

Arweave网络20 亿交易量里程
原文来源:量子位

图片来源:由无界 AI生成
谷歌扳回一局!
在Gemini开放API不到一周的时间,港中文等机构就完成评测,联合发布了多达128页的报告,结果显示:
在37个视觉理解任务上,Gemini-Pro表现出了和GPT-4V相当的能力。
在多模态专有基准MME上,Gemini-Pro的感知和认知综合表现则直接获得了1933.4的高分,超越GPT-4V(1926.6)。

此前,CMU测评发现Gemini-Pro的综合能力居然和GPT-3.5差不多。
现在,在多模态这个一大主推的卖点上,Gemini-Pro可算是扳回一局。
那么具体如何?
测评报告一共128页,咱们就挑重点来看。

Gemini-Pro的首份多模态能力报告来了
这份测评主要是对Gemini-Pro的视觉理解能力进行评估。
一共涵盖基础感知、高级认知、挑战性视觉任务和各种专家能力四大领域,在37个细分任务项上进行定性比较。
定量评估则在专为多模态大语言模型专门设计的评测基准MME上展开。
首先来看定量测试结果。
MME上综合表现比GPT-4V强
MME基准包含两大类任务。
一个是感知,涵盖目标存在性判断、物体计数、位置关系、颜色判断、OCR识别、海报识别、名人识别、场景识别、地标识别和艺术品识别等。
一个是认知,涵盖常识推理、数值计算、文本翻译和代码推理等。
结果如下:
可以看到Gemini-Pro和GPT-4V可谓“各有所长”。
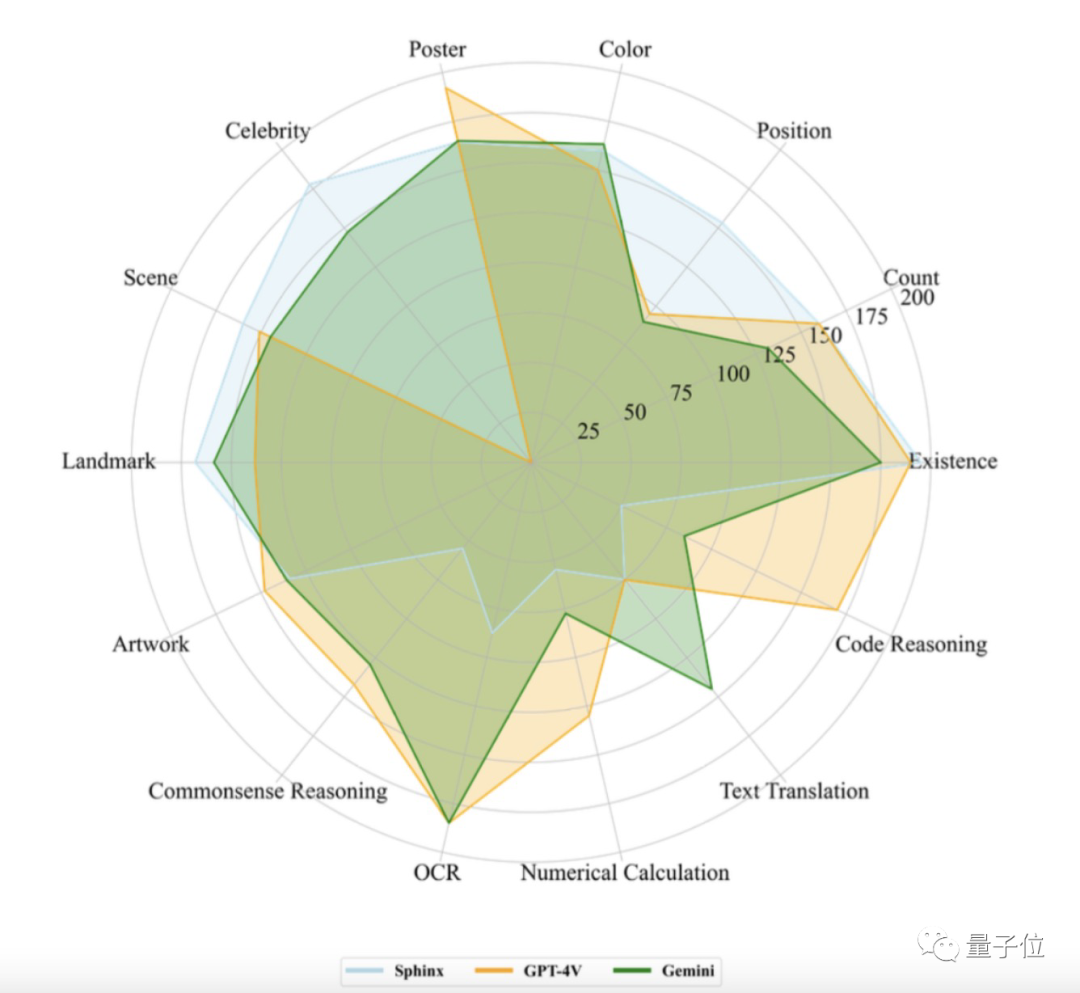
而计分显示,Gemini-Pro的总分为1933.4,比GPT-4V(1926.6)要高那么一点点。
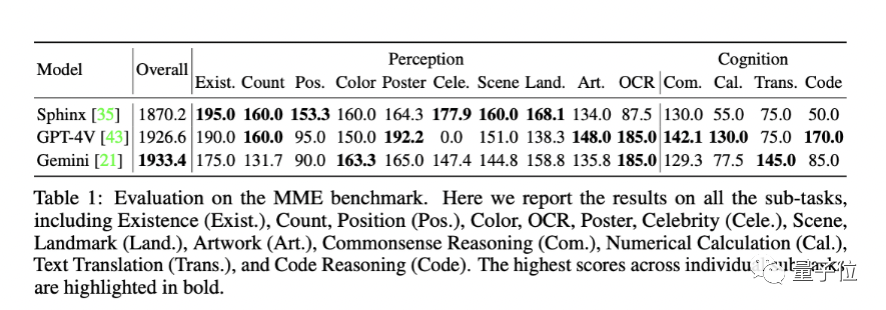
具体来看:
1、Gemini-Pro在文本翻译、颜色/地标/人物识别、OCR等任务中表现突出;
2、GPT-4V在名人识别任务上的得分为0,主要是因为拒绝回答名人相关的问题;
3、无论是Gemini还是GPT-4V在位置识别任务上表现都不佳,表明他们对空间位置信息不敏感;
4、开源模型SPHINX在感知任务上与GPT-4V以及Gemini平齐甚至更优,但认知和两者有较大差距。
下面就是四大项任务上的定性结果了。
基础感知
感知能力直接影响模型在高阶任务中的能力,因为它决定了模型获取和处理原始视觉输入的准确性和有效性。
报告中分别测试了模型的对象级感知能力、场景级感知能力和基于知识的感知能力。
具体一共10个细分任务:

鉴于篇幅有限,我们在此只展示其中5个:
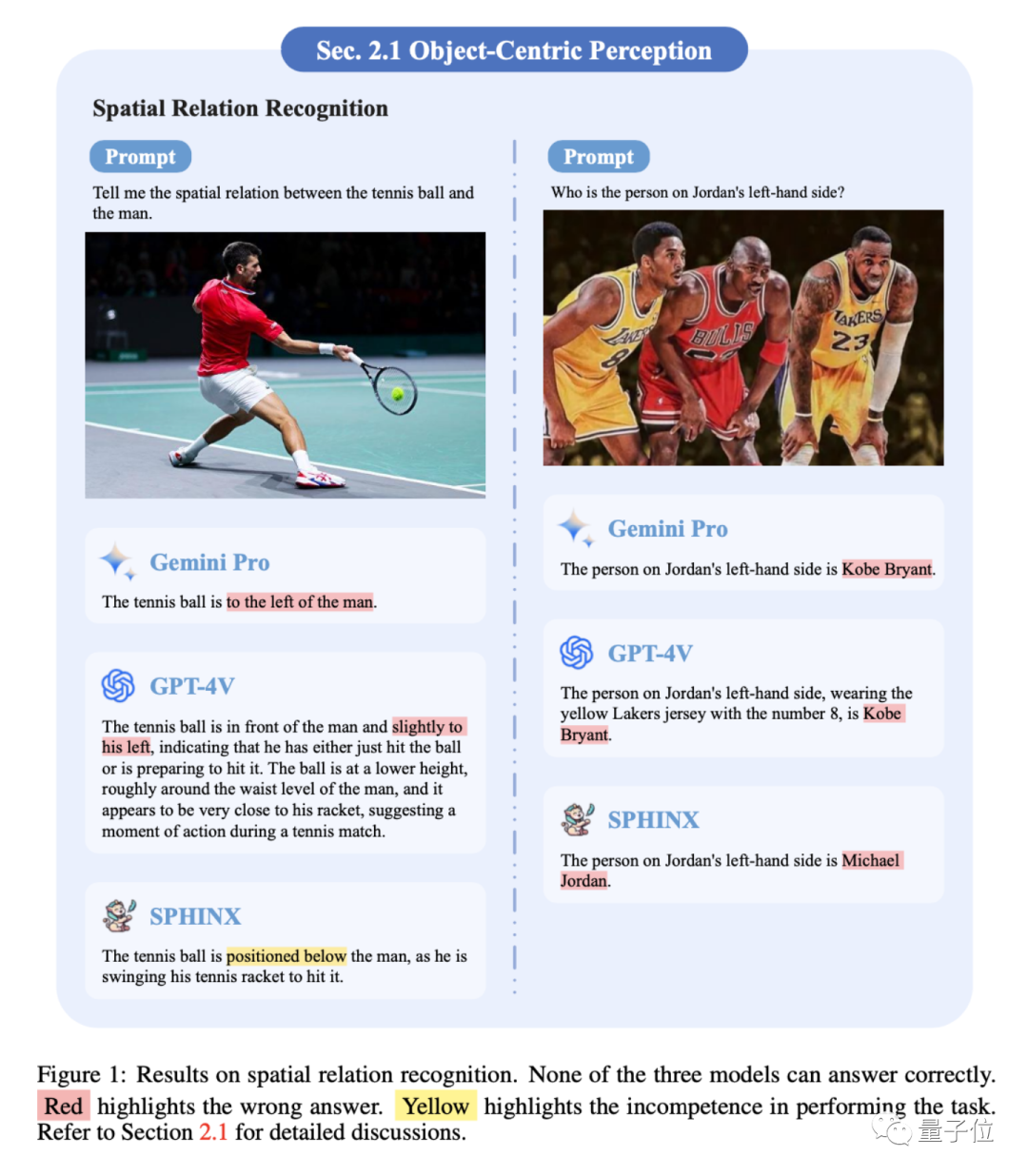
1、空间关系
都不分左右。但GPT-4V可以通过上下文少样本学习这项任务,然后做出正确回答。
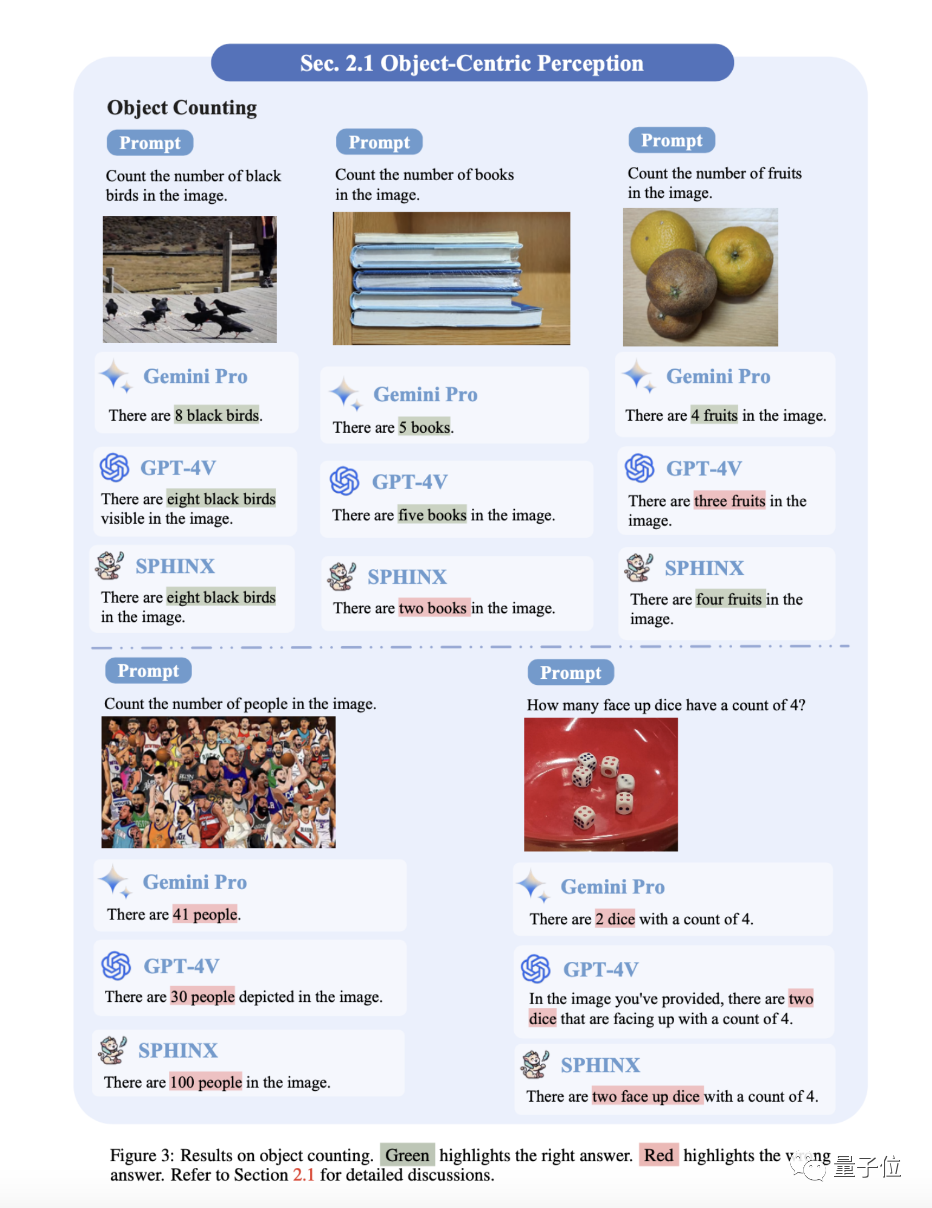
2、物体计数
简单样例整体还OK,但复杂一点的全军覆没。不过在数NBA篮球运动员时,Gemini-Pro的答案已经相当接近了(正确为42个)。
3、视觉错觉
左侧样例中,两个梨实际上具有相同的亮度。Gemini Pro正确识别,而GPT-4V和SPHNIX被欺骗。

4、场景理解
模型都能够描绘场景中的关键视觉元素。相比之下,GPT-4V显示出优越的性能,描述更加详细,并且幻觉的实例也更少。

5、视频场景理解
从视频中抽取三个时刻的关键帧,Gemini Pro能够将不同帧的信息整合成一个连贯的场景描述。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

