

ChatGPT变笨新解释:世界被
机器人是一种拥有无尽可能性的技术,尤其是当搭配了智能技术时。近段时间创造了许多变革性应用的大模型有望成为机器人的智慧大脑,帮助机器人感知和理解这个世界并制定决策和进行规划。近日,CMU 的 Yonatan Bisk 和 Google DeepMind 的夏斐(Fei Xia)领导的一个联合团队发布了一篇综述报告,介绍了基础模型在机器人领域的应用和发展情况。
原文来源:机器之心

图片来源:由无界 AI生成
开发能自主适应不同环境的机器人是人类一直以来的一个梦想,但这却是一条漫长且充满挑战的道路。
之前,利用传统深度学习方法的机器人感知系统通常需要大量有标注数据来训练监督学习模型,而如果通过众包方式来标注大型数据集,成本又非常高。
此外,由于经典监督学习方法的泛化能力有限,为了将这些模型部署到具体的场景或任务,这些训练得到的模型通常还需要精心设计的领域适应技术,而这又通常需要进一步的数据收集和标注步骤。类似地,经典的机器人规划和控制方法通常需要仔细地建模世界、智能体自身的动态和 / 或其它智能体的动态。这些模型通常针对各个具体环境或任务构建,而当情况有变时,就需要重新构建模型。这说明经典模型的迁移性能也有限。
事实上,对于很多用例,构建有效模型的成本要么太高,要么完全无法办到。尽管基于深度(强化)学习的运动规划和控制方法有助于缓解这些问题,但它们仍旧会受到分布移位(distribution shift)和泛化能力降低的影响。
虽然在开发通用型机器人系统上正面临诸多挑战,但自然语言处理(NLP)和计算机视觉(CV)领域近来却进展迅猛,其中包括用于 NLP 的大型语言模型(LLM)、用于高保真图像生成的扩散模型、用于零样本 / 少样本生成等 CV 任务的能力强大的视觉模型和视觉语言模型。
所谓的「基础模型(foundation model)」其实就是大型预训练模型(LPTM)。它们具备强大的视觉和语言能力。近来这些模型也已经在机器人领域得到应用,并有望赋予机器人系统开放世界感知、任务规划甚至运动控制能力。除了将现有的视觉和 / 或语言基础模型用于机器人领域,也有研究团队正针对机器人任务开发基础模型,比如用于操控的动作模型或用于导航的运动规划模型。这些机器人基础模型展现出了强大的泛化能力,能适应不同的任务甚至具身方案。
也有研究者直接将视觉 / 语言基础模型用于机器人任务,这展现出了将不同机器人模块融合成单一统一模型的可能性。
尽管视觉和语言基础模型在机器人领域前景可期,全新的机器人基础模型也正在开发中,但机器人领域仍有许多挑战难以解决。
从实际部署角度看,模型往往是不可复现的,无法泛化到不同的机器人形态(多具身泛化)或难以准确理解环境中的哪些行为是可行的(或可接受的)。此外大多数研究使用的都是基于 Transformer 的架构,关注的重点是对物体和场景的语义感知、任务层面的规划、控制。而机器人系统的其它部分则少有人研究,比如针对世界动态的基础模型或可以执行符号推理的基础模型。这些都需要跨领域泛化能力。
最后,我们也需要更多大型真实世界数据以及支持多样化机器人任务的高保真度模拟器。
这篇综述论文总结了机器人领域使用的基础模型,目标是理解基础模型能以怎样的方式帮助解决或缓解机器人领域的核心挑战。

论文地址:https://arxiv.org/pdf/2312.08782.pdf
在这篇综述中,研究者使用的「用于机器人的基础模型(foundation models for robotics)」这一术语涵盖两个方面:(1) 用于机器人的现有的(主要)视觉和语言模型,主要是通过零样本和上下文学习;(2) 使用机器人生成的数据专门开发和利用机器人基础模型,以解决机器人任务。他们总结了用于机器人的基础模型的相关论文中的方法,并对这些论文的实验结果进行了元分析(meta-analysis)。
图 1 展示了这篇综述报告的主要组成部分。
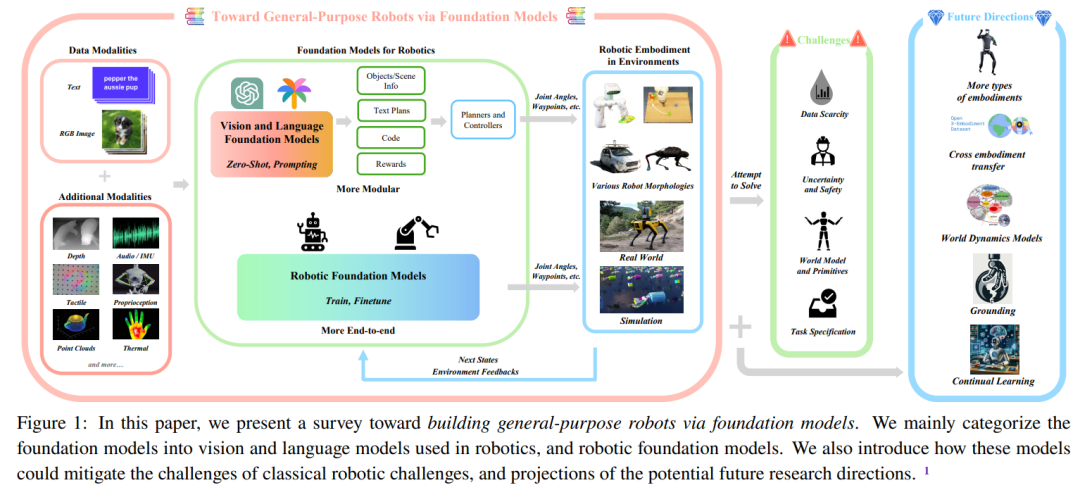
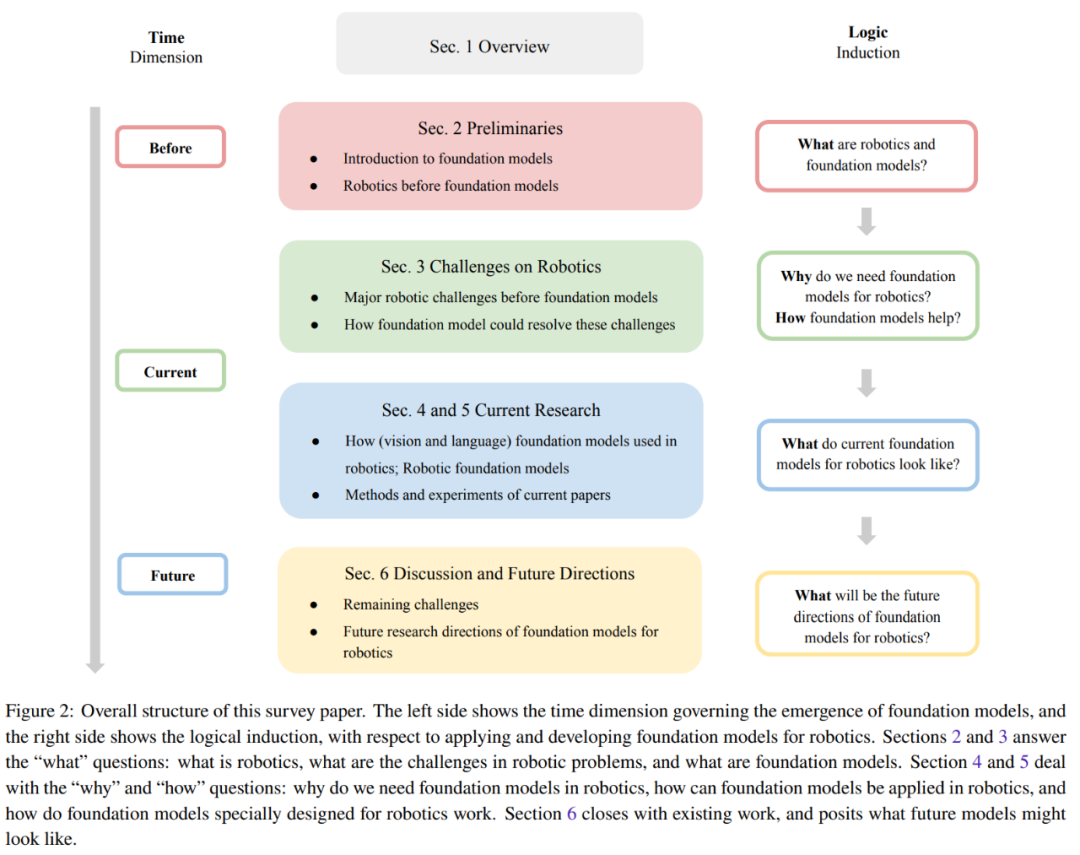
图 2 给出了这篇综述的整体结构。
预备知识
为了帮助读者更好地理解这篇综述的内容,该团队首先给出了一节预备知识内容。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

