

星球日报 | 美联储维持利
原文来源:机器之心

图片来源:由无界 AI生成
大语言模型(LLM)被越来越多应用于各种领域。然而,它们的文本生成过程既昂贵又缓慢。这种低效率归因于自回归解码的运算规则:每个词(token)的生成都需要进行一次前向传播,需要访问数十亿至数千亿参数的 LLM。这导致传统自回归解码的速度较慢。
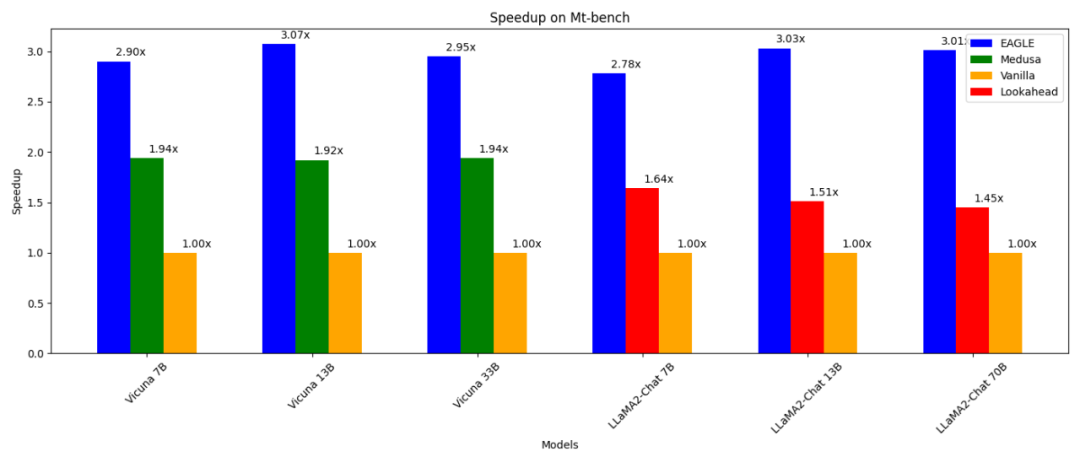
近日,滑铁卢大学、加拿大向量研究院、北京大学等机构联合发布 EAGLE,旨在提升大语言模型的推理速度,同时保证模型输出文本的分布一致。这种方法外推 LLM 的第二顶层特征向量,能够显著提升生成效率。

EAGLE 具有以下特点:
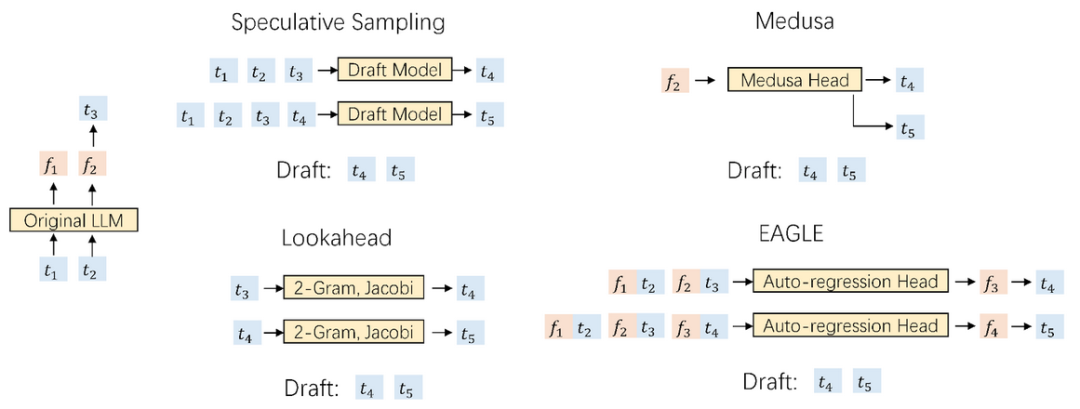
加速自回归解码的一种方法是投机采样(speculative sampling)。这种技术使用一个更小的草稿模型,通过标准自回归生成来猜测接下来的多个词。随后,原始 LLM 并行验证这些猜测的词(只需要进行一次前向传播进行验证)。如果草稿模型准确预测了 α 词,原始 LLM 的一次前向传播就可以生成 α+1 个词。
在投机采样中,草稿模型的任务是基于当前词序列预测下一个词。使用一个参数数量显著更少的模型完成这个任务极具挑战性,通常会产生次优结果。此外,标准投机采样方法中的草稿模型独立预测下一个词而不利用原始 LLM 提取的丰富语义信息,导致潜在的效率低下。
这个局限启发了 EAGLE 的开发。EAGLE 利用原始 LLM 提取的上下文特征(即模型第二顶层输出的特征向量)。EAGLE 建立在以下第一性原理之上:
特征向量序列是可压缩的,所以根据前面的特征向量预测后续特征向量比较容易。
EAGLE 训练了一个轻量级插件,称为自回归头(Auto-regression Head),与词嵌入层一起,基于当前特征序列从原始模型的第二顶层预测下一个特征。然后使用原始 LLM 的冻结分类头来预测下一个词。特征比词序列包含更多信息,使得回归特征的任务比预测词的任务简单得多。总之,EAGLE 在特征层面上进行外推,使用一个小型自回归头,然后利用冻结的分类头生成预测的词序列。与投机采样、Medusa 和 Lookahead 等类似的工作一致,EAGLE 关注的是每次提示推理的延迟,而不是整体系统吞吐量。
EAGLE——一种增强大语言模型生成效率的方法
上图显示了 EAGLE 与标准投机采样、Medusa 以及 Lookahead 关于输入输出的区别。下图展示了 EAGLE 的工作流程。在原始 LLM 的前向过程中,EAGLE 从第二顶层收集特征。自回归头以这些特征以及此前生成的词的词嵌入作为输入,开始猜下一个词。随后,使用冻结的分类头(LM Head)确定下一个词的分布,使 EAGLE 能够从这个分布中进行采样。通过多次重复采样,EAGLE 进行了类似树状的生成过程,如下图右侧所示。在这个例子中,EAGLE 的三次前向传播 “猜” 出了 10 个词组成的树。
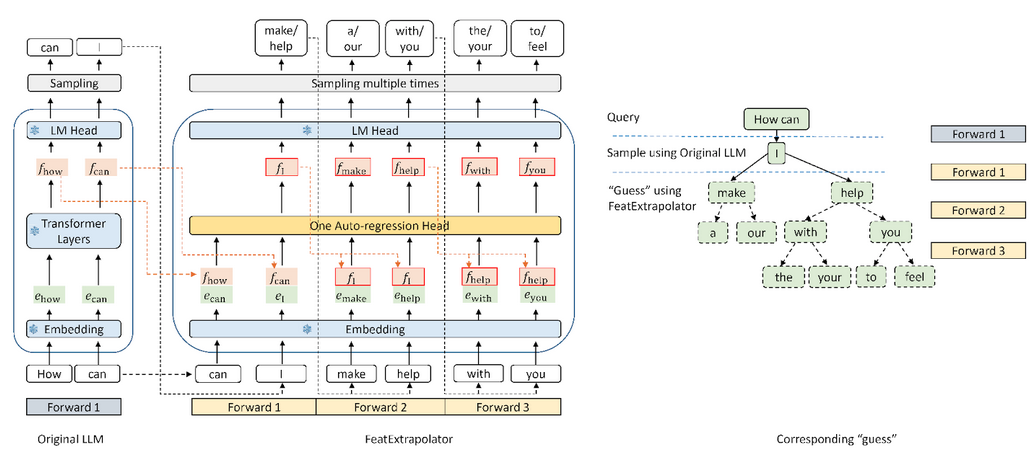
EAGLE 使用轻量级的自回归头来预测原始 LLM 的特征。为了确保生成文本分布的一致性,EAGLE 随后验证预测的树状结构。这个验证过程可以使用一次前向传播完成。通过这个预测和验证的循环,EAGLE 能够快速生成文本词。
训练自回归头代价很小。EAGLE 使用 ShareGPT 数据集进行训练,该数据集包含不到 70,000 轮对话。自回归头的可训练参数数量也很少。如上图中的蓝色部分所示,大多数组件都是冻结的。唯一要额外训练的是自回归头,这是一个单层 Transformer 结构,具有 0.24B-0.99B 参数。即使是 GPU 资源不足的情况下,也可以训练自回归头。例如,Vicuna 33B 的自回归头可以在 8 卡 RTX 3090 服务器上在 24 小时内完成训练。
为什么使用词嵌入来预测特征?
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

