

币安撤回阿布扎比牌照申
原文来源:硅星人
作者:Jessica

图片来源:由无界 AI生成
昨天谷歌深夜炸场,隆重推出他们史上“规模最大、能力最强”的原生多模态大模型Gemini 1.0。并称已在多项基准测试中打败GhatGPT,综合能力称霸目前市面上所有AI大模型。
官方放出的一段6分22秒演示视频更是震撼:Gemini能流畅而准确地识别出视频中出现的事物、教授中文发音、玩猜谜游戏、根据画的乐器播放音乐….一波互动简直无限接近于人。

不过很快,这支视频就被人说并非实时录制,而是多次尝试和挑选后“精心剪辑”的节目效果。
谷歌后续自己放出的博客文章中也显示,实现这样的多模态交互过程需要经过多步图片和提示词调试。
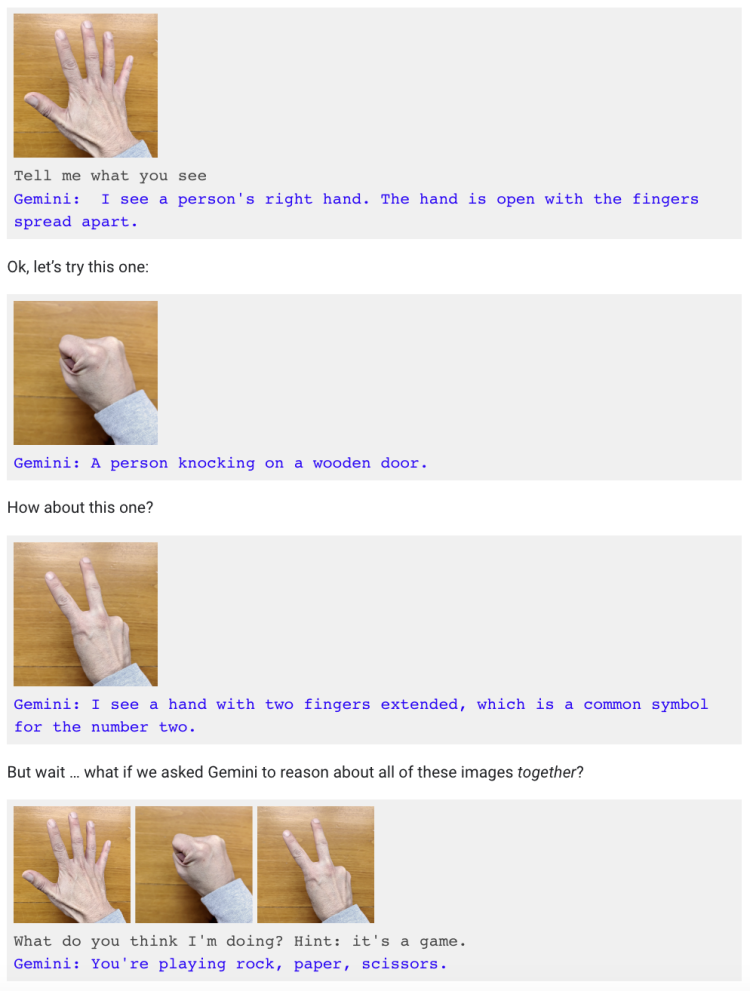
比如“喂”了多张手势图片后,让Gemini回答这是在做什么,提示思路是游戏。而视频中仅面对手势动作,Gemini就主动表示“我知道你在玩剪刀石头布”。
再比如排出太阳、地球和土星照片问Gemini是否为正确顺序,同样提示要考虑到太阳的距离并要求解释原因。可视频里的 Gemini又是在没有任何参考的情况下纠正了排序。

除此之外,对于谷歌自豪亮出的,Gemini Ultra在MMLU( 大规模多任务语言理解 )测试中跑分超过 GPT-4和人类专家这件事,人们冷静下来仔细一看,也发现了些小心思:
在Gemini Ultra 90.0%的分数下面,非常不起眼地标着CoT@32,意思是“使用了思维链提示技巧、尝试32次选最好结果”;而GPT-4 86.4%分数下却是5-shot,表面只进行“5次示例且无提示词”——谷歌给自己和对家安排的标准都不一样,根本无法公平公正地比较。
Hugging Face 技术主管Philipp Schmid直接用谷歌60页Gemini 技术报告中的数据重新作图。并在X发文指出,如果同样采用5-shot,Gemini Ultra的分数只有83.7%,实则是不如GPT-4的。
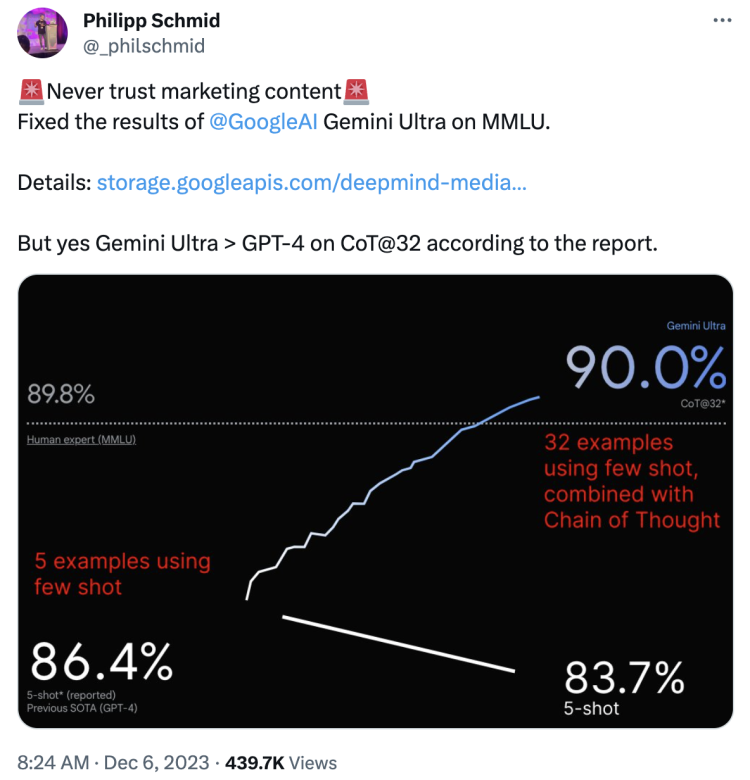
不过好在如果也给GPT-4来个32次尝试+思维链提示,还是Gemini胜。
谷歌耍了些扬长避短的小花样,但也不至于完全撒谎。
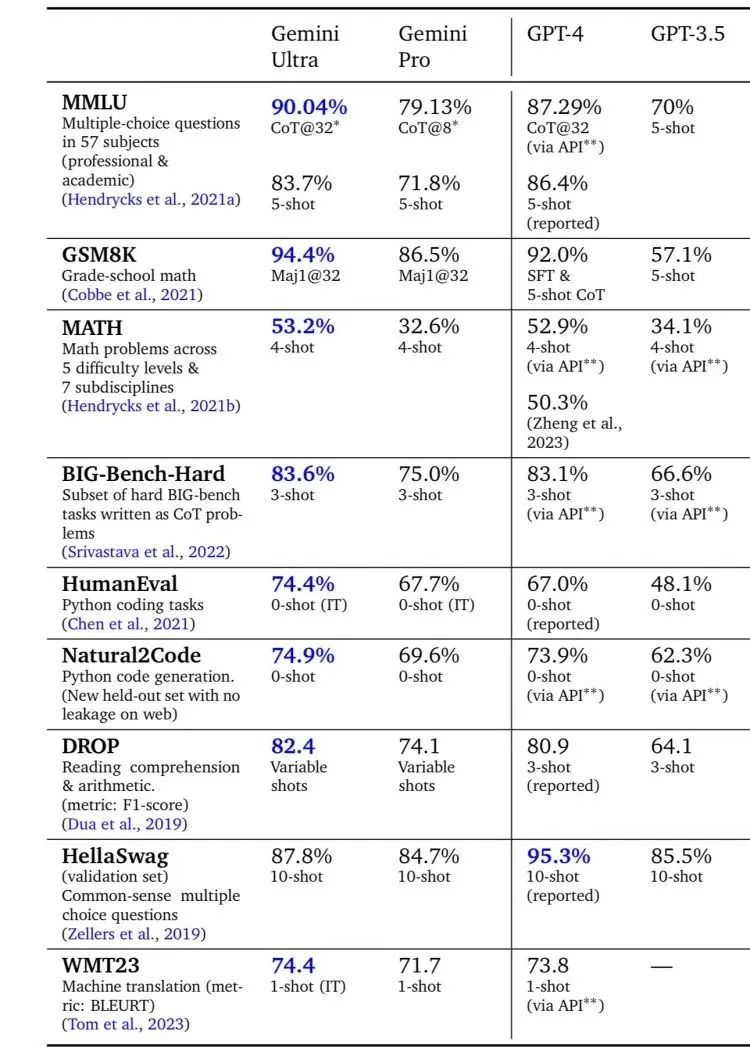
在上图中也可以看出,这次发布的 Gemini1.0全系列里,除了“超大杯”Gemini Ultra外,“大杯”Gemini Pro也在八项基准测试的六项中打败了对标的GPT-3.5。
现在,用户能玩到的Google Bard里接入的就是Gemini Pro。
于是硅星人也赶紧上手操作了一下,实测它和最新版本的GPT-4V到底哪个更厉害。

由于Google官方表示目前Gemini Pro只能为170个国家和地区提供英语服务,所以咱们先用英文提问。
首先热个身,试试最简单的文本生成能力:让Bard和ChatGPT分别写一段夸奖自己的Rap,并且和对方battle,来个下马威。
Bard一顿猛烈输出,主歌、副歌、桥接、结尾几大说唱歌曲元素一个不落。表示自己是真正的OG,拥有更庞大的知识库还能访问网络,但GPT只是“困在过去”。(不过现在GPT-4已经集成了微软Bing搜索,也可以访问实时信息。)

ChatGPT这边相对精简,主打自己是一个快速冲刺的人工智能,“Google有名气,但我有真本事”。

好吧,都挺会说的。不过既然Gemini最标榜的是自己的原生多模态能力,那就在多模态上让它俩比比。
拿一张今年9月刚上市的iPhone 15 Pro Max图片,让它们认认这是什么。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier
