

为什么说比特币生态必将
原文来源:蓝洞商业
作者 | 赵卫卫

图片来源:由无界 AI生成
ChatGPT 爆火一年,大模型的竞争走到哪一步了?
从微信指数的数据,可以管中窥豹到各家大模型的感知度,ChatGPT 遥遥领先,依然是国内大模型们追赶的对象。
而国内互联网大厂的大模型梯队中,百度的文心一言和阿里的通义千问,依赖于发布时间较早,是产品感知度比较高的存在,尤其是文心一言3 月率先发布、 8月全面开放,已经进化到 4.0 版本。
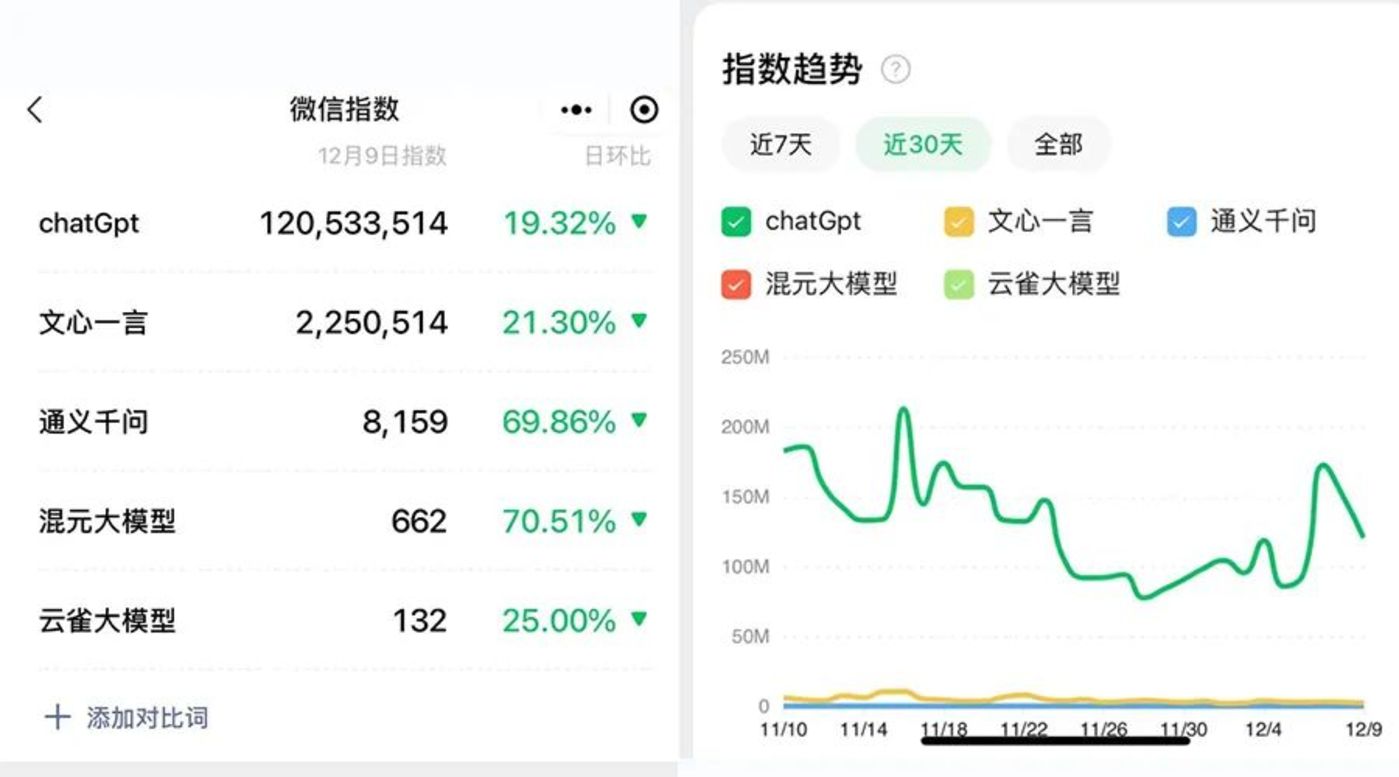
而老对手腾讯和字节,分别在今年 8 月和 9 月亮相了自家的大模型产品,在时间线上属于跟进 ChatGPT 较晚的梯队,姿态也都相对低调。
先看字节的大模型战略,是先在 8 月上线了 AI 聊天机器人「豆包」,随后自研的大模型产品云雀在 9 月浮出水面,而「豆包」正是云雀大模型在垂直场景中的应用产品。
最新的动作是,在海外上线 AI 产品「ChitChop」,应用场景比「豆包」的海外版本「 Cici 」更丰富,如此密集的产品布局,被外界认为是字节从「 APP 工厂」朝「 AI工厂」迈进。
再看腾讯的混元大模型,正式发布于 9 月,属于国内互联网大厂中最晚入场的玩家,也是至今没有单独发布独立大模型 APP 的互联网大厂。混元大模型最直接的使用场景还是在微信小程序内,发布后最大的变化是, 10 月底开放了文生图功能。
不做独立 APP ,而是利用微信丰沛的流量做大模型小程序,优先迭代基础能力,是腾讯混元大模型的现状;而同样流量丰沛的字节,则选择布局多款 AI 大模型垂直产品,在国内外市场同时押注。
至此,字节和腾讯这对老冤家,正在大模型的赛道背道而驰。
OpenAI上线一年,其自身团队的变动成了大模型混乱期的转折点;而当国内「百模大战」告一段落,谁能在混乱期中突出重围?
腾讯,依然「不着急」?
关于大模型能力的测试有很多,各家大模型的产品能力也各有千秋。
腾讯方面曾宣称,在信通院测评主流大模型测试中,混元的模型开发和模型能力均获得了当前的最高分数。
相较之下,第三方个人测评更直观,在科技公司研究员Yuri自发研究的测评中,腾讯混元大模型在国产大模型的同题测试中排名靠后。
Yuri通过一套考公的行政职业能力笔试测验题,对百度文心一言、字节豆包、阿里通义千问和腾讯混元大模型进行了测试,一共 99 道题目。结果显示,混元大模型在常识判断、言语理解与表达和推理判断等方面都差强人意,总体上的正确率为 34.3%,排在 12 个国产大模型末尾。
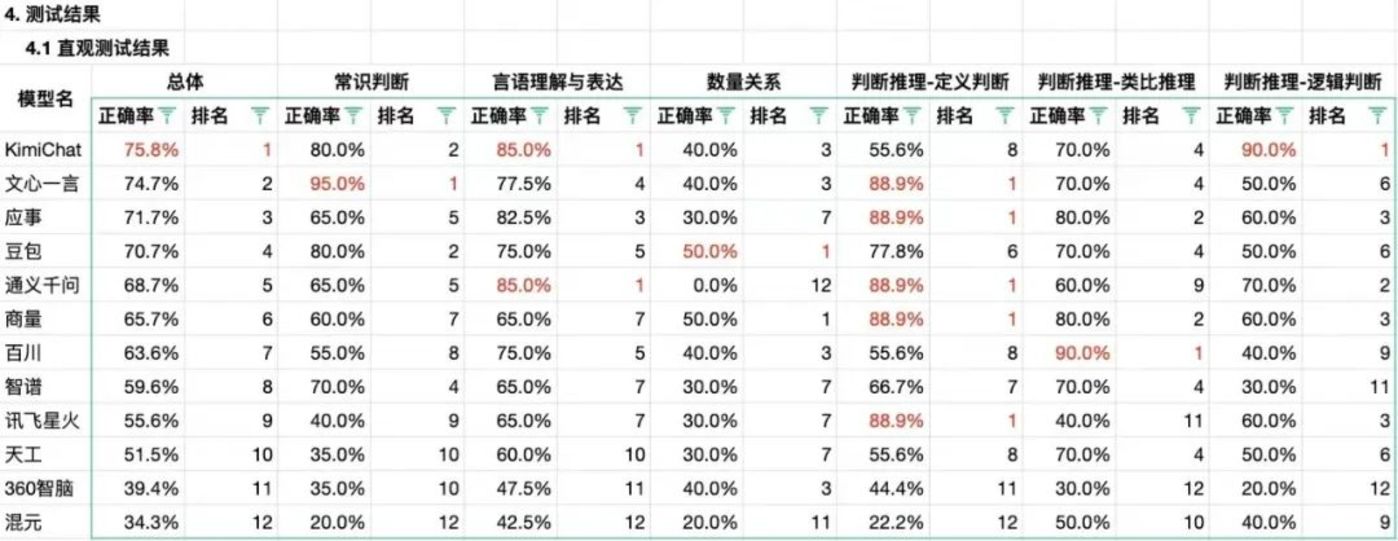
「混元是此次测试让我大跌眼镜的模型,没有之一。」Yuri在测试后点评说,「前十道题连错是我完全没想到的,我大概半年前就一直在期待宇宙厂和鹅厂的模型,觉得他们或许会带来惊喜感,宇宙厂达到了预期,但没想到鹅厂的模型居然是酱紫。」
Yuri也在测试中说明,「本测试结果没有任何地缘和公司立场,单从一个用户体验角度评论,仅表示模型在所测试题目及同类题目的任务表现,并不能完全代表模型在其他任务上的能力和表现。」
这次测试的时间为 11 月中旬,而 GPT-4 的测试结果为正确率 73.7%,Yuri最后总结,「Open AI 在灯塔尖,我们在长城内,大家都有光明的前途呐」。
他同时提到,混元的回答生成速度跟通义千问差不多,但测试中共用了 7 轮对话完成这次测试,单次对话的上限是 30 次,多了之后就会出现「会话过长,请开始新会话」的提示。
第三方个人测试一定程度上反映出了混元大模型的问题。此前就有腾讯内部人士称,混元大模型在公司内部受到了批评。相关测试者透露,「不好用」是腾讯内部一部分人的共识。
「不着急」是今年9月份,腾讯混元大模型对自己的定调。虽然后续一直在更新迭代,但版本更迭速度相比国内同行的确稍慢。
截至 12 月 7 日,混元大模型对外使用的版本为V1.5.5,距离混元大模型正式发布已经过去了整整三个月,而百度文心一言已经在 10 月份开启了4.0 收费版本,同期阿里通义千问也进化到了 2.0 版本。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

