人的肩膀上会让你看的更远,而通过让大规模语言模型来「教」较小规模的语言模型进行推理,也会是事半功倍的效果。

图片来源:由无界 AI生成
如你我所见,像 GPT-4、PaLM 等前沿语言模型已经展现了出色的推理能力,例如回答复杂问题、生成解释,甚至解决需要多步推理的问题,这些能力曾被认为是 AI 无法达到的。这样的能力在较小的语言模型中并不明显,因此现在的挑战就是如何利用对大型语言模型不断增长的知识,进而提升较小模型的能力。
之前微软研究院推出了 Orca,它是拥有 130 亿参数的语言模型,通过模仿更强大 LLM 的逐步推理过程,展现了强大的推理能力。
现在研究者再接再厉推出了 Orca 2,继续探索如何通过改进训练信号来提升较小语言模型的推理能力。

训练小型语言模型的研究通常依赖于模仿学习,以复现更强大模型的输出。过分强调模仿可能会限制较小模型的潜力。研究者的想法是致力于教导小型语言模型在不同任务中使用不同的解决策略,这些策略可能与更大模型使用的不同。更大的模型可能对复杂任务直接提供答案,但较小模型或许没有相同的能力。
在 Orca 2 中,研究者教给模型各种推理技巧(逐步推理、先回忆再生成、回忆 - 推理 - 生成、直接回答等),这样做旨在帮助模型学会为每个任务确定最有效的解决策略。
研究者使用「包括大约 100 个任务和超过 36,000 个独特提示」的全面集合的 15 个不同基准来评估 Orca 2。在 Zero-shot 环境中对高级推理能力进行评估的复杂任务中,Orca 2 明显超越了相似规模的模型,并达到了与 5-10 倍大型模型相似或更好的性能水平。Orca 2 已经开源,以鼓励人们在较小语言模型的开发、评估和对齐方面进行更深入的研究。
Orca 2 有两个规模(70 亿和 130 亿参数),均通过在定制高质量合成数据上对相应的 LLaMA 2 基础模型进行微调而创建。
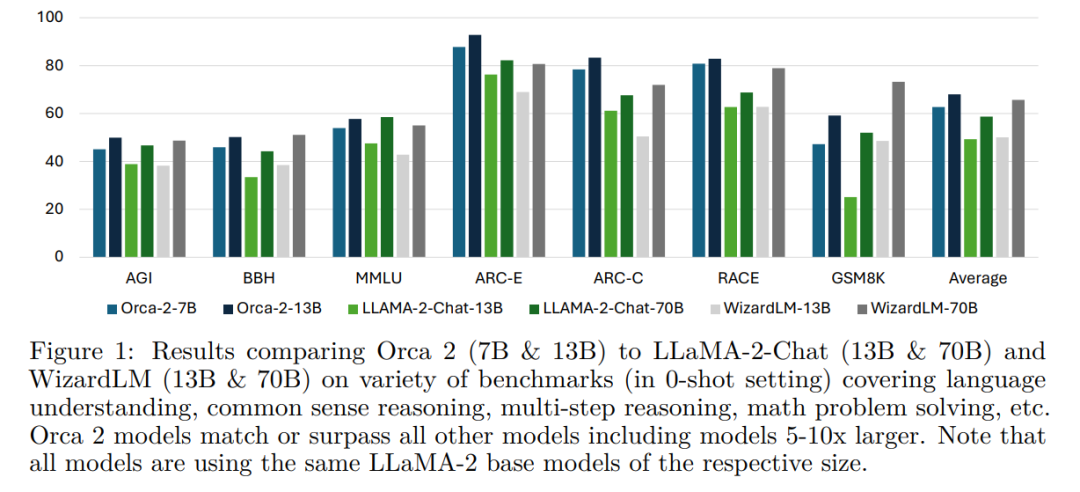
图 1:Orca 2(7B 和 13B)与 LLaMA-2-Chat(13B 和 70B)以及 WizardLM(13B 和 70B)在各种基准测试上的结果 (zero-shot),涵盖了语言理解、常识推理、多步推理、数学问题解决等。Orca 2 模型的表现不逊于或超越包括 5-10 倍更大的模型在内的所有其他模型。这里所有模型都使用相同尺寸的 LLaMA 2 基础模型。

图 2:演示 Orca 2、其基础模型 LLaMA 2、LLaMA 2-Chat 和 ChatGPT(GPT-3.5-Turbo)对一个推理问题的响应的示例。LLaMA 2 和 LLaMA 2-Chat 模型的响应分别使用 replicate.com/meta/llama-2-13b 和 chat.lmsys.org 生成。
Orca 2 可以给出一个有力的推测即不同的任务可能受益于不同的解决策略(如逐步处理、回忆后生成、回忆 - 推理 - 生成、提取 - 生成和直接回答),并且大型模型采用的解决策略可能不是较小模型的最佳选择。例如,虽然像 GPT-4 这样的模型可能轻松生成直接回答,但是较小的模型可能缺乏这种能力,需要采用不同的方法,如逐步思考。
因此,单纯地教导较小模型「模仿」更强大模型的推理行为可能并不是最优的选择。虽然将较小模型训练成逐步解释答案已被证明是有益的,但在多种策略上进行训练使其能够更灵活地选择适合任务的策略。
研究者使用「谨慎推理」(Cautious Reasoning)来指代决定为给定任务选择哪种解决策略的行为,包括直接生成答案,或者采用多种「慢思考」策略之一(如逐步、猜测和检查或先解释后回答等)。
以下是训练谨慎推理 LLM 的过程:
1. 从多样化的任务集开始。
2. 依据 Orca 的性能,决定哪些任务需要哪种解决策略(例如直接回答、逐步处理、先解释后回答等)。
3. 为每个任务编写相应于所选策略的特定系统指导,以获得每个任务的「教师」系统的响应。
4. 提示擦除:在训练时,用不包含如何处理任务细节的通用指令替换「学生」系统的指令。
注意一点,第 3 步中广泛的获取「教师」系统的响应:它可以利用多个调用、非常详细的指令等。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

