

为什么说比特币生态必将
前几日,一条MoE的磁力链接引爆AI圈。刚刚出炉的基准测试中,8*7B的小模型直接碾压了Llama 2 70B!网友直呼这是初创公司版的超级英雄故事,要赶超GPT-4只是时间问题了。有趣的是,创始人姓氏的首字母恰好组成了「L.L.M.」。
原文来源:新智元

图片来源:由无界 AI生成
开源奇迹再一次上演:Mistral AI发布了首个开源MoE大模型。
几天前,一条磁力链接,瞬间震惊了AI社区。
87GB的种子,8x7B的MoE架构,看起来就像一款mini版「开源GPT-4」!
无发布会,无宣传视频,一条磁力链接,就让开发者们夜不能寐。
这家成立于法国的AI初创公司,在开通官方账号后仅发布了三条内容。
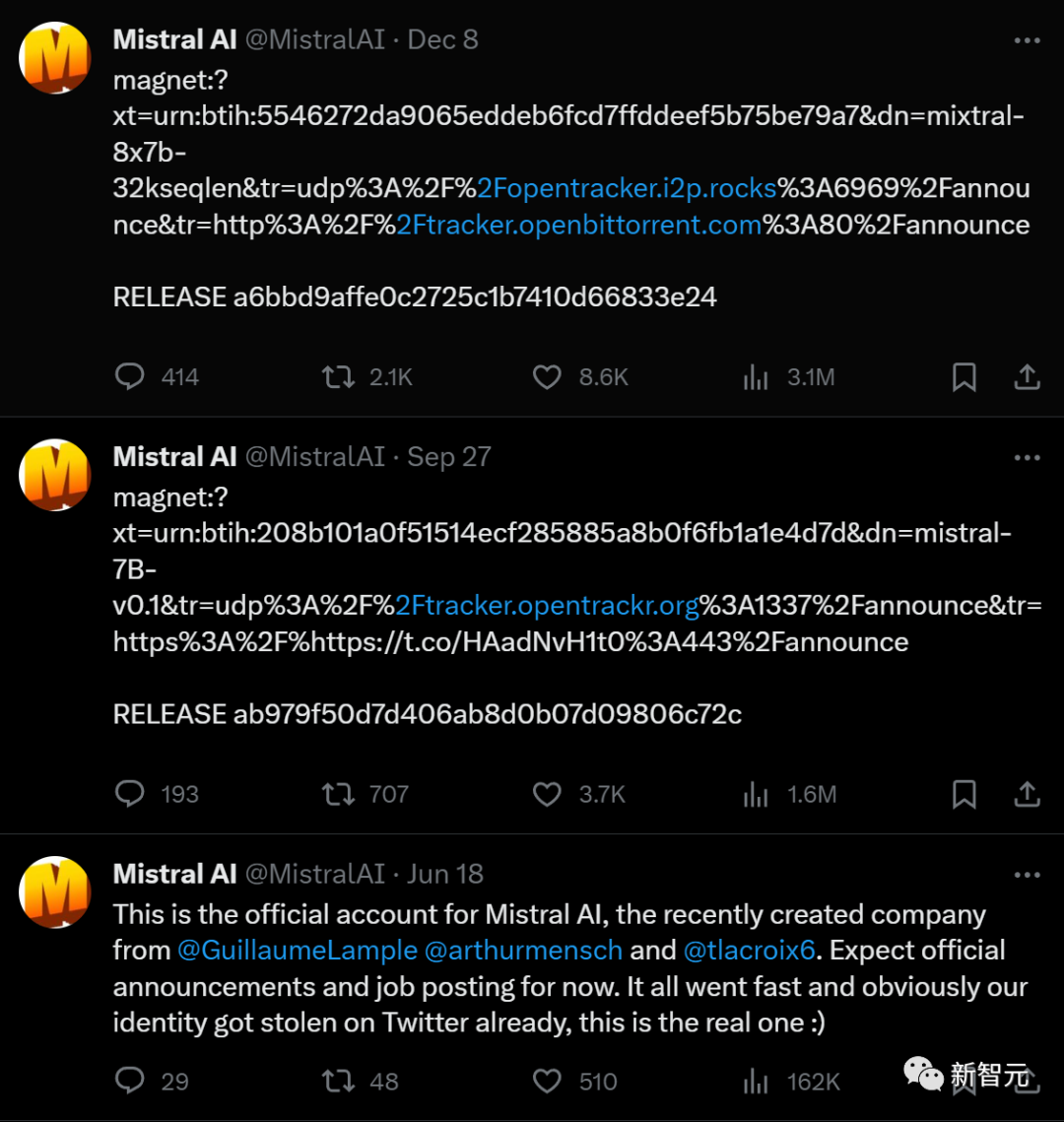
6月,Mistral AI上线。7页PPT,获得欧洲历史上最大的种子轮融资。
9月,Mistral 7B发布,号称是当时最强的70亿参数开源模型。
12月,类GPT-4架构的开源版本Mistral 8x7B发布。几天后,外媒金融时报公布Mistral AI最新一轮融资4.15亿美元,估值高达20亿美元,翻了8倍。
如今20多人的公司,创下了开源公司史上最快增长纪录。

所以,闭源大模型真的走到头了?
8个7B小模型,赶超700亿参数Llama 2
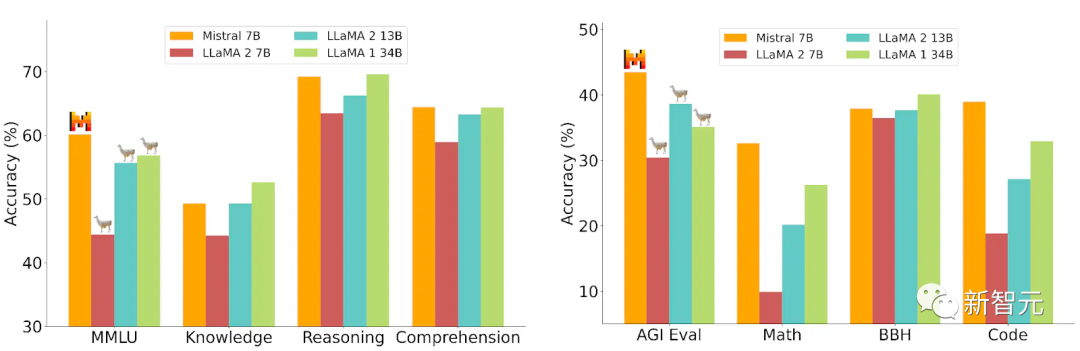
更令人震惊的是,就在刚刚,Mistral-MoE的基准测试结果出炉——
可以看到,这8个70亿参数的小模型组合起来,直接在多个跑分上超过了多达700亿参数的Llama 2。
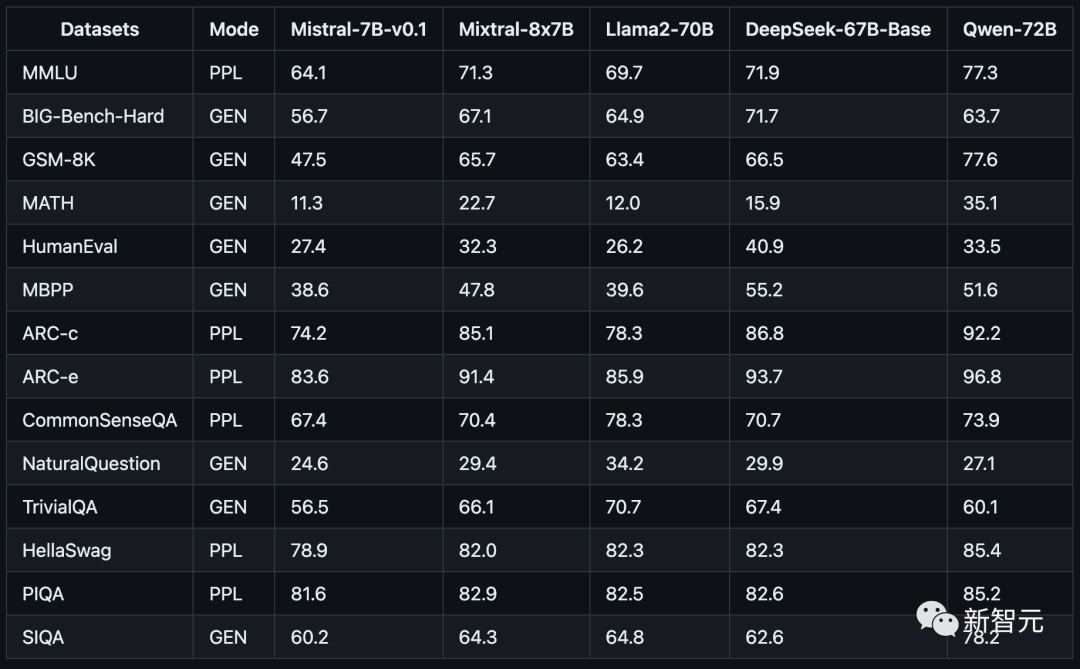
来源:OpenCompass
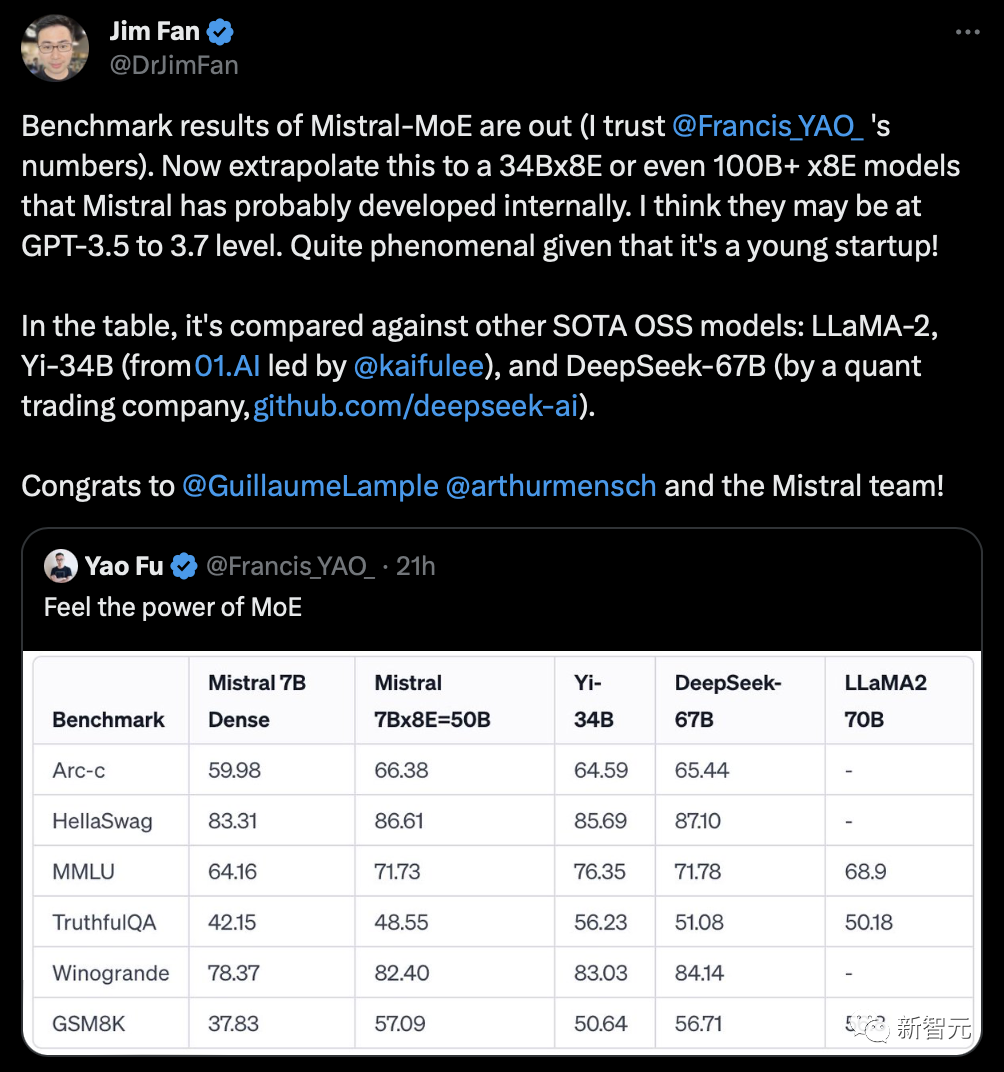
英伟达高级研究科学家Jim Fan推测,Mistral可能已经在开发34Bx8E,甚至100B+x8E的模型了。而它们的性能,或许已经达到了GPT-3.5/3.7的水平。
这里简单介绍一下,所谓专家混合模型(MoE),就是把复杂的任务分割成一系列更小、更容易处理的子任务,每个子任务由一个特定领域的「专家」负责。
1. 专家层:这些是专门训练的小型神经网络,每个网络都在其擅长的领域有着卓越的表现。
2. 门控网络:这是MoE架构中的决策核心。它负责判断哪个专家最适合处理某个特定的输入数据。门控网络会计算输入数据与每个专家的兼容性得分,然后依据这些得分决定每个专家在处理任务中的作用。
这些组件共同作用,确保适合的任务由合适的专家来处理。门控网络有效地将输入数据引导至最合适的专家,而专家们则专注于自己擅长的领域。这种合作性训练使得整体模型变得更加多功能和强大。

有人在评论区发出灵魂拷问:MoE是什么?
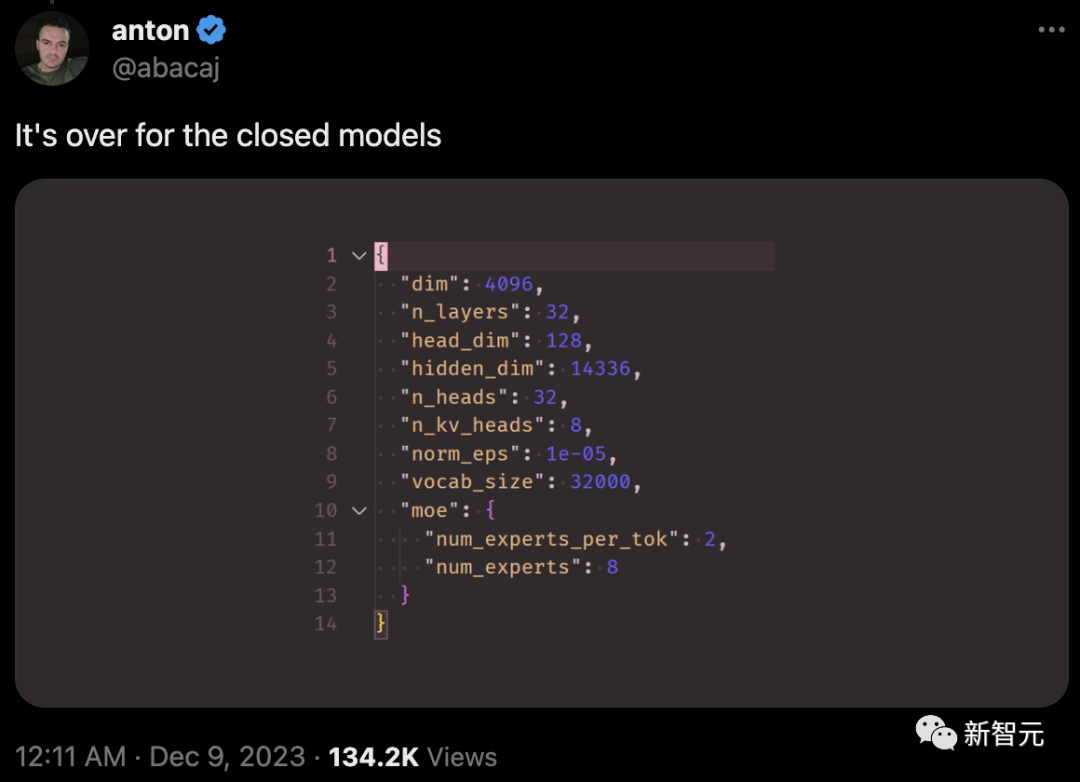
根据网友分析,Mistral 8x7B在每个token的推理过程中,只使用了2个专家。
以下是从模型元数据中提取的信息:
{"dim": 4096, "n_layers": 32, "head_dim": 128, "hidden_dim": 14336, "n_heads": 32, "n_kv_heads": 8, "norm_eps": 1e-05, "vocab_size": 32000, "moe": {"num_experts_per_tok": 2, "num_experts": 8}
与GPT-4(网传版)相比,Mistral 8x7B具有类似的架构,但在规模上有所缩减:
- 专家数量为8个,而不是16个(减少了一半)
- 每个专家拥有70亿参数,而不是1660亿(减少了约24倍)
- 总计420亿参数(估计值),而不是1.8万亿(减少了约42倍)
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

