

高通CEO:生成式AI正在“非
原文来源:量子位

图片来源:由无界 AI生成
22倍加速还不够,再来提升46%,而且方法直接开源!
这就是开源社区改进MIT爆火项目StreamingLLM的最新成果。

StreamingLLM可以在不牺牲生成效果、推理速度的前提下,实现多轮对话共400万个token,22.2倍推理速度提升。
该项目在上线不到3个月时间内,GitHub项目标星达到5.7k star。
不过,StreamingLLM使用原生PyTorch实现,对于多轮对话推理场景落地应用的低成本、低延迟、高吞吐等需求仍有优化空间。
Colossal-AI团队开源了SwiftInfer,基于TensorRT的StreamingLLM,可以进一步提升大模型推理性能46%,有效解决如上问题。
具体如何实现?一起来看。
开源地址:https://github.com/hpcaitech/SwiftInfer
StreamingLLM如何实现超长多轮对话?
大语言模型能够记住的上下文长度,直接影响了ChatGPT等大模型应用与用户互动的质量。
如何让LLM在多轮对话场景下保持生成质量,对推理系统提出了更高的要求,因为LLM在预训练期间只能在有限的注意力窗口的限制下进行训练。
常见的KV Cache机制能够节约模型计算的时间,但是在多轮对话的情景下,key和value的缓存会消耗大量的内存,无法在有限的显存下无限扩展上下文。
同时,训练好的模型在不做二次微调的前提下也无法很好地泛化到比训练序列长度更长的文本,导致生成效果糟糕。
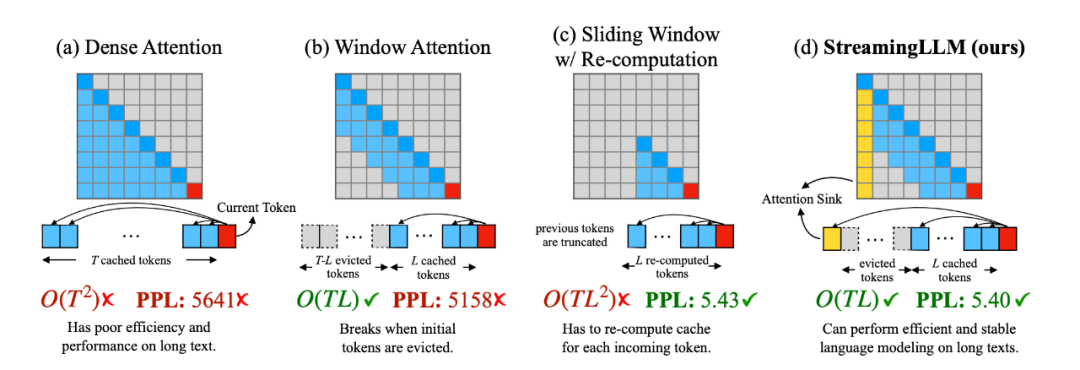
StreamingLLM为了解决了这个问题,通过观察了注意力模块中Softmax的输出,发现了attention sink的现象。
要知道,注意力机制会为每一个token分配一个注意力值,而文本最初的几个token总是会分配到很多无用的注意力。
当使用基于滑动窗口的注意力机制时,一旦这几个token被踢出了窗口,模型的生成效果就会迅速崩溃。
只要一直把这几个token保留在窗口内,模型就能稳定地生成出高质量的文本。
比起密集注意力(Dense Attention)、窗口注意力(Window Attention)以及带重计算的滑动窗口注意力(Sliding Window w/ Re-computing),StreamingLLM基于attention sink的注意力机制无论是在计算复杂度还是生成效果上都表现优异。
在不需要重新训练模型的前提下,StreamingLLM能够直接兼容目前的主流大语言模型并改善推理性能。
SwiftInfer如何升级StreamingLLM?
Colossal-AI团队的方法是,将StreamingLLM方法与TensorRT推理优化结合。
这样的好处是,不仅能继承原始StreamingLLM的所有优点,还具有更高的运行效率。
使用TensorRT-LLM的API,还能够获得接近于PyTorch API的模型编写体验。
具体来看,基于TensorRT-LLM可以重新实现KV Cache机制以及带有位置偏移的注意力模块。
如下图所示,假设窗口大小为10个token,随着生成的token增加(由黄色方块表示),在KV缓存中将中间的token踢出,与此同时,始终保持着文本开始的几个token(由蓝色方块表示)。
由于黄色方块的位置会发生变化,在计算注意力时,也需要重新注入位置信息。
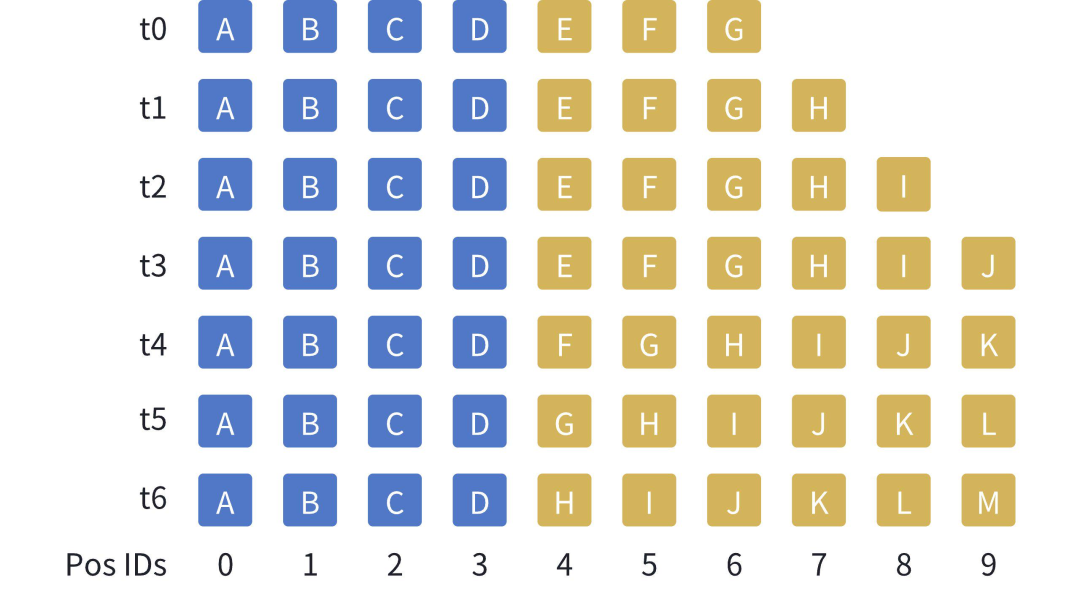
需要注意的是,StreamingLLM不会直接提高模型能访问的上下文窗口,而是能够在支持流式超多轮对话的同时保证模型的生成效果。
经过升级后,在原版本StreamingLLM基础上,Colossal-AI团队发布的SwiftInfer可带来额外的最多46%的推理吞吐速度提升。
能为大模型多轮对话推理提供低成本、低延迟、高吞吐的最佳实践。TensorRT-LLM团队也在同期对StreamingLLM进行了类似支持。

团队刚开源13B大模型
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

