

BTC期权未平仓合约达到约
原文来源:自象限

图片来源:由无界 AI生成
AI原生应用,“难产”了。
百模大战后,一众精疲力竭的创业者们逐渐反应过来:中国真正的机会在应用层,AI原生应用才是下一轮最肥沃的土壤。
李彦宏、王小川、周鸿祎、傅盛,盘点过去几个月的大佬发言,无一不在着重强调应用层的巨大机遇。
互联网巨头们把AI原生挂在嘴边:百度一口气发布超20款AI原生应用;字节跳动成立了新团队,主攻应用层;
腾讯将大模型嵌入了小程序;阿里也要用通义千问将所有应用重新做一遍;Wps疯狂赠送AI体验卡..
创业公司更是狂热,一场黑客马拉松下来,近乎200个AI原生项目。今年以来,包括奇绩创坛、百度、Founder Park大大小小加起来,数十场活动,上千个项目,最后却没有一个跑出来。
不得不正视的是,尽管我们意识到了应用层的巨大机遇,但大模型并没有颠覆所有应用,所有产品都在不痛不痒地改造。尽管,中国有最优秀的产品经理,但他们这回也“失灵”了。
从4月份Midjourney爆火,到现在,9个月的时间,汇集了“全村人希望”的国产AI原生应用,究竟为何难产?
选择比努力更重要,在当下,或许我们更需要冷静回望,寻找正确打开AI原生应用的“姿势”。
做AI原生,不能端到端
原生应用为何难产?我们或许可以从原生应用的“生产”过程中找到一些答案。
“我们通常会同时跑四五个模型,哪个性能更优就选择哪个。”硅谷的一位大模型创业者在与「自象限」交流时提到,他们基于基础大模型开发AI应用,但前期并不绑定某一个大模型,而是让每一个模型都上来跑一跑,最终选择最合适的那个。
简单来说,赛马机制如今也卷到了大模型身上。
但这种方式其实仍存在一些弊端,因为它虽然选择了不同大模型进行尝试,但最终还是会与其中某一个大模型进行深度耦合,这还是一种“端到端”的研发思路,即一个应用对应一个大模型。
但与应用不同,作为底层大模型,它同时又却会对应多个应用,这就导致了同一个场景下的不同应用之间,最后的差异十分有限。而更大的问题在于,目前市场上的基础大模型都各有所长的同时也各有所短,还没有某个大模型成为六边形战士,在所有领域遥遥领先,所以这导致基于一个大模型开发的应用最终难以在各个功能上实现平衡。
在这样的背景下,大模型与应用解耦就成了一种新的思路。
所谓“解耦”其实分为两个环节。
首先是大模型与应用解耦。作为AI原生应用的底层驱动力,大模型和原生应用之间的关系其实可以和汽车行业进行类比。
▲图片来源于网络
对于AI原生应用来说,大模型就像是汽车的发动机。同样一款发动机可以适配不同的车型,同一款车型也可以匹配不同的发动机,通过不同的调教,可以实现从微型车到豪华车的不同定位。
所以对于整车来说,发动机只是整体配置的一个部分,而不能成为定义整辆汽车的核心。
类比到AI原生应用,基础大模型是驱动应用的关键,但基础大模型并不应该与应用实现完全绑定。一个大模型可以驱动不同的应用,同一个应用也应该可以由不同的大模型进行驱动。
这样的例子其实在目前的案例中已经有了体现,比如国内的飞书、钉钉,国外的Slack,都可以适配不同的基础大模型,用户可以根据自身需要进行选择。
其次是在具体的应用当中,大模型与不同的应用环节应该层层解耦。
一个典型的例子是HeyGen,这是一家在国外爆火的AI视频公司,它的年度经常性收入在今年3月份就达到了 100万美元,并在今年11月达到1800 万美元。
HeyGen 目前拥有 25 名员工,但它已经建立了自己的视频 AI 模型,并同时集成了 OpenAI 和 Anthropic 的大型语言模型 和 Eleven Labs 的音频产品。基于不同的大模型,HeyGen制作一个视频就会在创作、脚本生成(文本)、声音等不同的环节用上不同的模型。
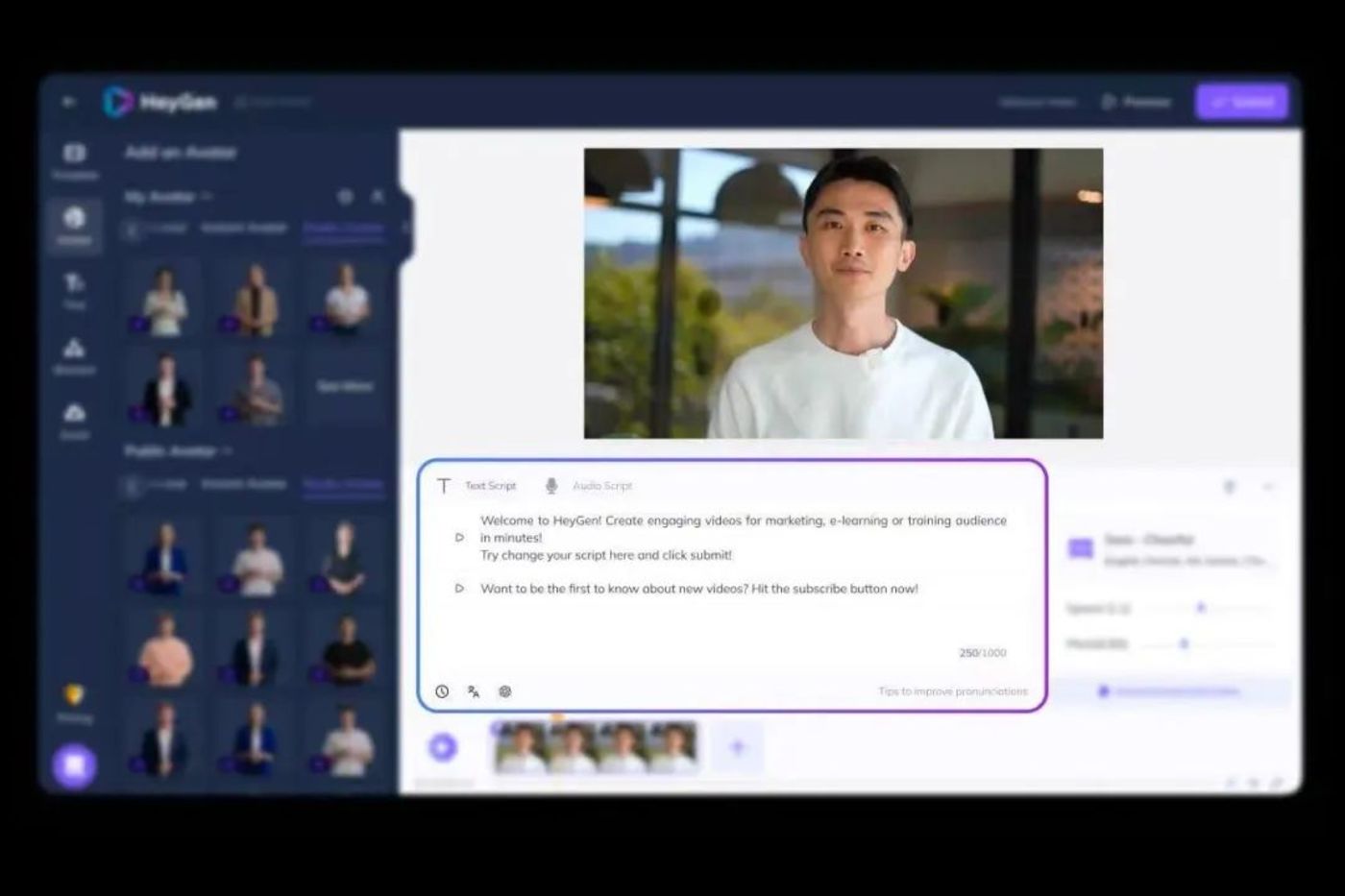
▲图源HeyGen官网
另一个更直接的案例是ChatGPT的插件生态,最近国内剪辑应用剪映加入了ChatGPT的生态池,在这之后,用户在ChatGPT上要求调用剪映的插件制作视频,剪映就能在ChatGPT的驱动下自动生成一个视频。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

