

美元/日元小幅上涨,日本
原文来源:量子位

图片来源:由无界 AI生成
原本需要一张16万元的80G A100干的活,现在只需要一张不到2万元的24G 4090就够了!
上海交大IPADS实验室推出的开源推理框架PowerInfer,让大模型推理速度加快了11倍。
而且不用量化,就用FP16精度,也能让40B模型在个人电脑上运行;如果加入量化,2080 Ti也能流畅运行70B模型。

结合大模型的独特特征,通过CPU与GPU间的混合计算,PowerInfer能够在显存有限的个人电脑上实现快速推理。
相比于llama.cpp,PowerInfer实现了高达11倍的加速,让40B模型也能在个人电脑上一秒能输出十个token。
我们最熟悉的ChatGPT,一方面有时会因为访问量过大而宕机,另一方面也存在数据安全问题。

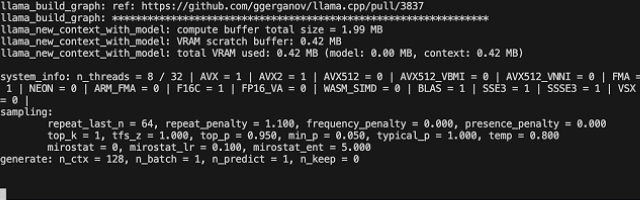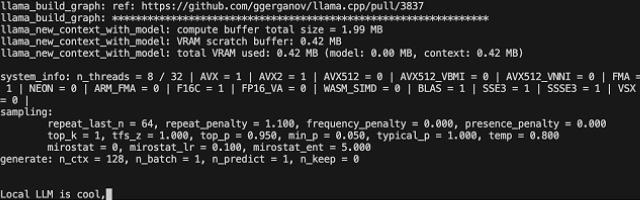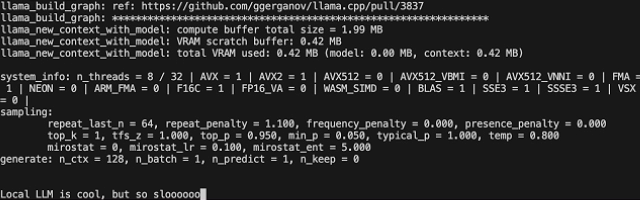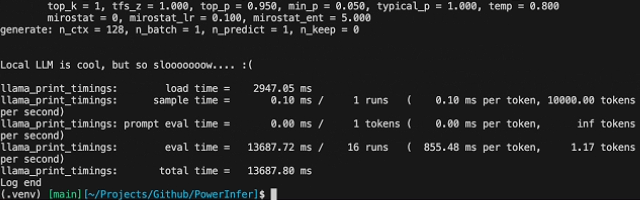
开源模型能较好地解决这两个问题,但如果没有高性能的显卡,运行速度往往十分感人:
而PowerInfer的出现,刚好解决了这个痛点。

PowerInfer一经发布就引起热烈反响,不到24小时就获得了500+星标,其中还有一颗来自llama.cpp的作者Gerganov。
目前,PowerInfer的源码和论文均已公开,下面就一起看看它的加速效果究竟有多强。
推理速度最高11倍
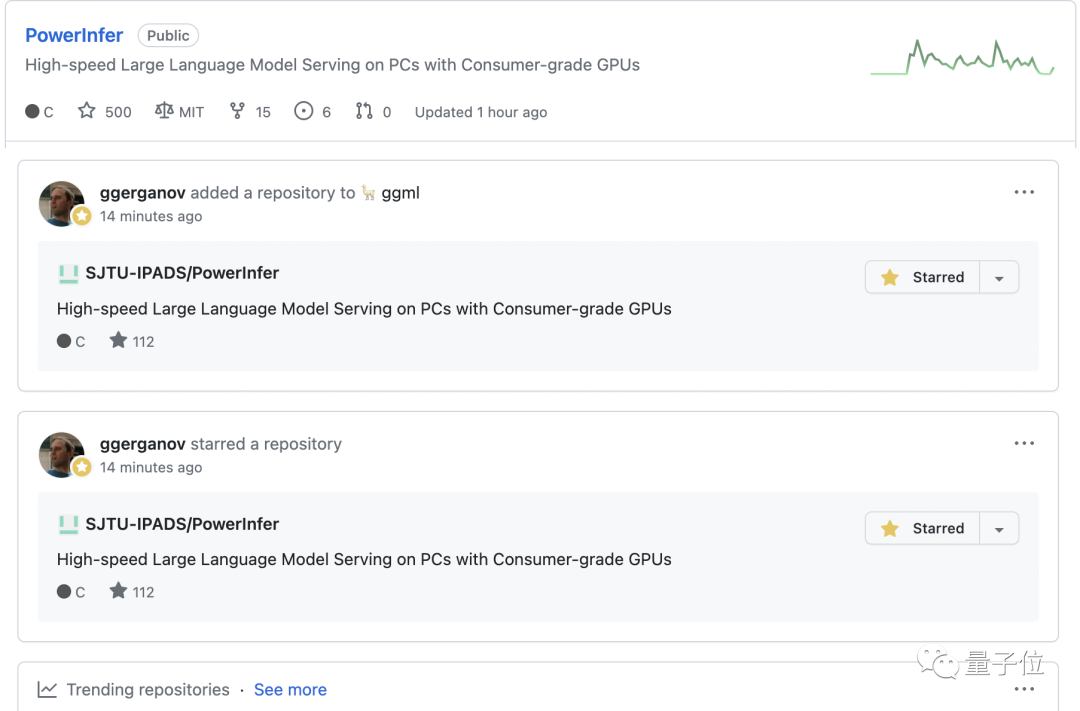
在搭载x86 CPU和NVIDIA GPU的消费级硬件平台上,PowerInfer以参数量从7B到175B的一系列LLM模型为基准,对PowerInfer的端到端推理速度进行了测试,并和同平台上性能最好的推理框架llama.cpp进行了对比。
对于FP16精度的模型,在搭载了13代Intel Core i9和单张RTX 4090的高端PC(PC-High)上,PowerInfer平均实现了7.23倍的速度提升,其中在Falcon 40B上实现了高达11.69倍的速度提升。
在所有测试用例上,PowerInfer平均达到了8.32 tokens/s,在OPT 30B和Falcon 40B上最高分别达到16.06 tokens/s和12.94 tokens/s。
借助PowerInfer,当今的消费级平台可以流畅运行30-40B级别的LLM,并以可以接受的速度运行70B级别的LLM。
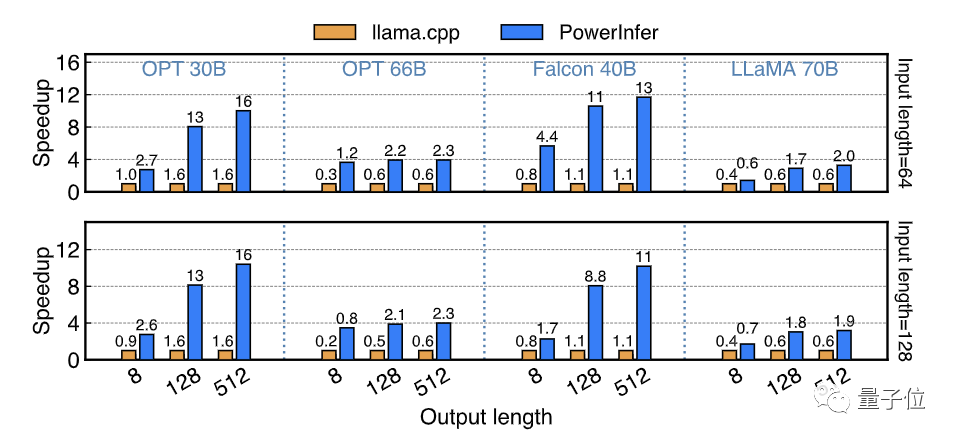
模型量化是端侧LLM推理非常常用的技术,PowerInfer也支持了INT4量化模型的推理。
PowerInfer分别在高端PC(PC-High)和搭载单张RTX 2080Ti的中低端PC(PC-Low)上测试了一系列INT4量化模型的推理速度。
在PC-High上,PowerInfer能够高速运行40-70B规模的模型,最高达到了29.09 tokens/s的推理速度,并且实现了平均2.89倍,最高4.28倍的速度提升。
同时,在消费级硬件上运行OPT-175B这种规模的模型也成为可能。
在PC-Low这种中低端PC上,PowerInfer可以流畅运行30-70B规模的模型,并实现平均5.01倍,最高8.00倍的速度提升,这主要得益于INT4量化后模型大部分热神经元得以放置在显存中。
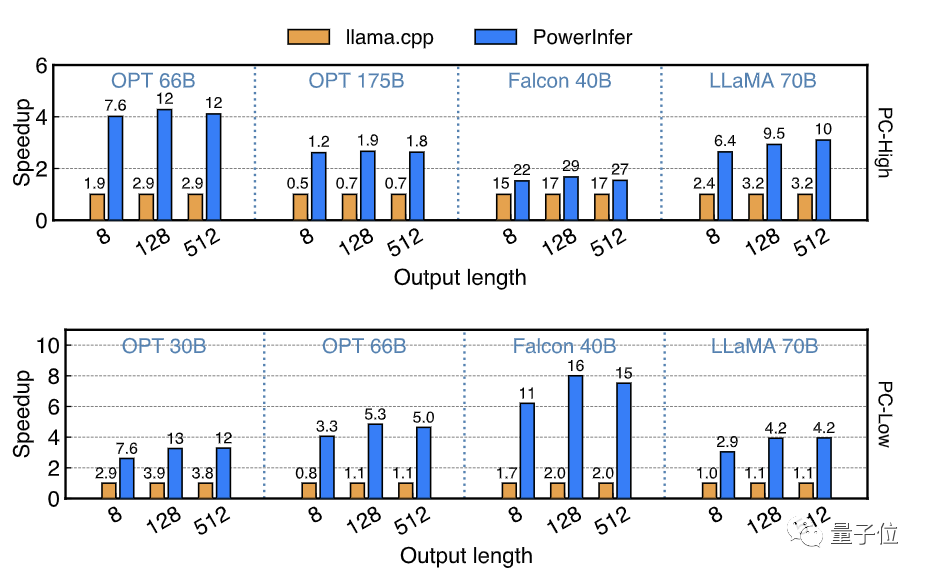
最后,PowerInfer对比了PC-High上运行PowerInfer相比于云端顶级计算卡A100运行SOTA框架vLLM的端到端推理速度,测试模型为FP16精度的OPT-30B和Falcon-40B(ReLU)。
当输入长度为64时,PowerInfer对A100的速度差距从93%-94%缩小到了28%-29%;在输入长度为1的纯生成场景中,这一差距会被进一步缩小到低至18%。
这代表着PowerInfer借助稀疏激活和CPU/GPU混合推理,极大地弥合了消费级显卡到顶尖服务端计算卡的推理速度差距。

那么,PowerInfer是如何实现消费级硬件上的高速推理的呢?
充分利用模型和硬件特点
PowerInfer实现高速推理的秘诀,在于充分利用了稠密模型存在的高局部性的稀疏激活,并与CPU和GPU的运算特点进行了充分结合。
何谓“稀疏激活”?
最近Mixtral MoE大模型引爆了整个AI圈,稀疏模型重新进入大家的视野。
一个有趣的事实是:像OPT、LLaMA(ReLU)这样被视为稠密模型的LLM,同样存在稀疏激活的特征。
什么是稠密模型的稀疏激活呢?
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

