

一秒100张实时生成二次元
这是为数不多深入比较使用消费级 GPU(RTX 3090、4090)和服务器显卡(A800)进行大模型预训练、微调和推理的论文。
原文来源:机器之心

图片来源:由无界 AI生成
大型语言模型 (LLM) 在学界和业界都取得了巨大的进展。但训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的开源框架和方法。然而,不同硬件和软件堆栈的运行时性能可能存在很大差异,这使得选择最佳配置变得困难。
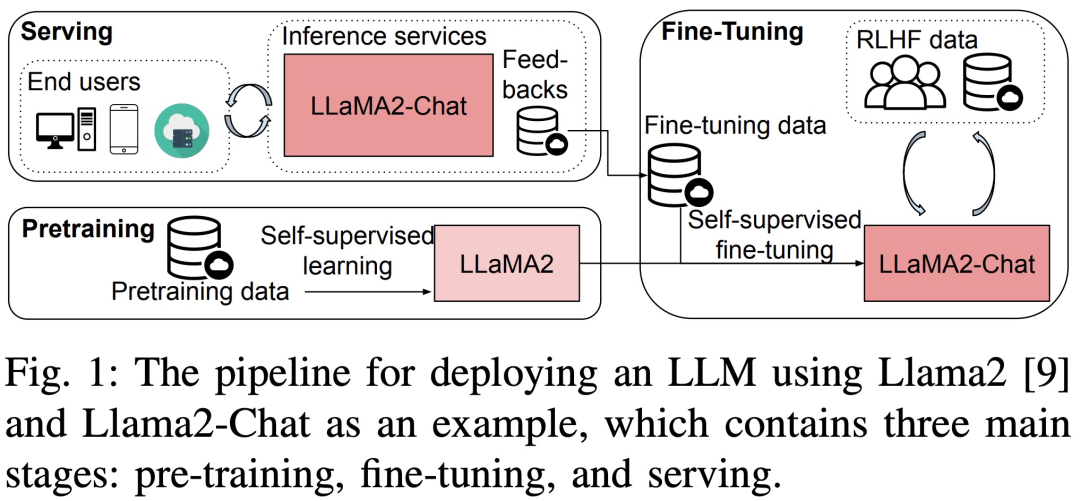
最近,一篇题为《Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models》的新论文从宏观和微观的角度详细分析了 LLM 训练、微调、推理的运行时性能。

论文地址:https://arxiv.org/pdf/2311.03687.pdf
具体来说,该研究首先在三个 8-GPU 上对不同规模(7B、13B 和 70B 参数)的 LLM,面向预训练、微调、服务进行端到端的性能基准测试,涉及具有或不具有单独优化技术的平台,包括 ZeRO、量化、重新计算、FlashAttention。然后,该研究进一步提供了子模块的详细运行时分析,包括 LLM 中的计算和通信运算符。
方法介绍
该研究的基准测试采用自上而下的方法,涵盖 Llama2 在三个 8-GPU 硬件平台上的端到端步骤时间性能、模块级时间性能和运算符时间性能,如图 3 所示。
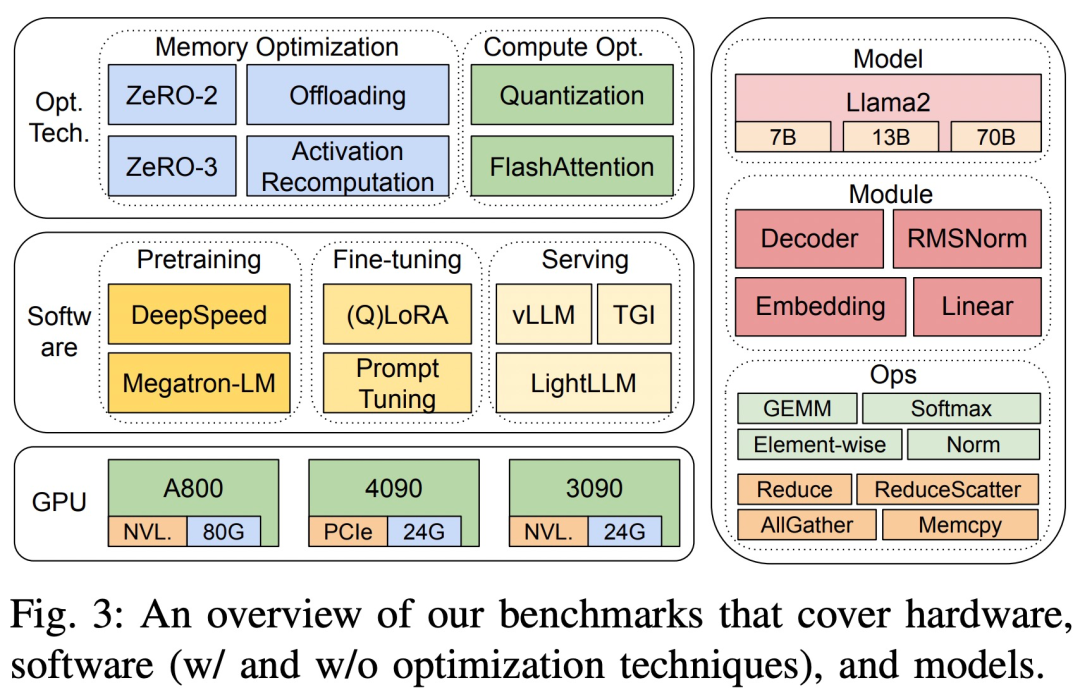
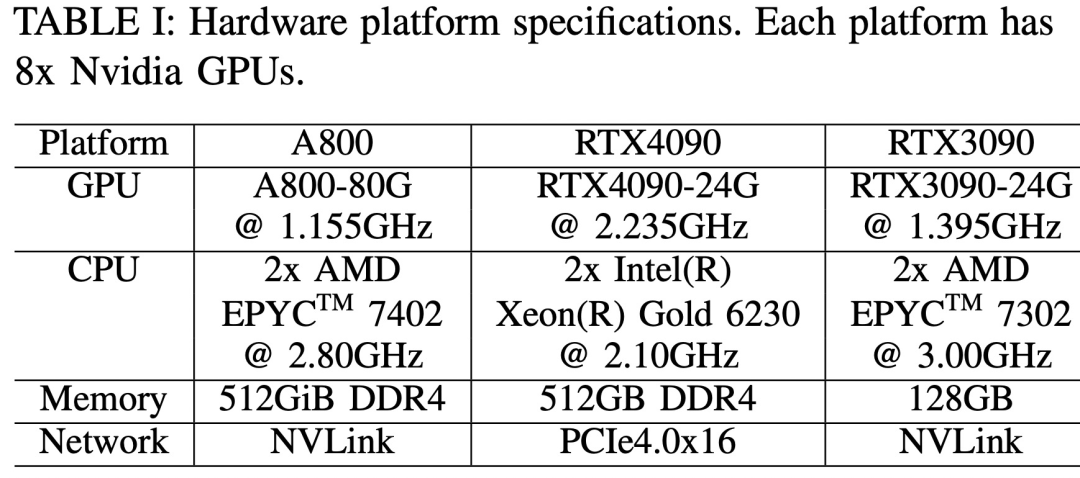
三个硬件平台分别为 RTX4090、RTX3090 和 A800,具体规格参数如下表 1 所示。
在软件方面,该研究比较了 DeepSpeed 和 Megatron-LM 在预训练和微调方面的端到端步骤时间。为了评估优化技术,该研究使用 DeepSpeed 逐一启用如下优化:ZeRO-2、ZeRO-3、offloading、激活重计算、量化和 FlashAttention,以衡量性能改进以及时间和内存消耗方面的下降。
在 LLM 服务方面,存在三个高度优化的系统,vLLM、LightLLM 和 TGI,该研究在三个测试平台上比较了它们的性能(延迟和吞吐量)。
为了保证结果的准确性和可重复性,该研究计算了 LLM 常用数据集 alpaca 的指令、输入和输出的平均长度,即每个样本 350 个 token,并随机生成字符串以达到 350 的序列长度。
在推理服务中,为了综合利用计算资源并评估框架的鲁棒性和效率,所有请求都以突发模式调度。实验数据集由 1000 个合成句子组成,每个句子包含 512 个输入token。该研究在同一 GPU 平台上的所有实验中始终保持「最大生成 token 长度」参数,以保证结果的一致性和可比性。
端到端性能
该研究通过预训练、微调和推理不同尺寸 Llama2 模型(7B、13B 和 70B)的步骤时间、吞吐量和内存消耗等指标,来衡量在三个测试平台上的端到端性能。同时评估了三个广泛使用的推理服务系统:TGI、vLLM 和 LightLLM,并重点关注了延迟、吞吐量和内存消耗等指标。
模块级性能
LLM 通常由一系列模块(或层)组成,这些模块可能具有独特的计算和通信特性。例如,构成 Llama2 模型的关键模块是 Embedding、LlamaDecoderLayer、Linear、SiLUActivation 和 LlamaRMSNorm。
预训练结果
在预训练实验环节,研究者首先分析了三个测试平台上不同尺寸模型(7B、13B 和 70B)的预训练性能(迭代时间或吞吐量、内存消耗),然后进行了模块和操作层面的微基准测试。
端到端性能
研究者首先进行实验来比较 Megatron-LM 和 DeepSpeed 的性能,二者在 A800- 80GB 服务器上预训练 Llama2-7B 时没有使用任何内存优化技术(比如 ZeRO)。
他们使用的序列长度为 350,并为 Megatron-LM 和 DeepSpeed 提供了两组批大小,从 1 到最大批大小。结果如下表 II 所示,以训练吞吐量(tokens / 秒)和消费级 GPU 内存(单位 GB)为基准。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier
,一种基于")
