

股价飙升150%走出市值暴跌
文章来源:机器之心
MIT、微软联合研究:不需要额外训练,也能增强大语言模型的任务性能并降低其大小。

图片来源:由无界 AI生成
在大模型时代,Transformer 凭一己之力撑起了整个科研领域。自发布以来,基于 Transformer 的 LLM 在各种任务上表现出卓越的性能,其底层的 Transformer 架构已成为自然语言建模和推理的最先进技术,并在计算机视觉和强化学习等领域显示出强有力的前景。
然而,当前 Transformer 架构非常庞大,通常需要大量计算资源来进行训练和推理。
这是有意为之的,因为经过更多参数或数据训练的 Transformer 显然比其他模型更有能力。尽管如此,越来越多的工作表明,基于 Transformer 的模型以及神经网络不需要所有拟合参数来保留其学到的假设。
一般来讲,在训练模型时大规模过度参数化似乎很有帮助,但这些模型可以在推理之前进行大幅剪枝;有研究表明神经网络通常可以去除 90% 以上的权重,而性能不会出现任何显著下降。这种现象促使研究者开始转向有助于模型推理的剪枝策略研究。
来自 MIT、微软的研究者在论文《 The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction 》中提出了一个令人惊讶的发现,即在 Transformer 模型的特定层上进行仔细的剪枝可以显著提高模型在某些任务的性能。

该研究将这种简单的干预措施称之为 LASER( LAyer SElective Rank reduction ,层选择性降秩),通过奇异值分解来选择性地减少 Transformer 模型中特定层的学习权重矩阵的高阶分量,从而显著提高 LLM 的性能,这种操作可以在模型训练完成后进行,并且不需要额外的参数或数据。
操作过程中,权重的减少是在模型特定权重矩阵和层中执行的,该研究还发现许多类似矩阵都可以显著减少权重,并且在完全删除 90% 以上的组件之前通常不会观察到性能下降。
该研究还发现这些减少可以显著提高准确率,这一发现似乎不仅限于自然语言,在强化学习中也发现了性能提升。
此外,该研究尝试推断出高阶组件中存储的内容是什么,以便进行删除从而提高性能。该研究发现经过 LASER 回答正确的问题,但在干预之前,原始模型主要用高频词 (如 “the”、“of” 等) 来回应,这些词甚至与正确答案的语义类型都不相同,也就是说这些成分在未经干预的情况下会导致模型生成一些不相干的高频词汇。
然而,通过进行一定程度的降秩后,模型的回答可以转变为正确的。
为了理解这一点,该研究还探索了其余组件各自编码的内容,他们仅使用其高阶奇异向量来近似权重矩阵。结果发现这些组件描述了与正确答案相同语义类别的不同响应或通用高频词。
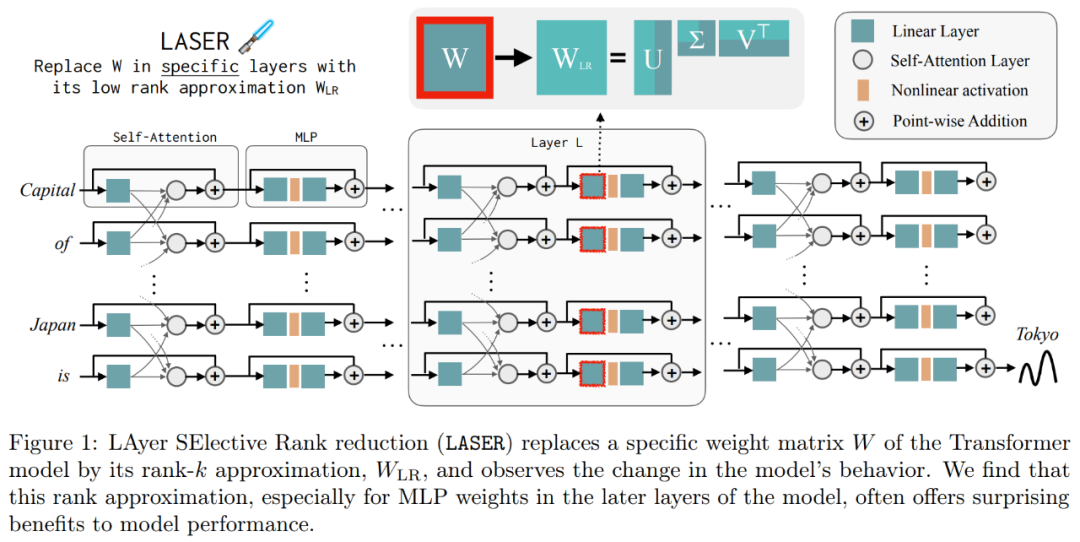
这些结果表明,当嘈杂的高阶分量与低阶分量组合时,它们相互冲突的响应会产生一种平均答案,这可能是不正确的。图 1 直观地展示了 Transformer 架构和 LASER 遵循的程序。在这里,特定层的多层感知器(MLP)的权重矩阵被替换为其低秩近似。
研究者详细介绍了 LASER 干预。单步 LASER 干预由包含参数 τ、层数ℓ和降秩 ρ 的三元组 (τ, ℓ, ρ) 定义。这些值共同描述了哪个矩阵会被它们的低秩近似所替代以及近似的严格程度。研究者依赖参数类型对他们将要干预的矩阵类型进行分类。
研究者重点关注 W = {W_q, W_k, W_v, W_o, U_in, U_out} 中的矩阵,它由 MLP 和注意力层中的矩阵组成。层数表示了研究者干预的层(第一层从 0 开始索引)。例如 Llama-2 有 32 层,因此 ℓ ∈ {0, 1, 2,・・・31}。
最终,ρ ∈ [0, 1) 描述了在做低秩近似时应该保留最大秩的哪一部分。例如设
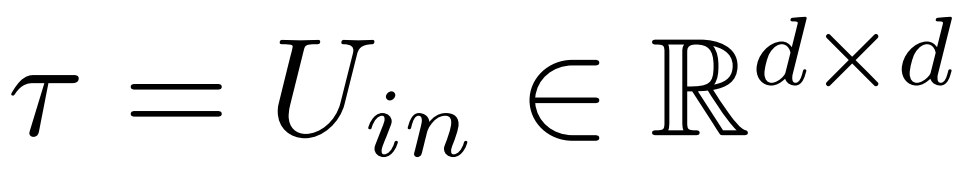
则该矩阵的最大秩为 d。研究者将它替换为⌊ρ・d⌋- 近似。
下图 1 为 LASER 示例,该图中,τ = U_in 和ℓ = L 表示在 L^th 层的 Transformer 块中来更新 MLP 第一层的权重矩阵。另一个参数控制 rank-k 近似中的 k。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

