

告别FUD:2024 年以太坊路线
来源:机器之心
现在大模型都学会借力了。

图片来源:由无界 AI生成
琳琅满目的乐高积木,通过一块又一块的叠加,可以创造出各种栩栩如生的人物、景观等,不同的乐高作品相互组合,又能为爱好者带来新的创意。
我们把思路打开一点,在大模型(LLM)爆发的当下,我们能不能像拼积木一样,把不同的模型搭建起来,而不会影响原来模型的功能,还能起到 1+1>2 的效果。
这样的想法,谷歌已经实现了。他们的研究为未来的语言模型发展提供了一个新的方向,特别是在资源节约和模型适应性方面。

如今的大语言模型(LLM)仿佛一个全能战士,能进行常识和事实推理、懂得世界知识、生成连贯的文本…… 在这些基础功能的底座上,研究者们又进行了一系列努力对这些模型进行微调,以实现特定于领域的功能,如代码生成、文案编辑以及解决数学问题等。
但这些特定于领域的模型开始出现一些棘手的问题,例如,有些模型在标准代码生成方面做得很好,但在一般逻辑推理方面并不精通,反之亦然。
我们不禁要问:是否可以将 anchor 模型(即具有基础功能的模型)与特定于领域的增强模型组合在一起,从而开启模型新功能?例如,我们能否将理解代码的增强模型与 anchor 模型的语言生成能力组合起来,以实现从代码 - 文本的生成能力?
在此之前,该问题典型的解决方案是在最初用于训练增强模型的数据上进行进一步的预训练或微调 anchor 模型。然而,很多时候这样的解决方案是不可行的,因为训练大模型的计算成本很高。此外,由于数据隐私等问题,处理来自多个来源的数据可能不可行。
为了解决上述训练成本和数据带来的挑战,谷歌提出并研究了进行模型组合的实际设置,这些设置包括:(i)研究者可以访问一个或多个增强模型和 anchor 模型,(ii)不允许修改任一模型的权重,并且(iii)只能访问少量数据,这些数据代表了给定模型的组合技能。

论文地址:https://arxiv.org/pdf/2401.02412.pdf
该研究是这样实现的,他们提出了一种新颖的 CALM(组合到增强语言模型 Composition to Augment Language Models)框架来解决模型组合设置。CALM 不是增强和 anchor LM 的浅层组合,而是在增强和 anchor 模型的中间层表示上引入了少量的可训练参数。
这种方法不仅资源高效,只需增加少量额外的参数和数据,就能扩展到新任务上,比完全重新训练模型要经济得多。而且比单独使用一个模型能够更准确地执行新的挑战性任务,同时还能保留各个模型的功能。CALM 对特定任务和低资源语言也提供了更好的支持。
这种通过组合方式扩展模型功能的创新得到了很多人的好评:
「这项研究以及类似的 MoE 研究真的很令人惊讶。像堆乐高积木一样把模型拼在一起就行了!」

还有人表示:「我们离 AI 奇点又近了一步!」

对于给定的 anchor 模型 m_B 和增强模型 m_A,CALM 旨在将这两种模型结合起来,组成 m_(A⊕B),使得新模型的能力成为两个独立模型能力的组合。
研究过程中,开发人员做了以下假设:i)他们可以访问模型的权重,向前、向后传播,并有权限访问 m_B 和 m_A 的中间表示,ii)不允许更改两个模型的权重,iii)研究者无法访问两个基本模型的训练数据、超参数、训练状态,iv)研究者能提供来自目标组合域的一些示例。
在上述假设下,该研究的目标是学习组合
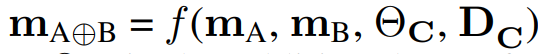
以实现某些联合任务 C。其中 m_B 和 m_A 的权重被冻结,θ_C 是为学习组合而引入的附加可训练参数集,D_C 是指用于学习该组合的示例集。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

