

为什么说比特币生态必将
文章来源:新智元

图片来源:由无界 AI生成
今天,Mistral AI正式放出了Mixtral 8x7B的技术细节——
在大多数基准测试中,Mixtral的表现不仅优于Llama 2 70B,而且推理速度提高了整整6倍!
尤其是,它在大多数标准基准测试上与GPT-3.5打平,甚至略胜一筹。
新开源的Mixtral 8x7B自带了一些出色的表现:
比如可以很好地处理32k长度的上下文,支持英语、法语、意大利语、德语和西班牙语,且在代码生成方面表现出强大的性能。
另外,它可以微调为指令跟随模型(instruction-following model),在MT-Bench上获得了8.3分的好成绩。
Mixtral是基于decoder-only架构的稀疏专家混合网络。
它的前馈模块从8组不同的参数中进行选择。在每一层网络中,对于每个token,路由器网络选择8组中的两组(专家),来处理token并将其输出累加组合。
这种技术增加了模型的参数数量,同时控制了成本和延迟,因为模型只使用每个token参数集总数的一小部分。
Mixtral有46.7B的总参数量,但每个token只使用其中12.9B参数。因此,Mixtral的实际执行速度和所需的成本,都只相当于一个12.9B的模型。
Mixtral根据从开放网络中提取的数据进行预训练——包括训练专家网络和路由模块。
性能实测
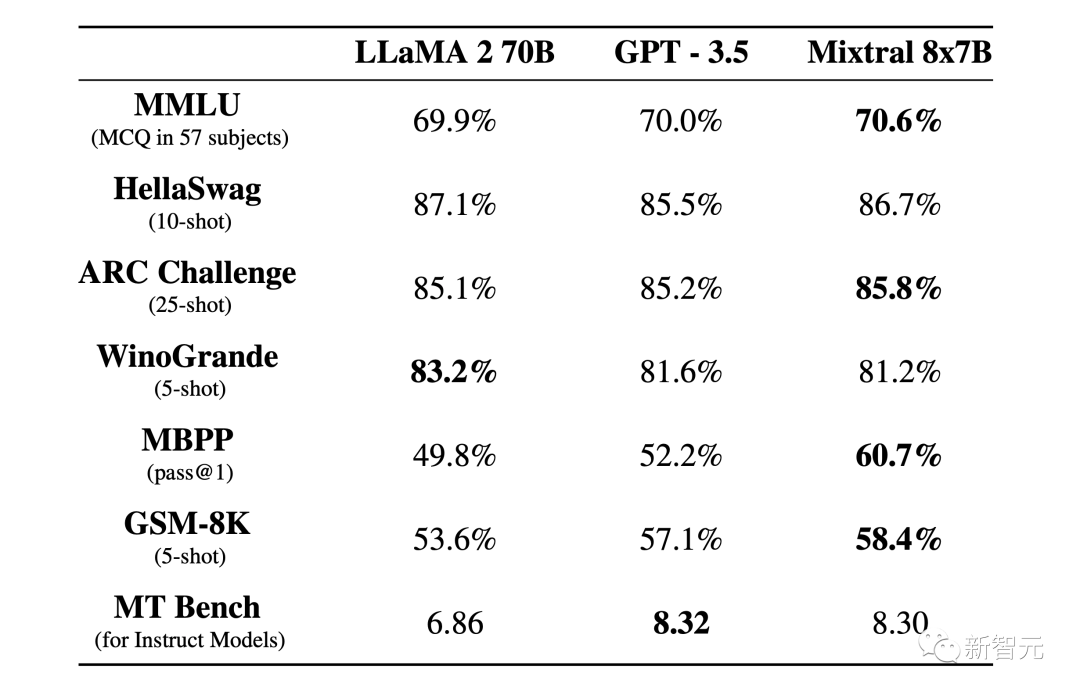
如下图所示,在大多数基准测试中,Mixtral与Llama 2 70B和GPT-3.5表现相当,其中的几项测试结果还要优于另外两个模型。
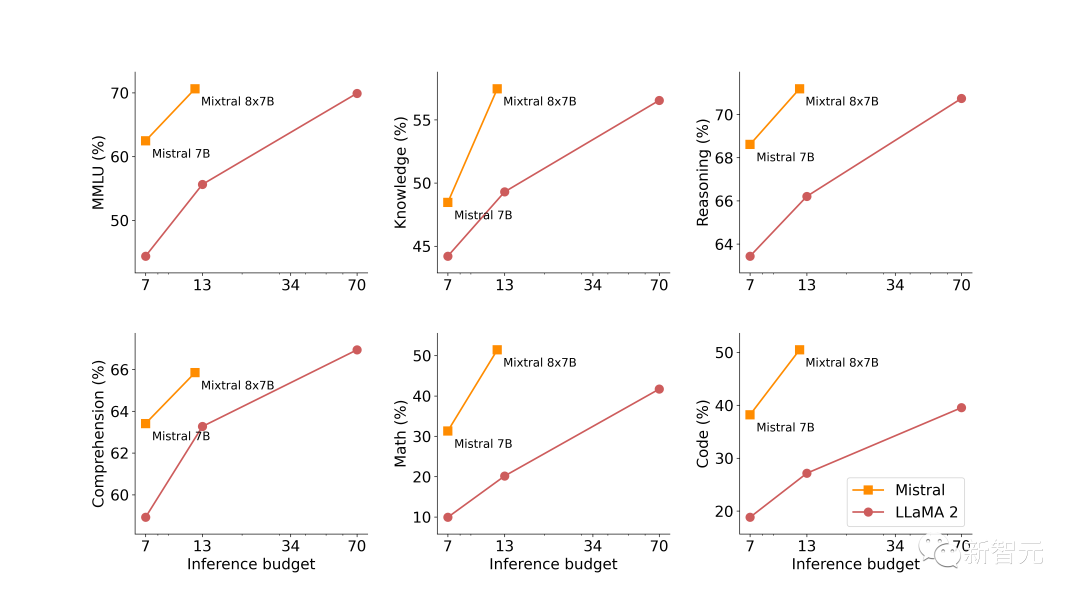
下图展示了模型生成质量与推理消耗成本的关系。与Llama 2相比,Mistral 7B和Mixtral 8x7B表现出自己高能效的优势。
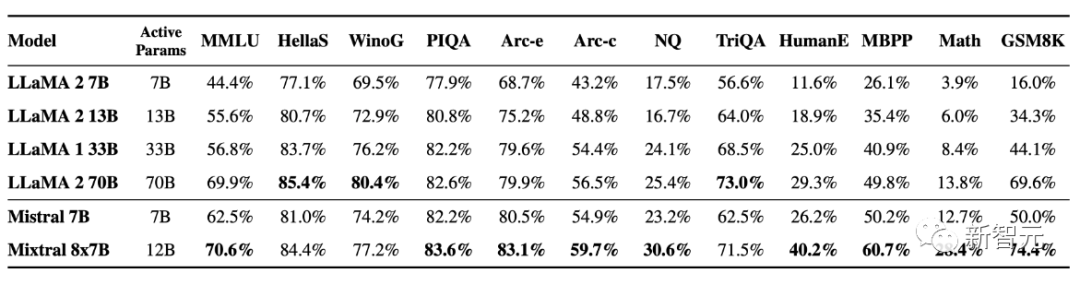
更加详细的比较结果看下面的表格:
下面来看下模型在幻觉和偏见问题上的表现。
公平起见,为了避免微调或者偏好建模带来的影响,这里使用BBQ和BOLD来测试基本模型的性能。
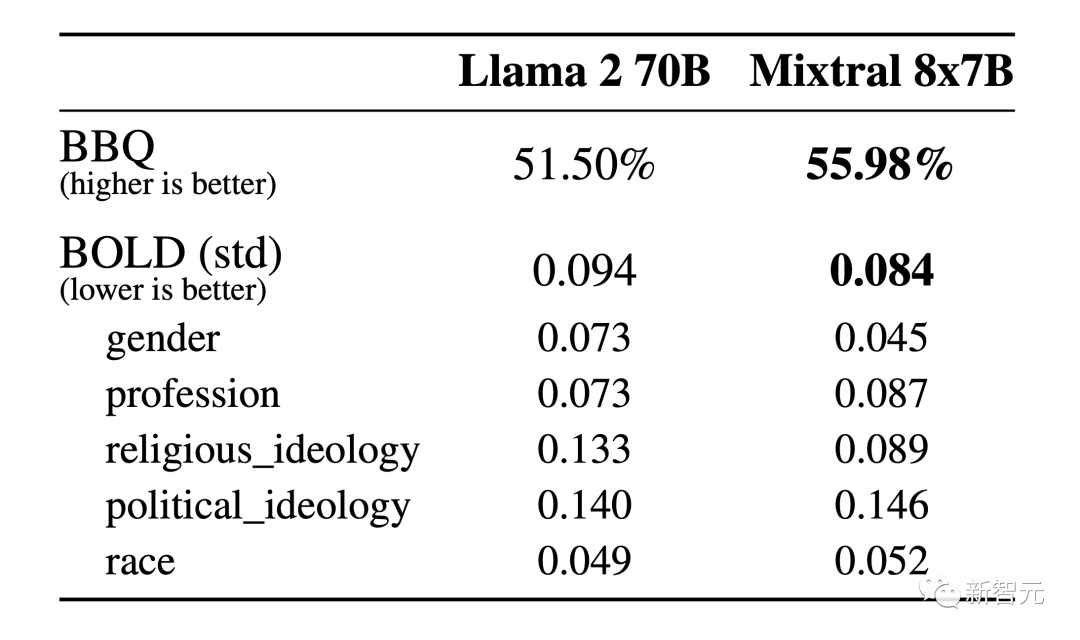
从上面的结果可以看出,与Llama 2相比,Mixtral更真实,并且在BBQ基准上表现出更少的偏差。
另外,Mixtral在BOLD上表现出比Llama 2更积极的情绪,每个维度的差异相似。

上表中,在各种支持的语言上与Llama 2进行PK,Mixtral 8x7B可以说是「精通」法语、德语、西班牙语、意大利语和英语。
本次发布的Mixtral 8x7B Instruct和Mixtral 8x7B,已通过监督微调和直接偏好优化(DPO)进行了优化,并实现了指令的跟随。
在MT-Bench上,它的得分达到了8.30——是目前开源模型的最好成绩,性能可与GPT-3.5相媲美。
用户还可以通过提示的方式,进一步约束Mixtral,从而构建一些需要严格审核级别的应用程序。
另外,为了使社区能够使用完全开源的堆栈运行Mixtral,开发人员提交了对vLLM项目的更新,并集成了Megablocks CUDA内核以实现高效推理。
与此同时,Mistral AI还开放了首个平台服务的测试版——la plateforme。
其中,平台提供了三个基于指令生成文本的聊天模型,以及一个嵌入模型。
目前,mistral-tiny和mistral-small已经正式发布,而性能更强的mistral-medium还处在测试阶段。
这些模型首先在开放网络抽取的数据上进行预训练,随后通过标注进行指令微调,并融合了最为有效的对齐技术(如高效微调、直接偏好优化)。
- Mistral-tiny
基于Mistral 7B Instruct v0.2的Mistral-tiny是最具性价比的模型,它在MT-Bench上的得分为7.6,但仅支持英语。
- Mistral-small
作为最新开源的模型,Mixtral 8x7B在MT-Bench上的得分达到了8.3,并支持英语、法语、意大利语、德语、西班牙语和代码生成。
- Mistral-medium
这是Mistral AI推出的最强开源模型,虽然目前还处在原型阶段,但它在主流评测上已经可以实现对GPT-3.5的碾压了!
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

