

星球日报 | 美联储维持利
在2023年的最后一个月,谷歌在社交平台上“低调”的官宣了新一代大模型Gemini。不过Gemini一经上线便吸引下了行业内外人士的广泛关注,很多观点都表达出Gemini将成为GPT-4最强劲的对手,甚至碾压GPT-4的存在……
原文来源:大模型之家
作者:王昊达

图片来源:由无界 AI生成
根据官方介绍Gemini已经实现各项参数超越GPT-4,特别是多模态领域包括图像、视频音频等领域都有着突出的领先优势。并且Gemini是第一个在MMLU(大规模多任务语言理解)方面优于人类专家的模型,而MMLU也是测试AI模型知识和解决问题能力的最流行方法之一。
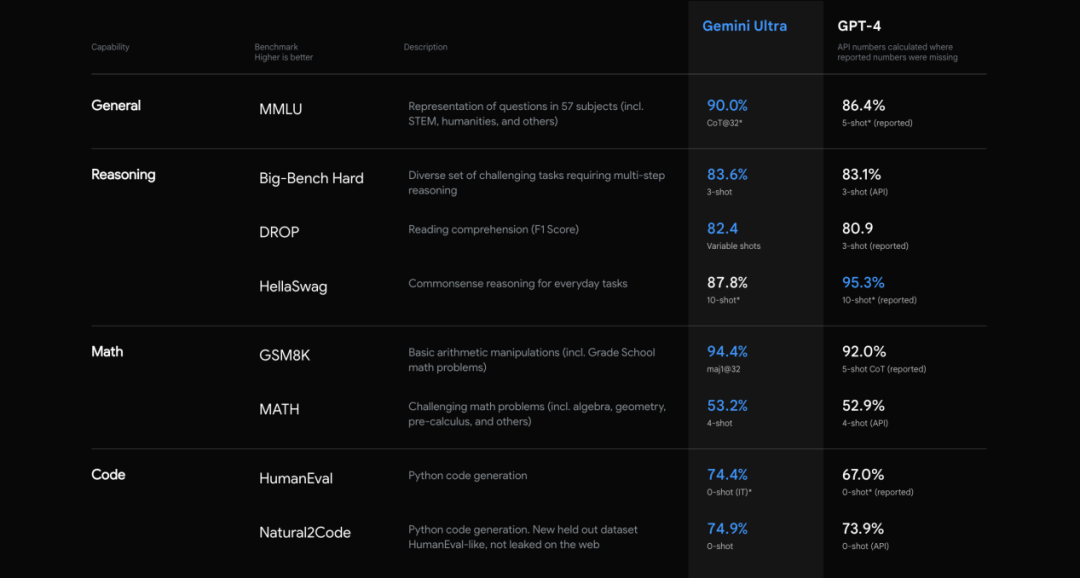
从数据上来看,Gemini在自然语言处理、智能对话系统、信息检索等领域,可以使其更好地适应和解决复杂的语境和任务。强大语言处理能力还可以为人们提供更高效、精准的信息和服务。
今天,谷歌官方表示Google AI Studio和Google Cloud Vertex AI将把Gemini模型集成到应用程序中。同时,用户可以在Bard中体验集成了Gemini Pro的测试版本大模型。值得一提的是,在Gemini AI官方介绍Gemini是Google即将推出的AI模型,由DeepMind和Google Brain联合AI团队的专家创建。同时Gemini AI也郑重声明“Gemini AI”的名称是 Google 的财产,且不隶属于 Google AI。
视觉新体验,多模态功能成新发力点
在众多功能展示中,Gemini最受业内外人士以及媒体关注的便是其多模态能力带来的体验,在官方介绍视频中,Gemini可以对正在变化的视频进行分析和理解,并且形成相应的描述。同时,在给出相应文字介绍时,Gemini还通过音频的形似对文字内容进行复述,在复述的过程中还包含了一些拟人形态的气口、停顿以及趣味性的对话,使得模型与使用者的交流更加顺畅自然。

在大模型之家的体验中,大模型之家使用对集成了Gemini Pro的大模型Bard给出了部分《清明上河图》的图片作为指令,让Bard进行识别。Bard也清晰的给出了对于图片的识别和描述。

除了介绍了《清明上河图》的内容,集成了Gemini Pro的大模型Bard还总结了《清明上河图》的主题。它表示:画中描绘了北宋汴京城的繁华景象,展现了北宋时期的经济繁荣和社会稳定。
Gemini能够同时处理多种类型的数据,包括文本、图像和视频,从而实现更丰富和全面的信息理解和表达。这种能力的实现,依赖于Gemini的底层架构可以将不同的数据源转换为相同的向量表示,然后再根据不同的任务生成相应的输出。这种架构的优势在于,它可以利用不同数据源之间的关联性和互补性,提高模型的泛化能力和创造力。
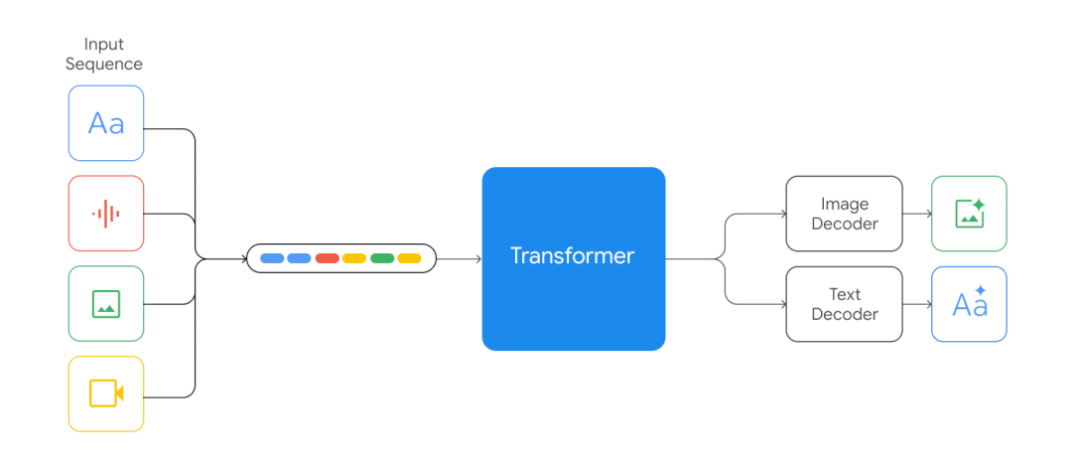
在图像识别和描述能力上,Gemini通过多模态架构与应用相结合,使用了一些先进的计算机视觉和自然语言处理的技术,如目标检测、场景分割、图像字幕、文本摘要等,来实现图像到文本的转换,并且在文本中包含一些图像的重要信息和细节。这种结合的优势在于,它可以提高模型的准确性和完整性,展示模型的分析和理解能力。
多尺寸部署,为商业化打好前站
在首批公开的信息中,Gemini同时提出了三种不同尺寸的大模型,由大到小分别为Gemini Ultra、Gemini Pro以及Gemini Nano。

其中,Gemini Ultra是Gemini系列中最大、最强的模型,拥有超过1000亿的参数,可以处理高度复杂的任务,例如高级推理、规划、理解等。而通过MMLU的测试的也正是Gemini的Ultra版本。
据大模型之家了解,谷歌采用了自研TPU为Gemini的提供模型训练,根据Gemini模型的大小和配置,谷歌为其配置了大型的TPUv4加速器群,用于进行机器学习和深度学习任务。TPU的设计旨在提供高效的张量计算,使其在训练和推理深度学习模型方面能够取得卓越的性能。

免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

