

BTC期权未平仓合约达到约
原文来源:机器之心

图片来源:由无界 AI生成
对于 2023 年的计算机视觉领域来说,「分割一切」(Segment Anything Model)是备受关注的一项研究进展。

Meta四月份发布的「分割一切模型(SAM)」效果,它能很好地自动分割图像中的所有内容
Segment Anything 的关键特征是基于提示的视觉 Transformer(ViT)模型,该模型是在一个包含来自 1100 万张图像的超过 10 亿个掩码的视觉数据集 SA-1B 上训练的,可以分割给定图像上的任何目标。这种能力使得 SAM 成为视觉领域的基础模型,并在超出视觉之外的领域也能产生应用价值。
尽管有上述优点,但由于 SAM 中的 ViT-H 图像编码器有 632M 个参数(基于提示的解码器只需要 387M 个参数),因此实际使用 SAM 执行任何分割任务的计算和内存成本都很高,这对实时应用来说具有挑战性。后续,研究者们也提出了一些改进策略:将默认 ViT-H 图像编码器中的知识提炼到一个微小的 ViT 图像编码器中,或者使用基于 CNN 的实时架构降低用于 Segment Anything 任务的计算成本。
在最近的一项研究中,Meta 研究者提出了另外一种改进思路 —— 利用 SAM 的掩码图像预训练 (SAMI)。这是通过利用 MAE 预训练方法和 SAM 模型实现的,以获得高质量的预训练 ViT 编码器。

这一方法降低了 SAM 的复杂性,同时能够保持良好的性能。具体来说,SAMI 利用 SAM 编码器 ViT-H 生成特征嵌入,并用轻量级编码器训练掩码图像模型,从而从 SAM 的 ViT-H 而不是图像补丁重建特征,产生的通用 ViT 骨干可用于下游任务,如图像分类、物体检测和分割等。然后,研究者利用 SAM 解码器对预训练的轻量级编码器进行微调,以完成任何分割任务。
为了评估该方法,研究者采用了掩码图像预训练的迁移学习设置,即首先在图像分辨率为 224 × 224 的 ImageNet 上使用重构损失对模型进行预训练,然后使用监督数据在目标任务上对模型进行微调。
通过 SAMI 预训练,可以在 ImageNet-1K 上训练 ViT-Tiny/-Small/-Base 等模型,并提高泛化性能。对于 ViT-Small 模型,研究者在 ImageNet-1K 上进行 100 次微调后,其 Top-1 准确率达到 82.7%,优于其他最先进的图像预训练基线。
研究者在目标检测、实例分割和语义分割上对预训练模型进行了微调。在所有这些任务中,本文方法都取得了比其他预训练基线更好的结果,更重要的是在小模型上获得了显著收益。
论文作者 Yunyang Xiong 表示:本文提出的 EfficientSAM 参数减少了 20 倍,但运行时间快了 20 倍,只与原始 SAM 模型的差距在 2 个百分点以内,大大优于 MobileSAM/FastSAM。

在 demo 演示中,点击图片中的动物,EfficientSAM 就能快速将物体进行分割:

EfficientSAM 还能准确标定出图片中的人:
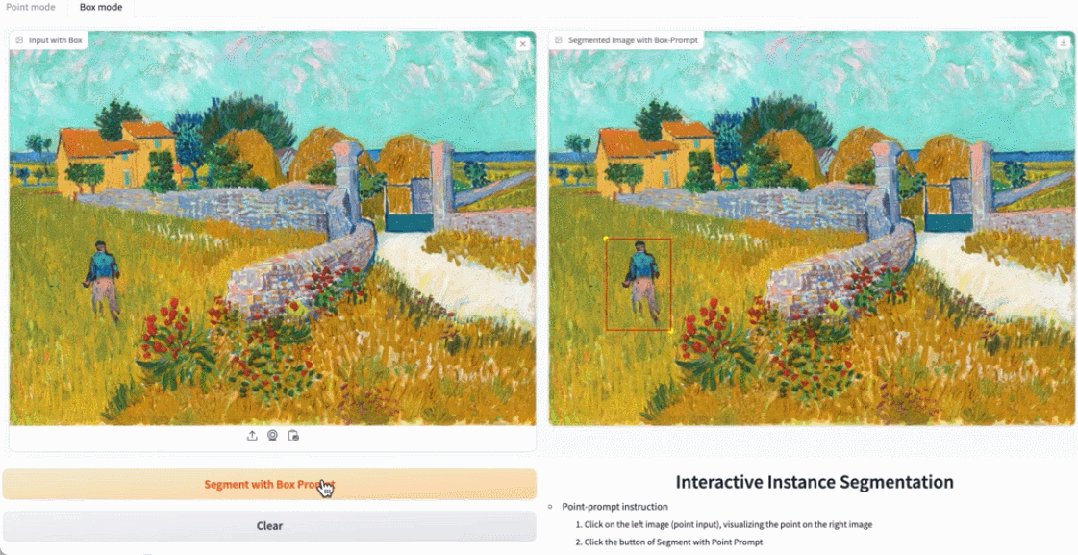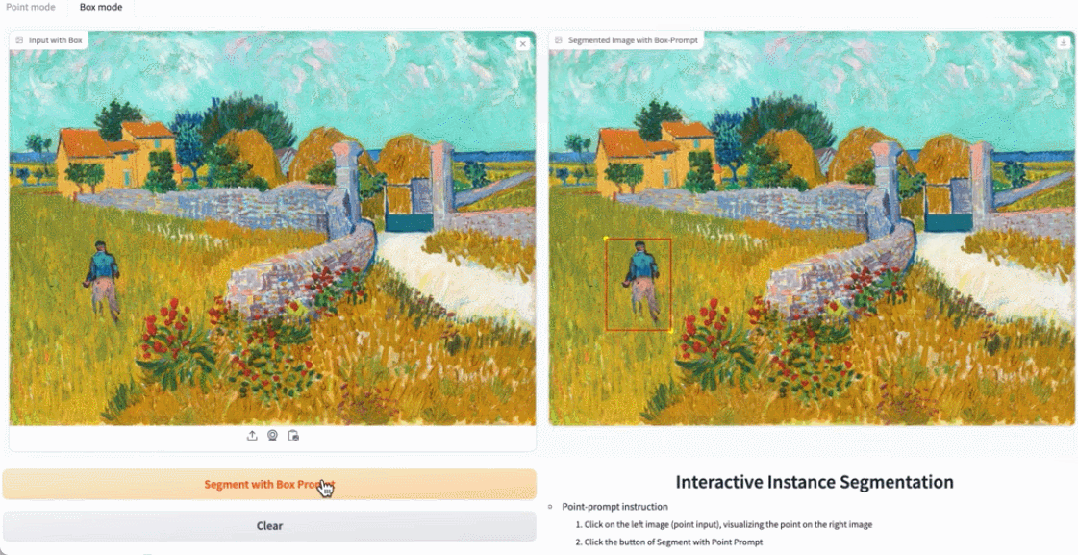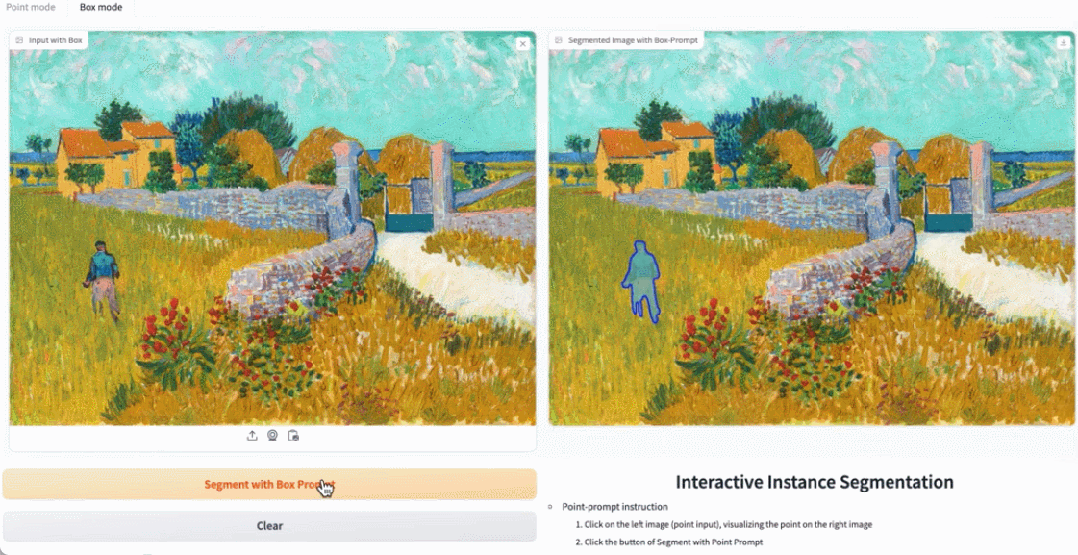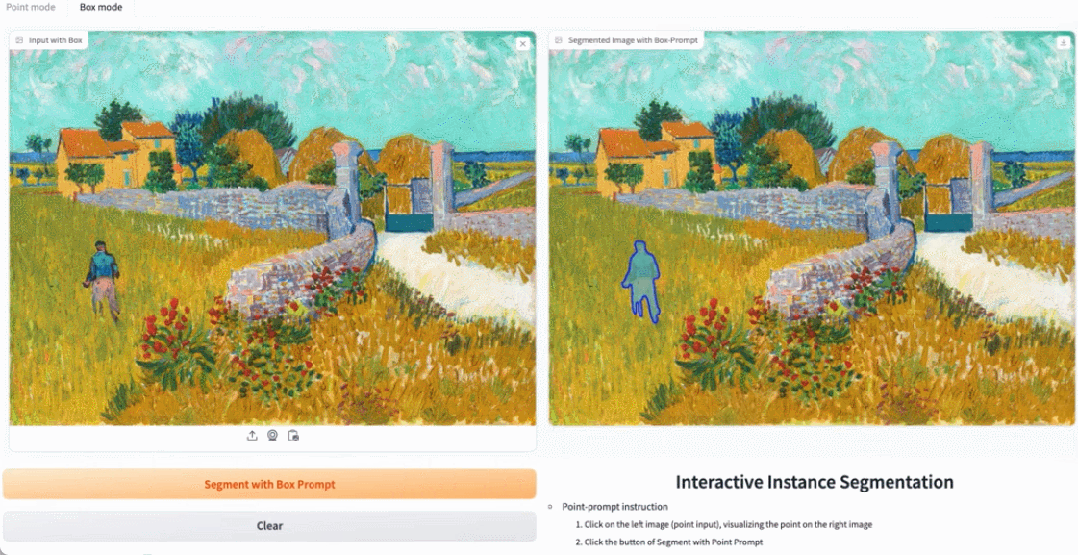
试玩地址:https://ab348ea7942fe2af48.gradio.live/
方法
EfficientSAM 包含两个阶段:1)在 ImageNet 上对 SAMI 进行预训练(上);2)在 SA-1B 上微调 SAM(下)。
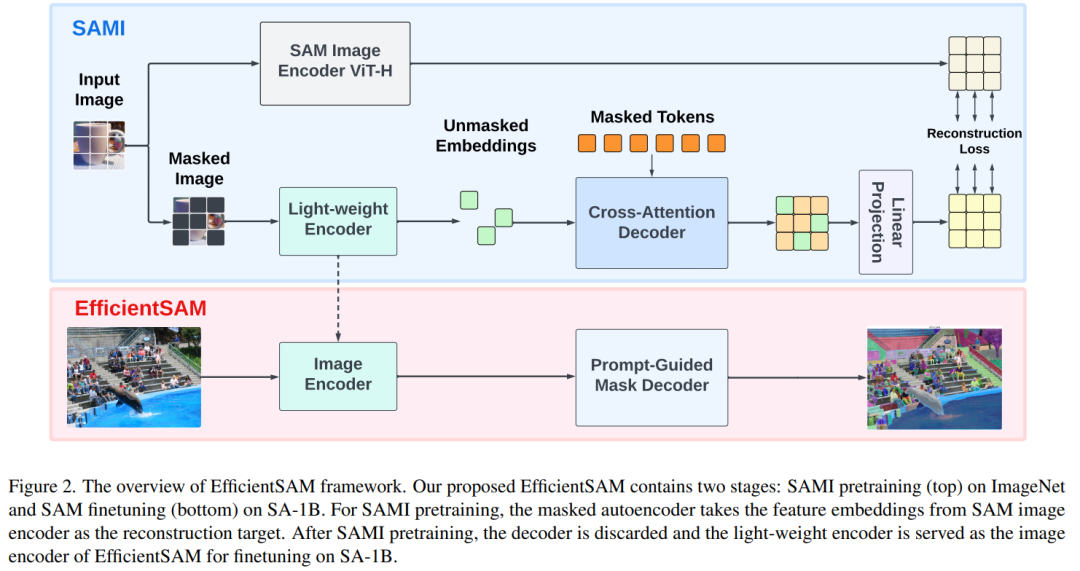
EfficientSAM 主要包含以下组件:
交叉注意力解码器:在 SAM 特征的监督下,本文观察到只有掩码 token 需要通过解码器重建,而编码器的输出可以在重建过程中充当锚点(anchors)。在交叉注意力解码器中,查询来自于掩码 token,键和值源自编码器的未掩码特征和掩码特征。本文将来自交叉注意力解码器掩码 token 的输出特征和来自编码器的未掩码 token 的输出特征进行合并,以进行 MAE 输出嵌入。然后,这些组合特征将被重新排序到最终 MAE 输出的输入图像 token 的原始位置。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

