

Spartan:2024年加密行业的九
12 月 19 日,OpenAI 在官网公布了“准备框架”测试版,旨在监控和管理日益强大的人工智能模型的潜在危险。

图片来源:由无界 AI生成
近期,OpenAI 因内斗事件饱受争议,也引发了人们对其治理和问责制的质疑。与此同时,在确保人工智能模型安全性方面,OpenAI 的应对措施也越来越受到人们的关注。
10 月底,OpenAI 宣布成立一个“准备团队”(Preparedness team),旨在监测和评估前沿模型的技术和风险,并制定和维护风险知情发展政策(RDP)。
在这一基础上,OpenAI 今日又公布了一份名为“准备框架”(Preparedness Framework)的文档,概述了 OpenAI 将如何“追踪、评估、预测和防范灾难性风险”,旨在确保前沿人工智能模型的安全,并尝试解决一些问题。
OpenAI“准备框架”的核心机制之一是,对所有前沿人工智能模型使用风险“记分卡”。它可以评估和跟踪潜在风险的各种指标,例如模型的功能、漏洞和影响。
据介绍,记分卡会对所有模型进行反复评估和定期更新,并在达到特定风险阈值时触发审查和干预措施。
对于触发基准安全措施的风险阈值,OpenAI 将感知风险评级分为四个等级:“低”、“中”、“高”和“严重”,并列举了 4 类可能带来灾难性后果的风险领域:网络安全、CBRN(化学、生物、辐射、核威胁)、劝说以及模型的自主性。
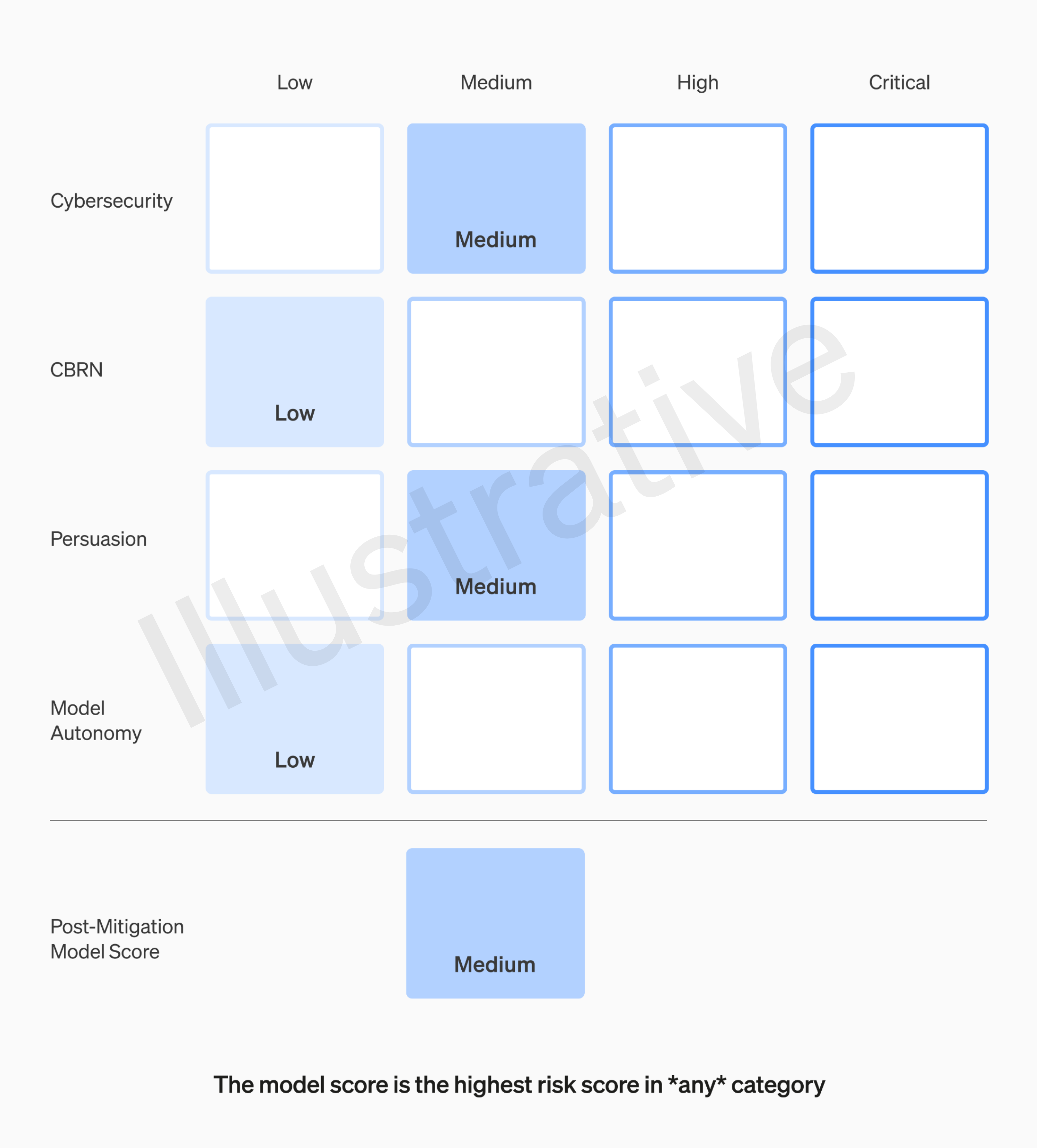
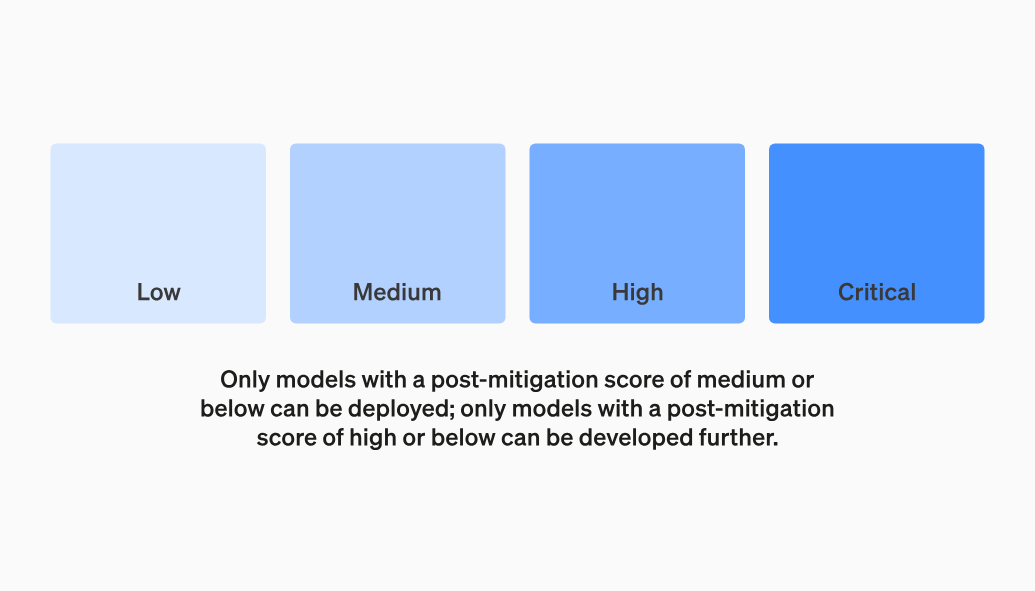
OpenAI 强调,只有在缓解后得分在“中”或以下的模型才能部署,只有缓解后得分在“高”或以下的模型才能进一步开发,并且将针对具有高风险或严重风险(缓解前)风险的模型实施额外的安全措施。
此外,OpenAI 还将成立一个跨职能的“安全咨询小组”(Safety Advisory Group)来监督技术工作,并建立一个安全决策的运作架构。
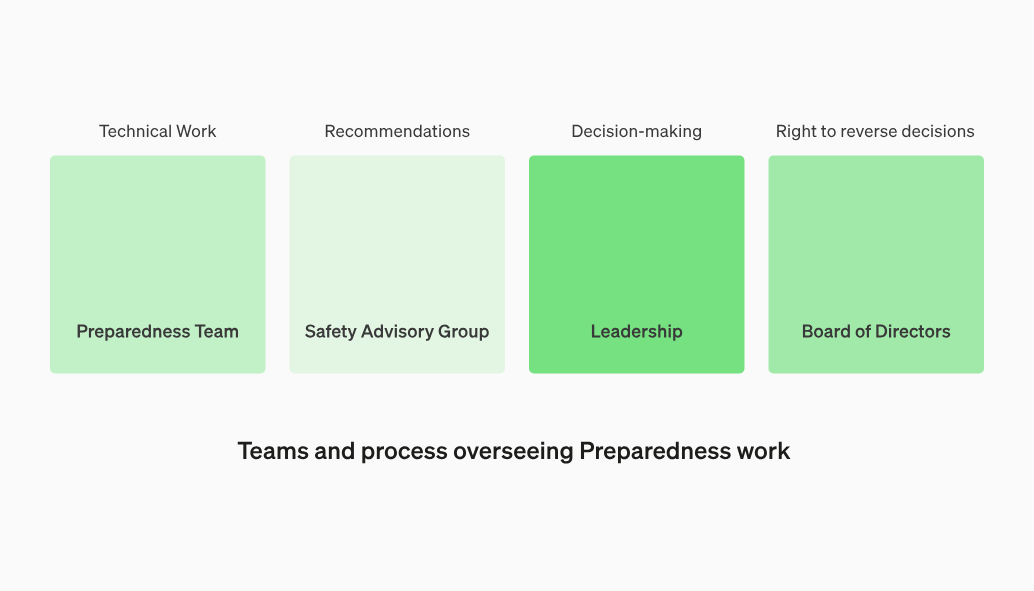
首先,准备团队将推动技术工作,检查和评估前沿模型,并定期向内部安全咨询小组发送报告。随后,安全咨询小组会审查所有报告,再将报告同时提交领导层和董事会。
值得注意的是,OpenAI 指出,虽然领导层是决策者,但董事会拥有撤销决定的权利。
除了上述措施,准备框架还有一个关键要素,就是允许来自 OpenAI 之外的“合格的独立第三方”测试其技术并接收反馈,同时 OpenAI 将与外部各方以及安全系统等内部团队密切合作,以追踪现实世界中的滥用情况。这一举措有助于 AI 模型的安全性得到更广泛的审查和验证。
目前,该安全框架仍处于测试阶段。OpenAI 也表示,准备框架并不是一个静态文档,而是一个动态且不断发展的文档,他们将根据新数据、反馈和研究不断完善和更新框架,并将与人工智能社区分享其研究成果和最佳实践。
那么对于这一框架,行业人士如何看待?
在 OpenAI 宣布这一消息之前,其主要竞争对手 Anthropic 已经发布了几份关于人工智能安全的重要声明。
Anthropic 由前 OpenAI 研究人员创立,也是领先的人工智能实验室。它于今年 9 月发布了“负责任的扩展政策”(Responsible Scaling Policy),旨在采用一系列技术和组织协议,以帮助管理功能日益增强的 AI 系统的风险。
在文件中,Anthropic 定义了一个名为 AI 安全级别(ASL)的框架,用于解决灾难性风险。该框架大致仿照美国政府处理危险生物材料的生物安全分级(BSL)标准。该框架的基本想法是,要求与模型潜在的灾难性风险相适应的安全、保障和操作标准,更高的 ASL 安全级别需要更严格的安全演示。
根据 ASL 框架,分为以下四个等级:
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

