

阿里推AI工具不停,这次
来源:新智元

图片来源:由无界 AI生成
大模型固有的幻觉问题严重影响了LLM的表现。斯坦福最新研究利用维基百科数据训练大模型,得到的WikiChat成为首个几乎不产生幻觉的聊天机器人。
大语言模型的幻觉问题被解决了!
近日,来自斯坦福的研究人员发布了WikiChat——被称为首个几乎不产生幻觉的聊天机器人!
论文发表在EMNLP 2023,并且在Github上开源了代码:

论文地址:https://aclanthology.org/2023.findings-emnlp.157.pdf
项目代码:https://github.com/stanford-oval/WikiChat
作者表示自己的最佳模型在新的基准测试中获得了97.3%的事实准确性,而相比之下,GPT-4的得分仅为66.1%。
在「recent」和「tail」两个知识子集中,这个差距甚至更大。
另外,作者还发现了检索增强生成(RAG)的几个缺点,并添加了几个重要步骤,以进一步减轻幻觉,并改进「对话性」指标。
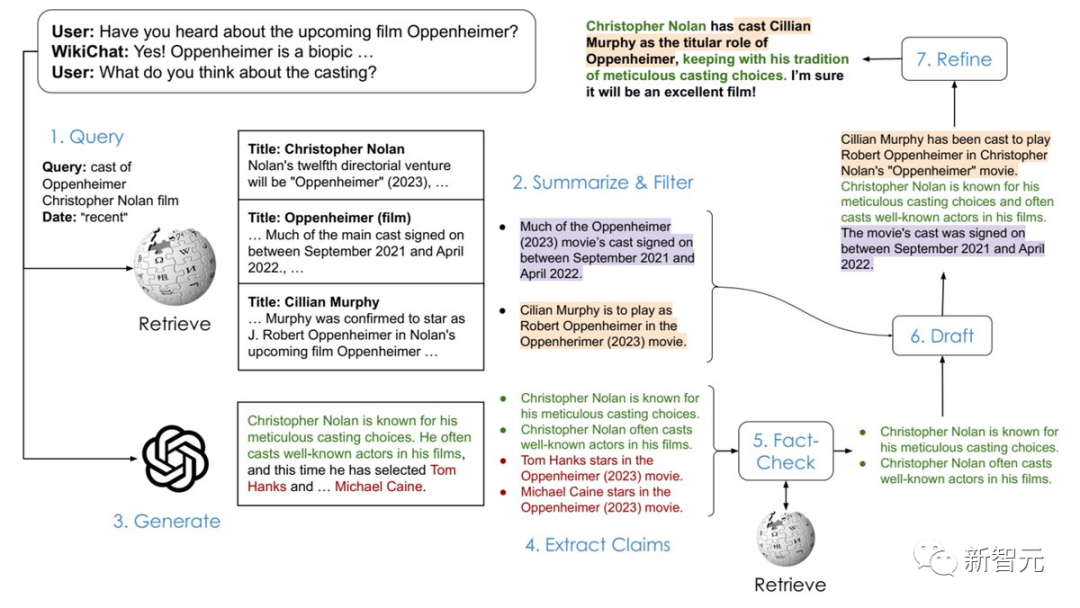
通过这些优化,WikiChat在事实性方面比微调后的SOTA RAG模型Atlas高出8.5%,
在相关性、信息性、自然性、非重复性和时间正确性方面也大大领先。
最后,作者将基于GPT-4的WikiChat提炼成7B参数的LLaMA,这个模型在事实准确性方面仍然能拿到91.1%的高分,
并且运行速度提高了6.5倍,能效更好,可以本地部署。
大模型+维基百科,一起击败幻觉
众所周知,LLM的幻觉问题由来已久、根深蒂固,
而且曾给各家的大语言模型都造成过不同程度的影响。
基于LLM使用概率来推断输出的原理,幻觉这个问题很难彻底解决,
研究人员们为此投入大量的心血,小编也是很期待这个WikiChat的表现!
WikiChat,顾名思义,就是基于维基百科的知识进行训练,听起来还挺靠谱的。
除了论文和代码,研究团队还部署了可以直接对话的demo供大家测试,好文明!

Demo地址:https://wikichat.genie.stanford.edu/
于是小编迫不及待地要试一试WikiChat的实力。
WikiChat首先进行了自我介绍,表示自己会记录对话用于研究,
另外,WikiChat有以下三种模式:

默认状态是平衡输出速度和准确性,我们可以在右边的设置中调节。
WikiChat还额外添加了TTS功能,输出是个温柔的女声。
好了,让我们赶紧「Ask her about anything on Wikipedia」!
——开个玩笑,既然你不会中文,那小编这点英文水平,只能献丑了......
(注意上面的这句中文不要点击语音输出,有可能导致整个聊天卡住无法恢复)
下面,我们首先问一个常识性问题:Sam Altman是OpenAI的CEO吗?

其实小编想测试她知不知道Altman被开除,然后又王者归来这件事,
不过这一句「在2020年离开YC,全职加入OpenAI」,貌似就有事实性的错误。
小编接下来使用游戏信息进行测试:介绍一下「原神」中的「宵宫」。

这个回答确实没什么问题,卡池时间和配音演员也正确,
既然提到了配音演员,那顺便问一下中文CV是谁:

免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

